
MapReduce的学习
一、MapReduce的概述
1.1 MapReduce的核心思想
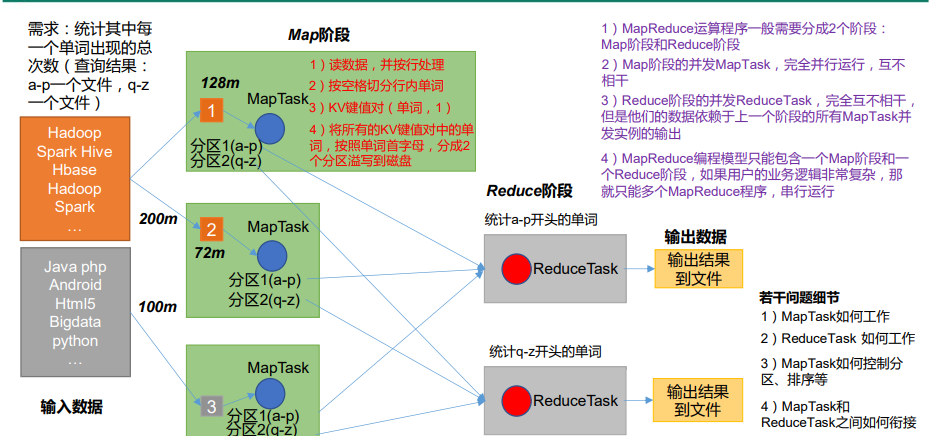
1.2 MapReduce的三类实例进程
1)MrAppMaster:负责整个程序的过程调度及状态协调。
2)MapTask:负责 Map 阶段的整个数据处理流程。
3)ReduceTask:负责 Reduce 阶段的整个数据处理流程。
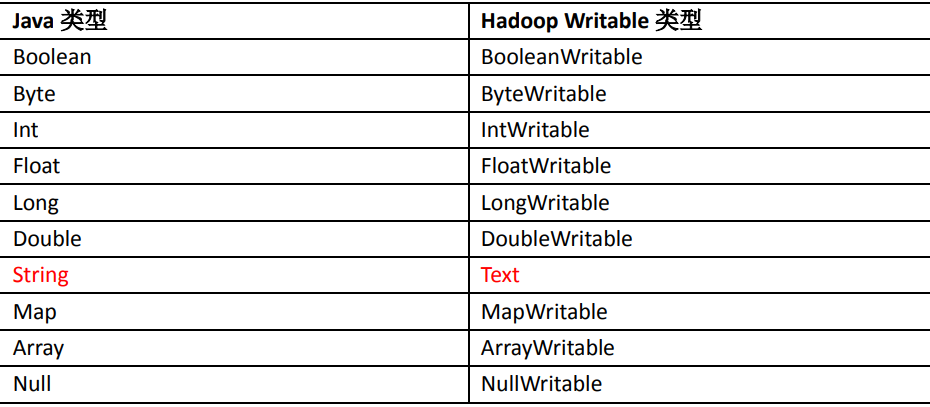
1.3 常用数据序列化类型
1.4 MapReduce编程规范
用户编写的程序分成三个部分:Mapper、Reducer 和 Driver。


二、hadoop序列化
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。 反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。在企业开发中往往需要传输在hadoop集群中传输bean对象,这个时候就需要实现序列化接口wirtable,重写序列化方法和反序列化方法。
三、MapReduce框架原理
3.1 Inputformat数据输入
数据块:Block 是 HDFS 物理上把数据分成一块一块。数据块是 HDFS 存储数据单位。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是 MapReduce 程序计算输入数据的单位,一个切片会对应启动一个 MapTask。

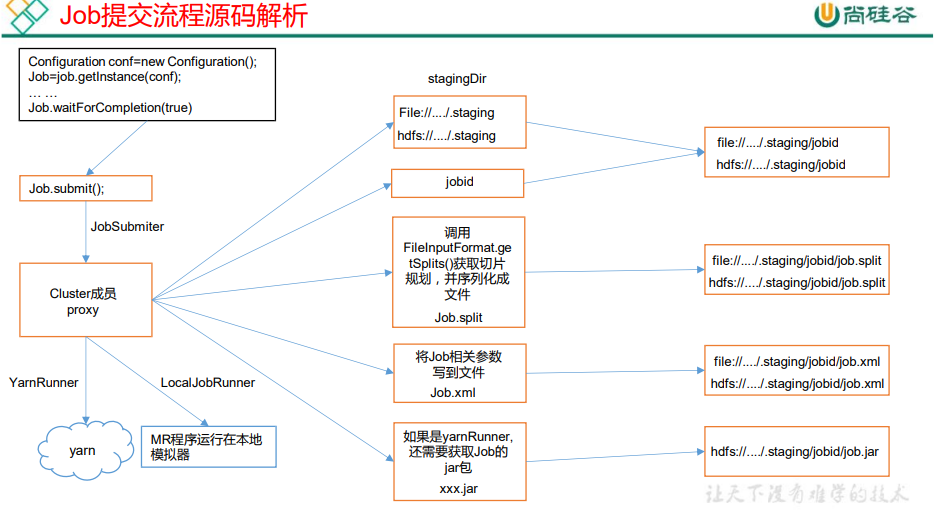
3.1.1 job提交流程源码
引自尚硅谷教程p88
3.1.2 FileInputFormat 切片源码解析
引自尚硅谷教程p89



总的来说就是这几件事情,一,读入文件的切片是逐个文件进行切片,而不是合在一起切片,二、切片大小默认是等于块的大小,块的大小是不能改变的,但是可以通过调整minsize和maxsize这两个参数来调整切片的大小,三、切片的原则是文件的大小除以片的大小 >1.1 就继续切一片,否则就不切片,这是为了避免造成很多的小的片对后续的工作有影响。
3.1.3 TextInputFormat
是FileInputFormat实现类之一,FileInputFormat常见的接口实现类包括:TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat 和自定义 InputFormat 等。TextInputFormat 是默认的 FileInputFormat 实现类。按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量, LongWritable 类型。值是这行的内容,不包括任何行终止符(换行符和回车符),Text 类型。
3.1.4 CombineTextInputFormat 切片机制
框架默认的 TextInputFormat 切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个 MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
所以就有了 CombineTextInputFormat 嘛。

1)虚拟存储过程

2)切片过程

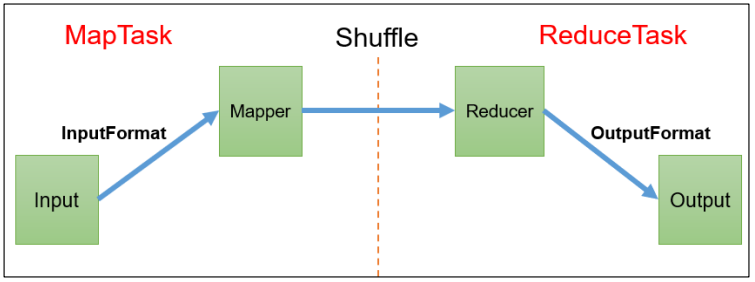
3.2 MapReduce 工作流程
引自尚硅谷教程p94
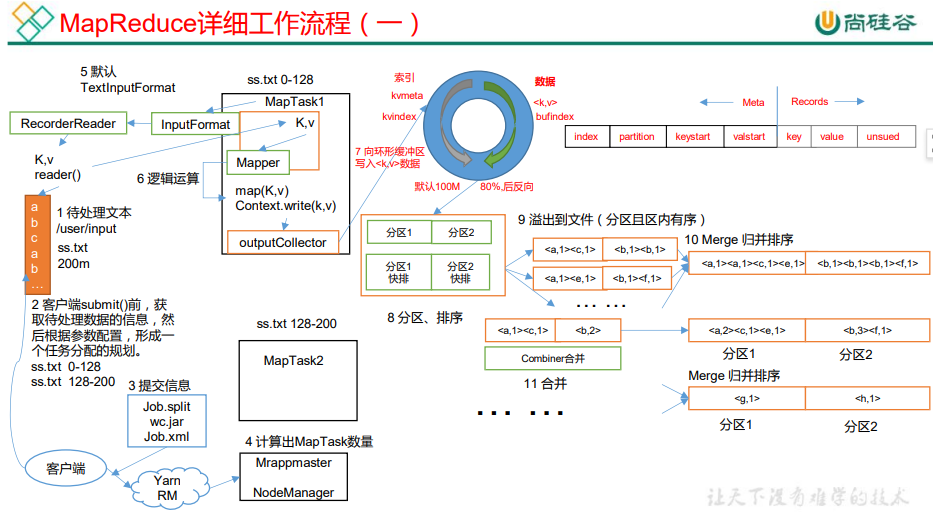
具体 Shuffle 过程详解:
(1)MapTask 收集我们的 map()方法输出的 kv 对,放到内存缓冲区中
(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
(3)多个溢出文件会被合并成大的溢出文件
(4)在溢出过程及合并的过程中,都要调用 Partitioner 进行分区和针对 key 进行排序
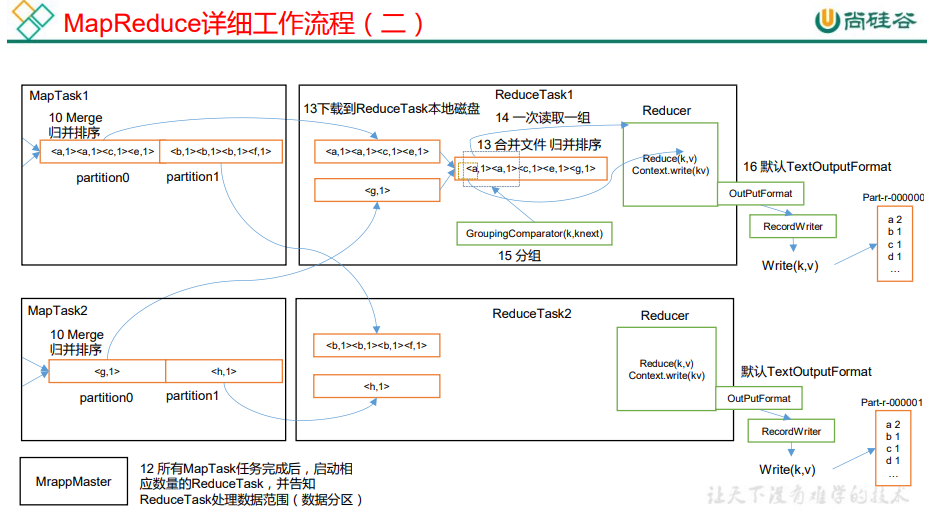
(5)ReduceTask 根据自己的分区号,去各个 MapTask 机器上取相应的结果分区数据
(6)ReduceTask 会抓取到同一个分区的来自不同 MapTask 的结果文件,ReduceTask 会将这些文件再进行合并(归并排序)
(7)合并成大文件后,Shuffle 的过程也就结束了,后面进入 ReduceTask 的逻辑运算过程(从文件中取出一个一个的键值对 Group,调用用户自定义的 reduce()方法)
注意:
(1)Shuffle 中的缓冲区大小会影响到 MapReduce 程序的执行效率,原则上说,缓冲区越大,磁盘 io 的次数越少,执行速度就越快。
(2)缓冲区的大小可以通过参数调整,参数:mapreduce.task.io.sort.mb 默认 100M。
3.3 Shuffle 机制
Map 方法之后,Reduce 方法之前的数据处理过程称之为 Shuffle。
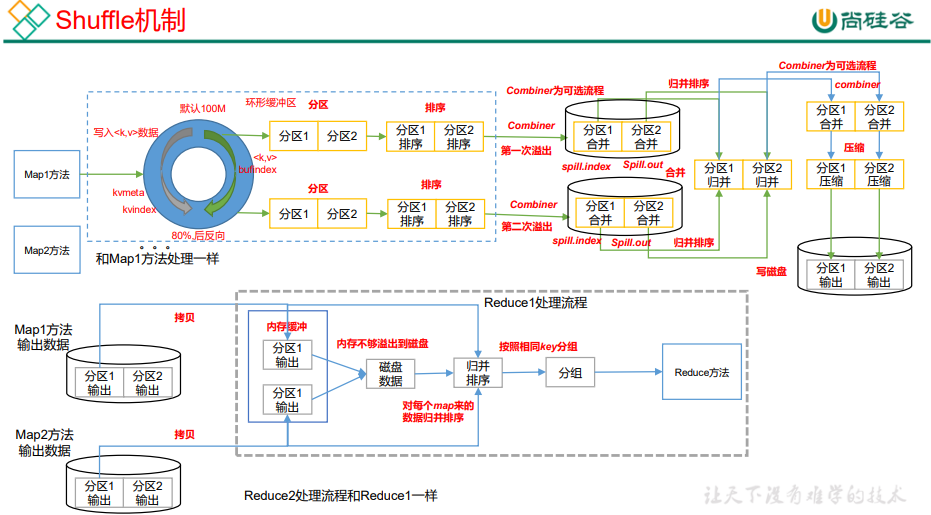
3.3.1 Partition 分区
1)默认分区是根据key的hashCode对ReduceTasks个数取模得到的。用户没法控制哪个key存储到哪个分区。
2)自定义分区

3)总结

3.3.2 WritableComparable 排序
排序是MapReduce框架中最重要的操作之一。
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
排序分类

3.3.3 Combiner 合并
(1)Combiner是MR程序中Mapper和Reducer之外的一种组件。
(2)Combiner组件的父类就是Reducer。
(3)Combiner和Reducer的区别在于运行的位置,Combiner是在每一个MapTask所在的节点运行;Reducer是接收全局所有Mapper的输出结果;
(4)Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量。
(5)Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv应该跟Reducer的输入kv类型要对应起来。
3.4 OutputFormat 数据输出
OutputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了 OutputFormat接口。默认输出格式TextOutputFormat,可以根据应用场景自定义OutputFormat。
3.5 MapReduce 内核源码解析
3.5.1 MapTask 工作机制
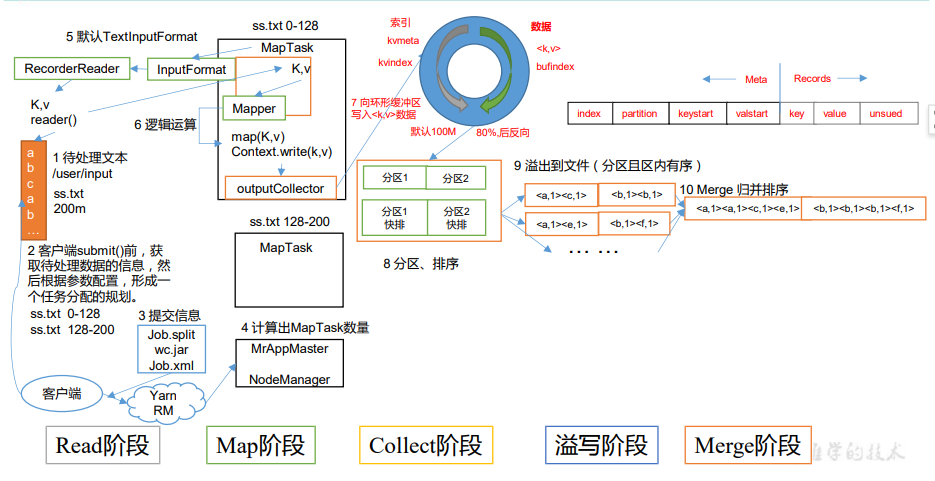
3.5.2 ReduceTask 工作机制
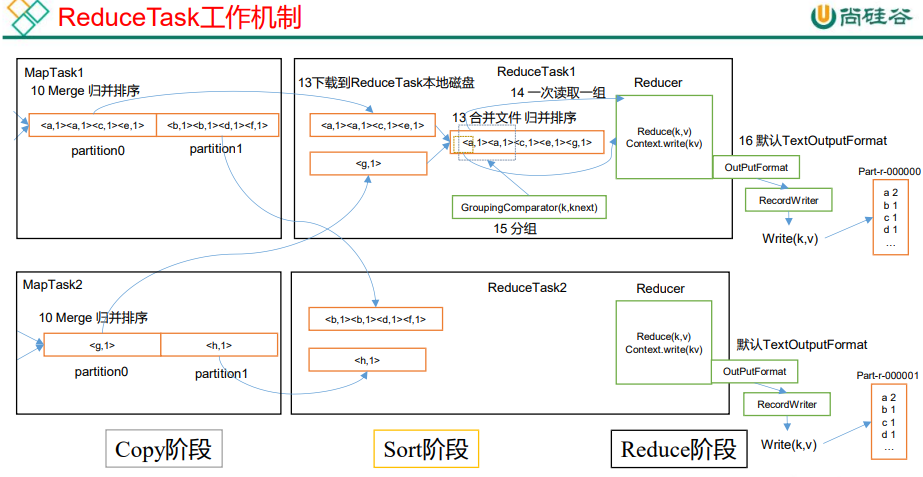
3.5.3 ReduceTask 并行度决定机制

3.6 Join 应用
3.6.1 Reduce Join
Map 端的主要工作:为来自不同表或文件的 key/value 对,打标签以区别不同来源的记录。然后用连接字段作为 key,其余部分和新加的标志作为 value,最后进行输出。
Reduce 端的主要工作:在 Reduce 端以连接字段作为 key 的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在 Map 阶段已经打标志)分开,最后进行合并就 ok 了。
这种方式中,合并的操作是在 Reduce 阶段完成,Reduce 端的处理压力太大,Map节点的运算负载则很低,资源利用率不高,且在 Reduce 阶段极易产生数据倾斜。
3.6.2 Map Join
Map Join 适用于一张表十分小、一张表很大的场景。在 Map 端缓存多张表,提前处理业务逻辑,这样增加 Map 端业务,减少 Reduce 端数据的压力,尽可能的减少数据倾斜。
3.7 数据清洗(ETL)
“ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程。ETL 一词较常用在数据仓库,但其对象并不限于数据仓库。在运行核心业务 MapReduce 程序之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行 Mapper 程序,不需要运行 Reduce 程序。
3.8 MapReduce 开发总结
1)输入数据接口:InputFormat
默认使用的实现类是:TextInputFormat,TextInputFormat 的功能逻辑是:一次读一行文本,然后将该行的起始偏移量作为key,行内容作为 value 返回。CombineTextInputFormat 可以把多个小文件合并成一个切片处理,提高处理效率。
2)逻辑处理接口:Mapper
用户根据业务需求实现其中三个方法:map() setup() cleanup ()
3)Partitioner 分区
有默认实现 HashPartitioner,逻辑是根据 key 的哈希值和 numReduces 来返回一个分区号;key.hashCode()&Integer.MAXVALUE % numReduces
4)Comparable 排序
当我们用自定义的对象作为 key 来输出时,就必须要实现 WritableComparable 接口,重写其中的 compareTo()方法。部分排序:对最终输出的每一个文件进行内部排序。全排序:对所有数据进行排序,通常只有一个 Reduce。二次排序:排序的条件有两个。
5)Combiner 合并
Combiner 合并可以提高程序执行效率,减少 IO 传输。但是使用时必须不能影响原有的业务处理结果。
6)逻辑处理接口:Reducer
用户根据业务需求实现其中三个方法:reduce() setup() cleanup ()
7)输出数据接口:OutputFormat
默认实现类是 TextOutputFormat,功能逻辑是:将每一个 KV 对,向目标文本文件输出一行。
四、数据压缩
压缩的优点:以减少磁盘 IO、减少磁盘存储空间;
压缩的缺点:增加 CPU 开销;
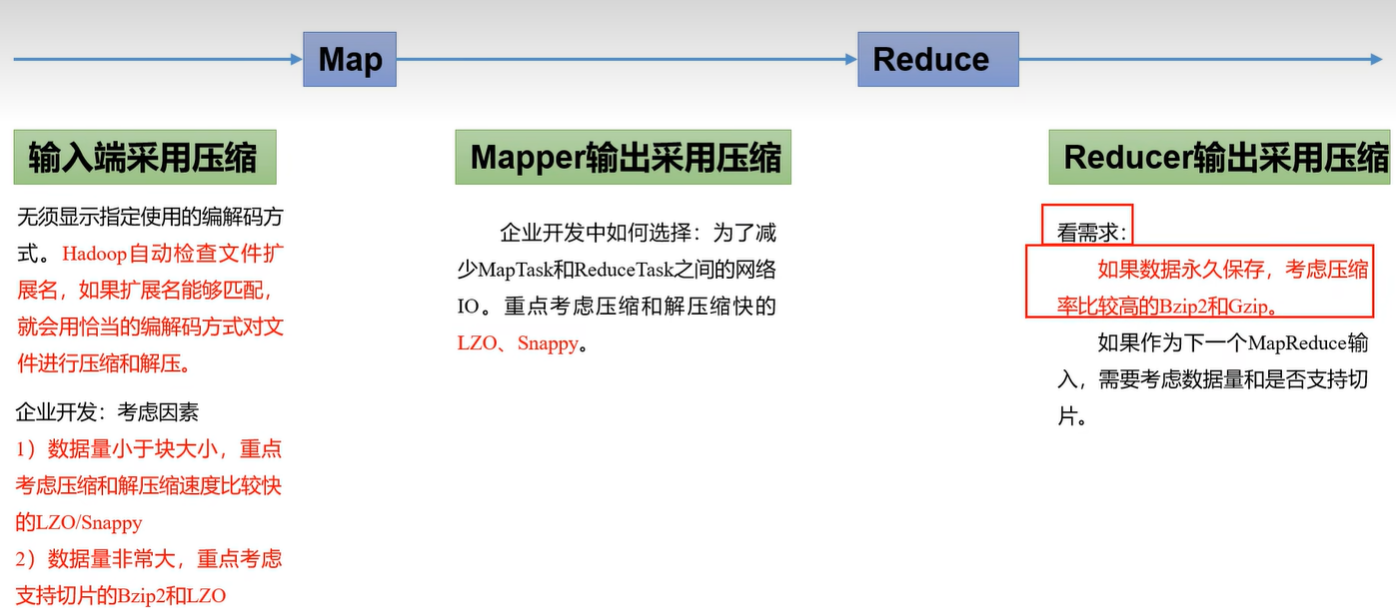
压缩原则:(1)运算密集型的 Job,少用压缩;(2)IO 密集型的 Job,多用压缩;
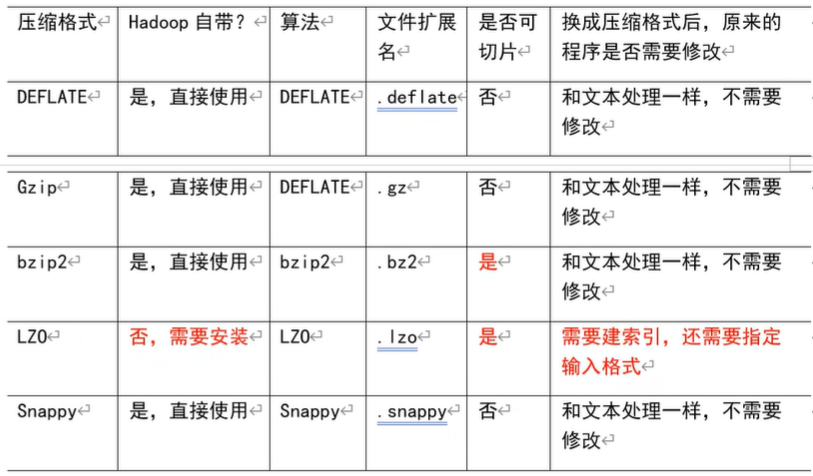
4.1 MR 支持的压缩编码
压缩算法对比介绍
4.2 压缩方式选择
压缩方式选择时重点考虑:压缩/解压缩速度、压缩率(压缩后存储大小)、压缩后是否可以支持切片。
1) Gzip 压缩
优点:压缩率比较高; 缺点:不支持 Split;压缩/解压速度一般;
2)Bzip2 压缩
优点:压缩率高;支持 Split; 缺点:压缩/解压速度慢。
3)Lzo 压缩
优点:压缩/解压速度比较快;支持 Split; 缺点:压缩率一般;想支持切片需要额外创建索引。
4)Snappy 压缩
优点:压缩和解压缩速度快; 缺点:不支持 Split;压缩率一般;
4.3 压缩位置选择
压缩可以在 MapReduce 作用的任意阶段启用。
4.4 压缩参数配置
1)为了支持多种压缩/解压缩算法,Hadoop 引入了编码/解码器

2)要在 Hadoop 中启用压缩,可以配置如下参数
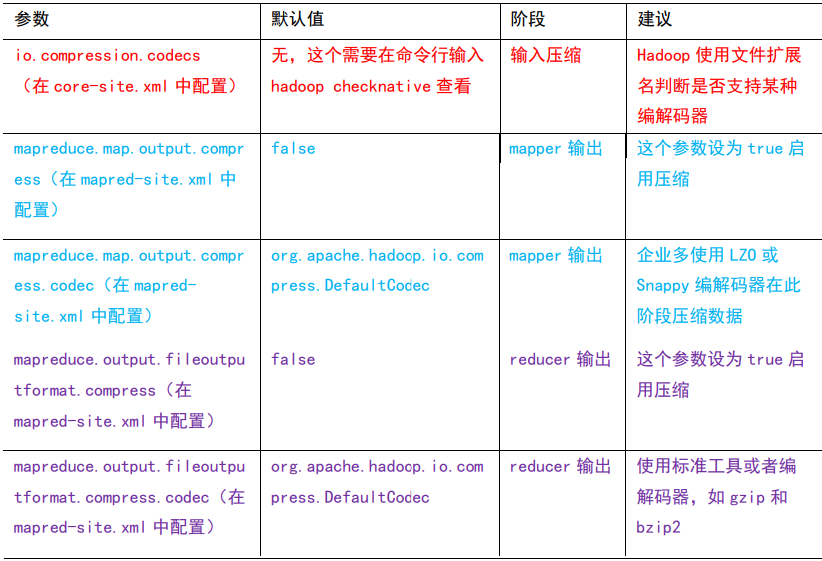
注:即使你的 MapReduce 的输入输出文件都是未压缩的文件,你仍然可以对 Map 任务的中间结果输出做压缩,因为它要写在硬盘并且通过网络传输到 Reduce 节点,对其压缩可以提高很多性能。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义