

nltk库安装及nltk_data模型国内网络下载安装 最新教程
NLTK是一个相等流行的自然语言处理工具包,它是一个python工具包,为我们处理人类自然语言数据提供了丰富的函数和接口,常用于文本处理、标记、分析和语言建模。
nltk的包安装也是非常简单,我们只需要:
pip install nltk
如果你因为再国内无法连接到官网的话,可以采用镜像源安装的方式,以清华大学的镜像源安装为例:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple nltk
安装完成后我们可以试着写一个简单的小例子来测试,代码如下:
import nltk from nltk import FreqDist from nltk.corpus import reuters # 从reuters语料库中获取单词列表 words = reuters.words() # 创建词频统计 fdist = FreqDist(words) # 输出前20个最常见的词和它们的词频 print(fdist.most_common(20))
然后你运行的话,可能会出现如下错误:
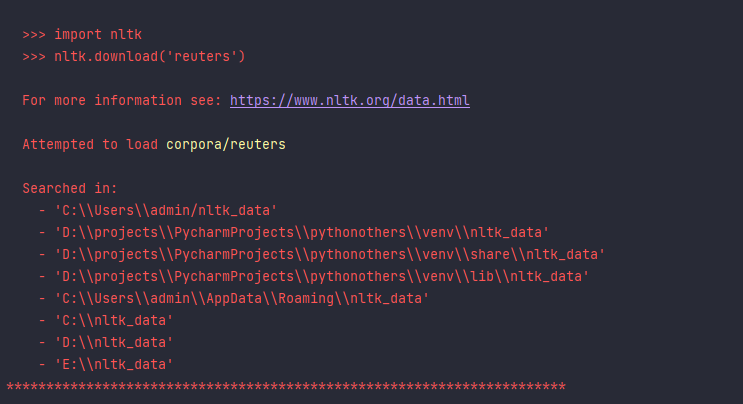
nltk找不到nltk_data
这个错误的原因是因为你虽然安装了nltk这个库,但是却没有安装它的模型、资源和插件之类的,导致调用的时候出现错误。解决的办法也很简单,执行如下代码可以打开下载器:
import nltk # 下载reuters语料库 nltk.download()
执行后会打开如下窗口:
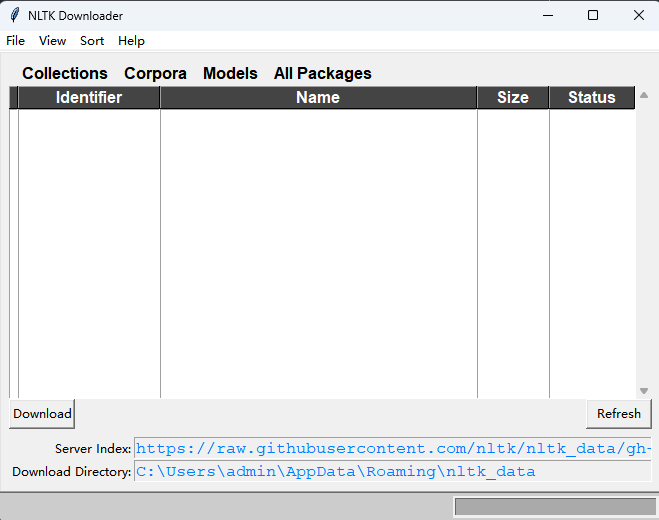
什么?你打开是空白的?下载不了?下载不了就对了,因为我也打不开,国内的网络无法访问到官方服务器进行下载,所以我们要换一种方法进行下载,为了方便小朋友们使用,我已经把打包好的资源包放到云盘了,欢迎下载使用。
下载链接再文章末尾,下载完以后,解压后复制到上面报错的任何一个目录里,一般是放在当前登录账号的目录,这在windows、mac、linux里通用,在windows下,你还可以放到任何一个盘符的根目录下,如图:
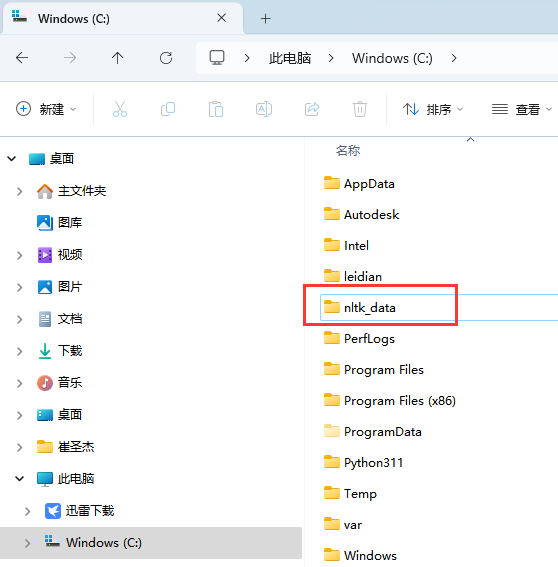
资源包放置完以后,我们再执行上面的代码:
import nltk from nltk import FreqDist from nltk.corpus import reuters # 从reuters语料库中获取单词列表 words = reuters.words() # 创建词频统计 fdist = FreqDist(words) # 输出前20个最常见的词和它们的词频 print(fdist.most_common(20))
你会发现结果出来了!

文件下载链接为:
https://www.cuishengjie.com/983.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号