
Spark入门
一、Spark框架概述
1.1 spark是什么
定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。
弹性分布式数据集RDD:RDD 是一种分布式内存抽象,其使得程序员能够在大规模集群中做内存运算,并且有一定的容错方式。而这也是整个 Spark 的核心数据结构,Spark 整个平台都围绕着RDD进行。
1.2 spark的运行模式

1.3 spark的运行角色

二、本地模式环境搭建
1.上传安装包。 首先打开hadoop102号虚拟机,进入到 /opt/software 目录下上传下载好的 Miniconda3-py39_4.10.3-Linux-x86_64.sh 安装包和 spark-3.2.0-bin-hadoop3.2.tgz 压缩包。
2.安装miniconda。 执行命令: sh ./Miniconda3-py39_4.10.3-Linux-x86_64.sh 命令下载miniconda,然后按回车,出现一堆授权信息,不用看直接按空格直到出现询问是否接受授权信息,然后输入yes并回车,同意后它会继续询问你miniconda的安装位置,输入位置 /opt/software/miniconda3 并回车,等待安装,成功后会询问你是否对miniconda进行初始化,输入yes回车,出现 Thank you for installing Miniconda3! 即为安装成功!
3.创建虚拟环境。 然后咱们关闭虚拟机再重新打开虚拟机(重新打开虚拟机最好先不要连接xshell,看到base环境出现再连接)emmm好像也不是很准确,有点玄学,找不到规律,安装了好几遍都没出现base环境,即可看到base环境了,输入python即可查看到python的版本,输入命令 exit() 后退出,创建一个名为pyspark的虚拟环境供我们学习使用。首先输入命令: conda create -n pyspark python=3.8 , 出现提示后输入 y ,等待一会后即创建虚拟环境成功。然后输入命令 conda activate pyspark 检验虚拟环境能否切换,进入成功即可。
4.解压并改名。 (注意在pyspark的环境下执行)现在开始安装spark,首先进入到目录 /opt/software/ 下输入命令: tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz 命令,进行解压。解压好后输入命令: mv spark-3.2.0-bin-hadoop3.2/ spark-3.2.0 进行改名方便后续配置环境变量。
5.配置环境变量。 进入目录 /etc/profile.d 执行命令: vi my_env.sh ,添加如下参数,添加完毕后输入命令: source /etc/profile 使其生效,最后输入: pyspark 检验是否生效,在关闭即exit()之前,可进入 http://hadoop102:4040网址查看spark的web UI监控页面。
#SPARK_HOME export SPARK_HOME=/opt/software/spark-3.2.0 export PATH=$PATH:$SPARK_HOME/bin #PYSPARK_PYTHON export PYSPARK_PYTHON=/opt/software/miniconda3/envs/pyspark/bin/python3.8 #HADOOP_CONF_DIR export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
三、Spark on Yarn 模式
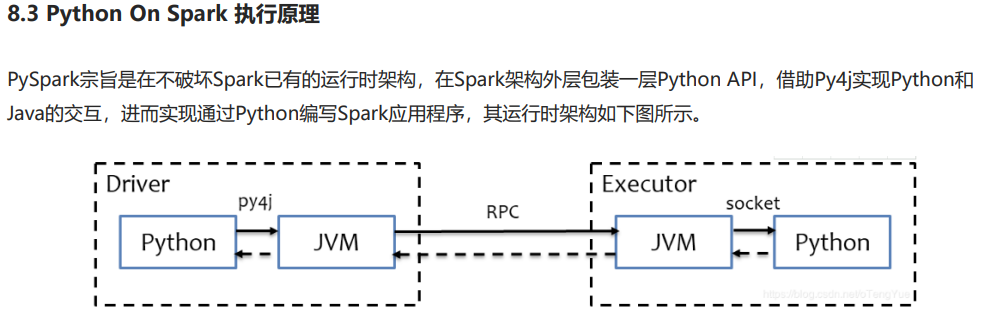
3.1 环境搭建
1.首先进入到spark的conf目录下,输入命令: mv spark-env.sh.template spark-env.sh 对文件进行改名,然后进入该文件加入如下代码:
export JAVA_HOME=/opt/software/jdk1.8.0_371 YARN_CONF_DIR=/opt/software/hadoop-3.2.3/etc/hadoop
2.保存退出后打开输入命令: myhadoop.sh start 启动集群,此处记得要打开全部的虚拟机,然后输入命令: pyspark --master yarn 查看是否可以正常启动,启动成功后可以发现spark的master已经变成yarn了。
3.2 两种部署模式
1.两种运行模式
Spark On YARN是有两种运行模式的,一种是Cluster模式一种是Client模式.这两种模式的区别就是Driver运行的位置.
Cluster模式:即Driver运行在YARN容器内部, 和ApplicationMaster在同一个容器内
Client模式:即Driver运行在客户端进程中, 比如Driver运行在spark-submit程序的进程中
2.两种模式的区别:

默认是client模式,如果需要使用集群模式可以加上命令:--deploy-mode cluster 。
3.总结

四、pyspark类库
1.首先在hadoop102虚拟机上的pyspark环境中输入命令:pip install pyspark ,下载该类库,然后可以使用命令:pip list查看是否安装成功。
2.然后需要在集群中每一台虚拟机上都安装好python环境,按照本文第二部分本地模式环境搭建依次执行1-3步骤。
五、本机开发环境搭建
1.在本机上设置HADOOP_HOME环境变量,由于在hadoop的学习中已经配置好,所以此步跳过。
2.在本机安装anaconda软件,哈哈我也下载好了,跳过。
3. 同样的在本机打开anaconda命令端输入命令: conda create -n pyspark python=3.8 创建pyspark虚拟环境,创建好后进入该环境内,输入命令: pip install pyspark pyhive pymysql jieba 来下载这四个包。
4. 在本机的pycharm中创建spark项目,使用annaconda的的pyspark环境(留作备用环境)。
5. 再新建一个ssh连接,(注意连接前要打开虚拟机)连接到vmware虚拟机中的python环境,配置如下,然后输密码,你知道的6个一,然后继续,目录映射如下,最后创建。
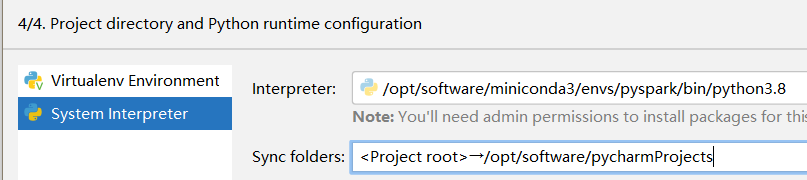
6.如果需要使用本机的环境来运行spark的代码,还需要在window本机上设置一个 PYSPARK_PYTHON 环境变量,参考黑马程序员教程p35
后续来了,有点奇怪,我没有配置这个环境变量,代码还是能运行的没有报错


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义