

江洁兰---第二次作业
| 这个作业属于哪个课程 | 至诚软工实践F班 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzzcxy/ZhichengSoftengineeringPracticeFclass/homework/12532 |
| 这个作业的目标 | 学会初步使用fiddler结合编程语言爬取目标数据,进一步熟练使用git |
| Github 地址 | https://github.com/greenye-1/212106715-1/tree/master |
一、 任务内容:
【必做】基础:使用 fiddler 抓包工具+代码,实时监控朴朴上某产品的详细价格信息
二、解题思路描述
-
了解了作业内容后,我首先做的是了解fiddler是什么和怎么用,网上能找到的教程不少,让我对这个有了一定的了解。本着走一步做一步的想法,我想这先用fiddler抓取到数据再考虑后面的任务,没想到过程很是曲折。
-
能爬到数据后,我就考虑怎么用代码输出相关数据了,对比找到的java和python资料后,我选择用python来实现。由此我学习了菜鸟教程上python的基础知识,结合网上查到的资料和舍友的讲解,按着任务要求,我也慢慢将代码部分实现了。
三、设计实现过程
1.数据爬取
- 安装好fiddler后,跟着教程一步一步设置好fiddler
- 让电脑设备和平板(尝试过手机和模拟器,无果)连同一个热点,设置代理和安装证书
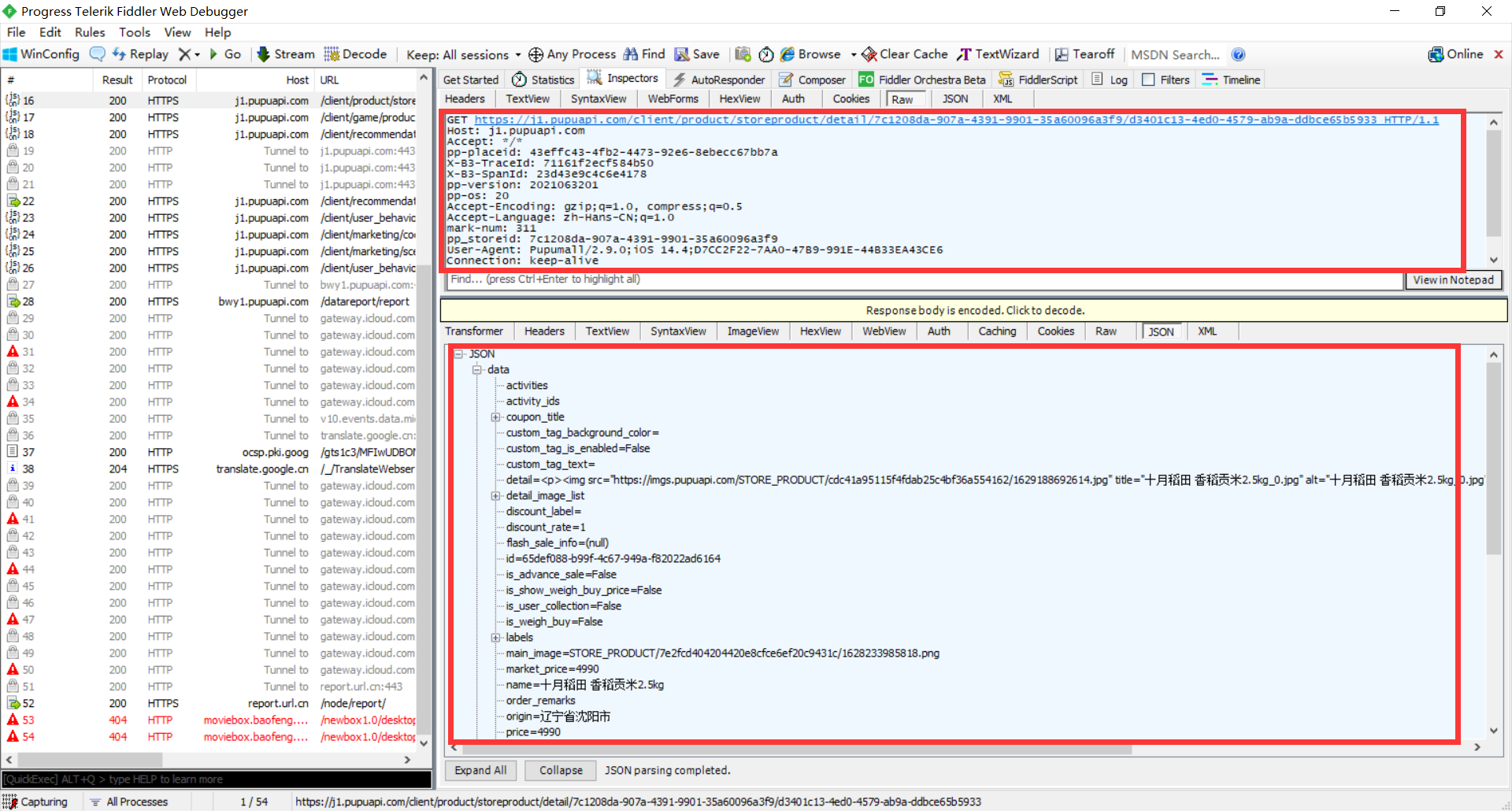
- 打开朴朴app,在fiddler上找到目标json数据,分析数据
- 实行过程:尝试过fiddler结合手机或模拟器来爬取app的数据,以及安装VituralXposed和平行空间想用来解决办理代理后没有网的问题,折腾了几天,过程中这个问题有解决过,但是仍然是抓不到数据。后来办代理后又没网了,好在舍友借我ipad一用,让我终于能顺利爬到数据。
- 遇到的问题:办理代理后app可以联网,但爬不到数据,出现Tunnel to 443;办理代理后app不能联网
- 相关教程链接:https://www.cnblogs.com/zhangyangcheng/p/15218175.html
- 实现效果:

2.代码实现
-
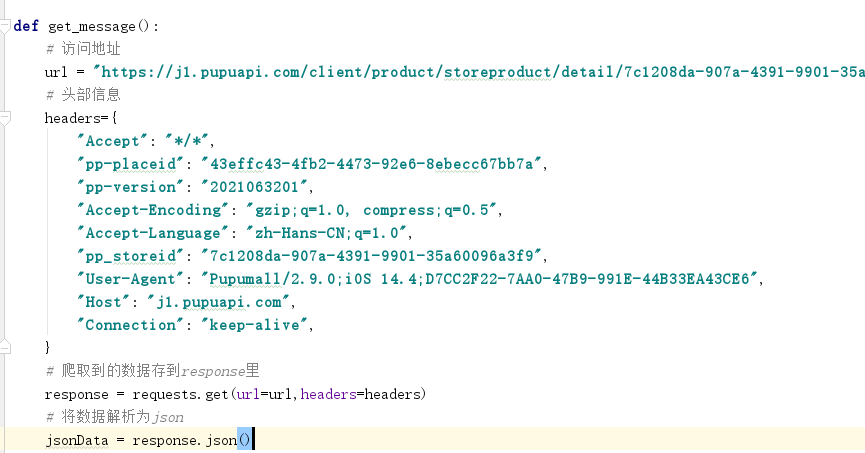
在fiddler上提取需要的头部信息,用python初步读取到数据
-
分析数据的结构,将目标数据提取出来

-
根据任务要求,参考网上资料,输出目标数据
参考链接:http://www.360doc.com/content/18/0818/19/11881101_779291475.shtml

-
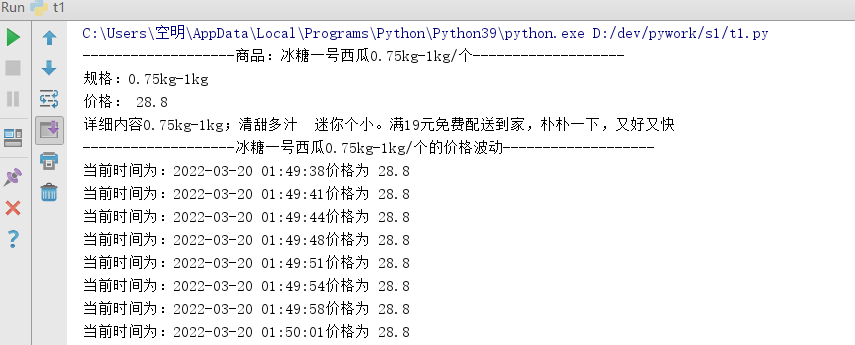
实现效果:
-
遇到的问题:
代码已经模拟爬取,仍然没有爬到数据,结果是url尾部多了一个空格,以及出现各种报错,包括Traceback (most recent call last)
参考教程链接:https://www.runoob.com/python/python-variable-types.html
3.git commit
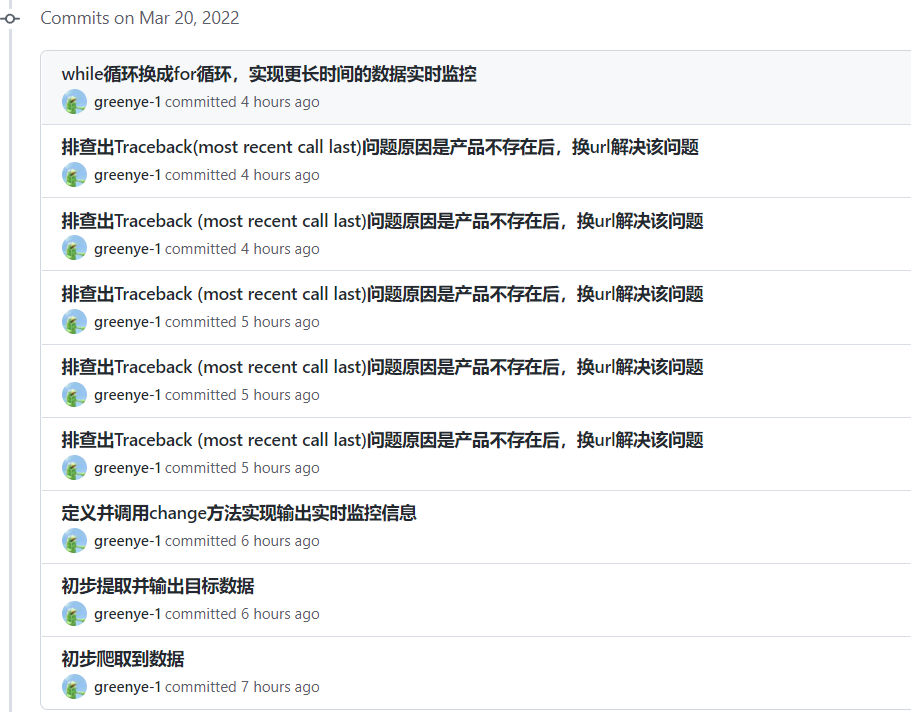
- 写代码实现过程中将代码提交到github
- 遇到的问题:
-
fatal: 'git@github.com/greenye-1/212106715-1.git' does not appear to be a git repository
fatal: Could not read from remote repository.
参考链接:https://blog.csdn.net/qq_40428678/article/details/84074207
还是没有解决,多次尝试后,考虑git@github.com:(github名)/(git项目名).git直接复制github上的,才得以解决 -
! [rejected]master -> master (fetch first) error: failed to push some refs to 'github.com:greenye-1/212106715-1.git' hint:
3.解决问题所参考链接:https://blog.csdn.net/weixin_43264399/article/details/87350219
https://www.cnblogs.com/cppeterpan/p/7289266.html
图片:
4.博客撰写
- 记录完成作业的过程,有点奇怪的是,预览效果和实际效果有出入。
四、改进思路
改进方面打算优化代码逻辑,实现长时间实时监控数据。
五、代码说明
import time
import requests
def get_message():
# 访问地址
url = "https://j1.pupuapi.com/client/product/storeproduct/detail/7c1208da-907a-4391-9901-35a60096a3f9/d3401c13-4ed0-4579-ab9a-ddbce65b5933"
# 头部信息
headers={
"Accept": "*/*",
"pp-placeid": "43effc43-4fb2-4473-92e6-8ebecc67bb7a",
"pp-version": "2021063201",
"Accept-Encoding": "gzip;q=1.0, compress;q=0.5",
"Accept-Language": "zh-Hans-CN;q=1.0",
"pp_storeid": "7c1208da-907a-4391-9901-35a60096a3f9",
"User-Agent": "Pupumall/2.9.0;iOS 14.4;D7CC2F22-7AA0-47B9-991E-44B33EA43CE6",
"Host": "j1.pupuapi.com",
"Connection": "keep-alive",
}
# 爬取到的数据存到response里
response = requests.get(url=url,headers=headers)
# 将数据解析为json
jsonData = response.json()
# 根据json格式从json中提取取需要的信息
name = jsonData['data']['name']
float = jsonData['data']['price']/100
share_content = jsonData['data']['share_content']
spec = jsonData['data']['spec']
# 返回商品名称,价格,详情,规格
return name, float, share_content, spec
# 输出商品价格变化
def change():
# 时间按2022-03-19 23:46:32格式输出
# s = 0
for a in range(10000):
time.sleep(1)
print("当前时间为:"+time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())+"价格为",get_message()[1])
# 输出商品信息
def show():
# 返回值是元组,可以通过某个返回值的序号把值取出来# name = get_message()[0] # price = get_message()[1]
print("-------------------" + "商品:" + get_message()[0] + "-------------------")
print("规格:" + get_message()[3])
print("价格:", get_message()[1])
print("详细内容" + get_message()[2])
# print("-------------------" + get_message()[0] + "的价格波动" + "-------------------")
if __name__ == '__main__':
get_message()
show()
change()
六:总结
这次作业花的时间比较多,做了有好几天,可以说一路踩着坑做完的,一直在遇到问题,解决问题,再遇到再解决,还好有舍友的大力支持,借我ipaid爬数据和帮我解决部分代码报错问题,不然难以完成作业。有点无语的是,朴朴有些商品下架太快了,作业做到一半,商品下架,就只能重新整一次爬一次数据操作,到提交作业的时候也改了几次url了。

