
hadoop入门
一、hadoop的组成
引自尚硅谷教程P12
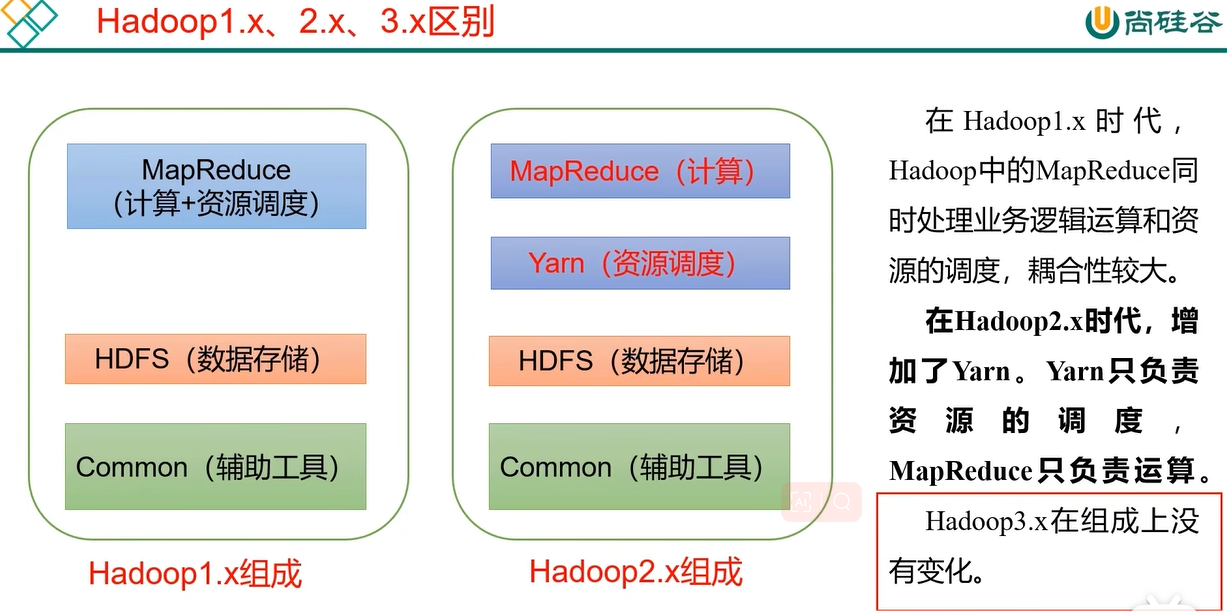
1.1 hdfs的组成
引自尚硅谷教程p13

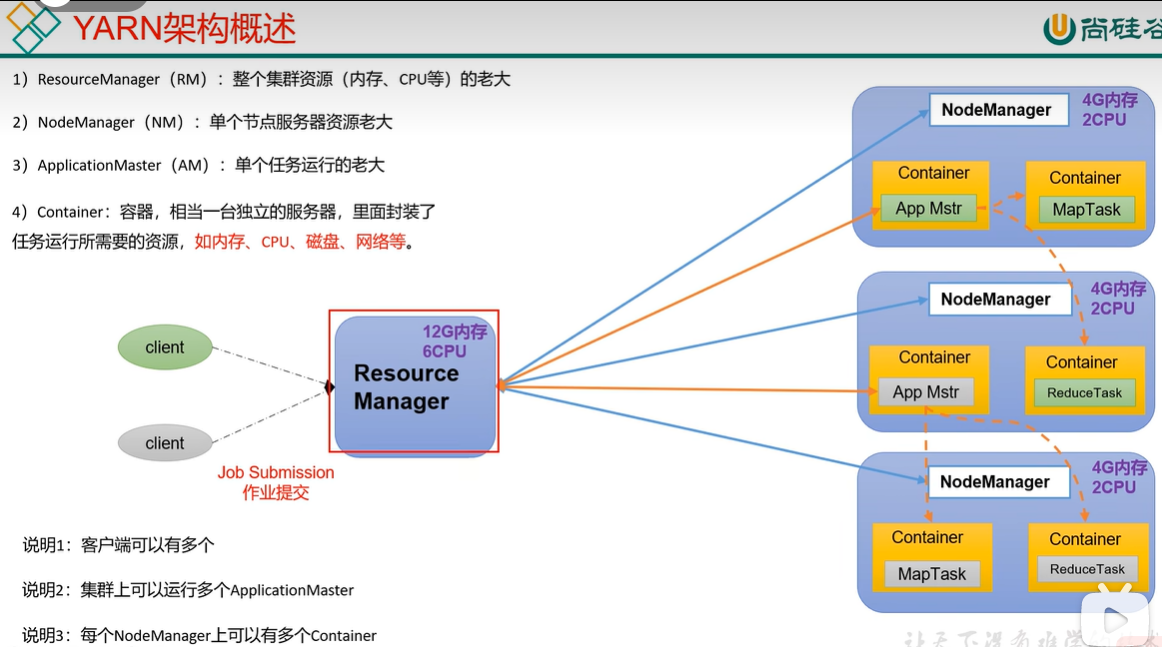
1.2 yarn的组成
引自尚硅谷教程p14
1.3 Mapreduce组成
Mapreduce 将计算过程分为两个阶段:Map和Reduce
1). Map阶段输入数据;
2). Reduce阶段对对数据进行汇总;
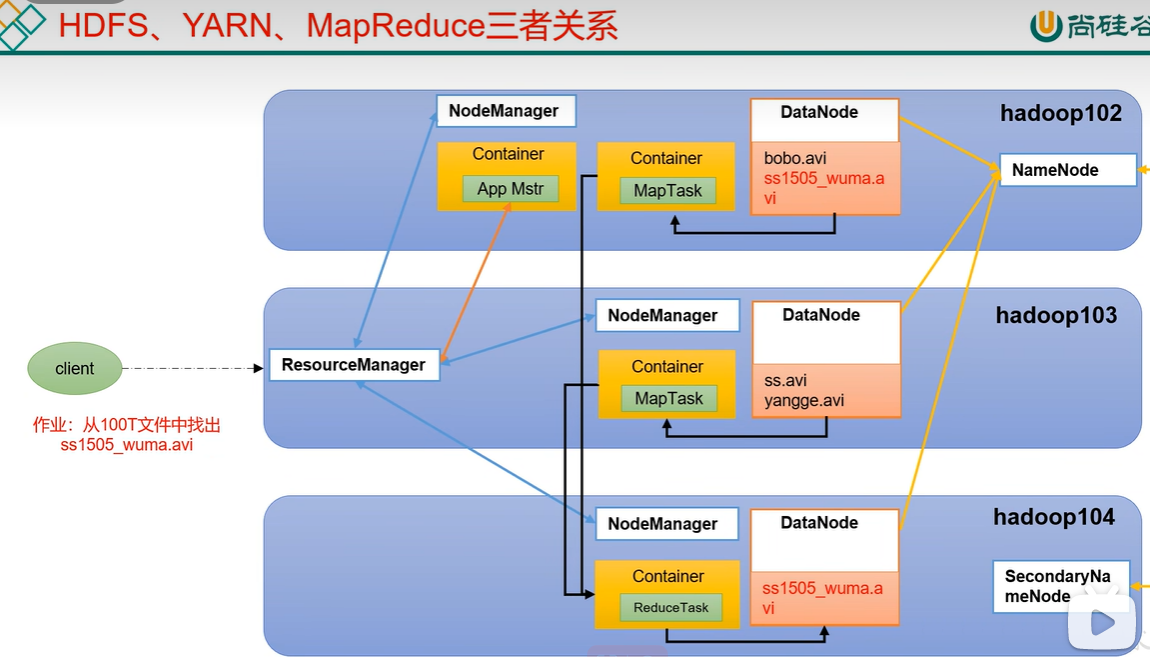
1.4 hdfs、yarn、Mapreduce三者之间的关系
引自尚硅谷教程p16
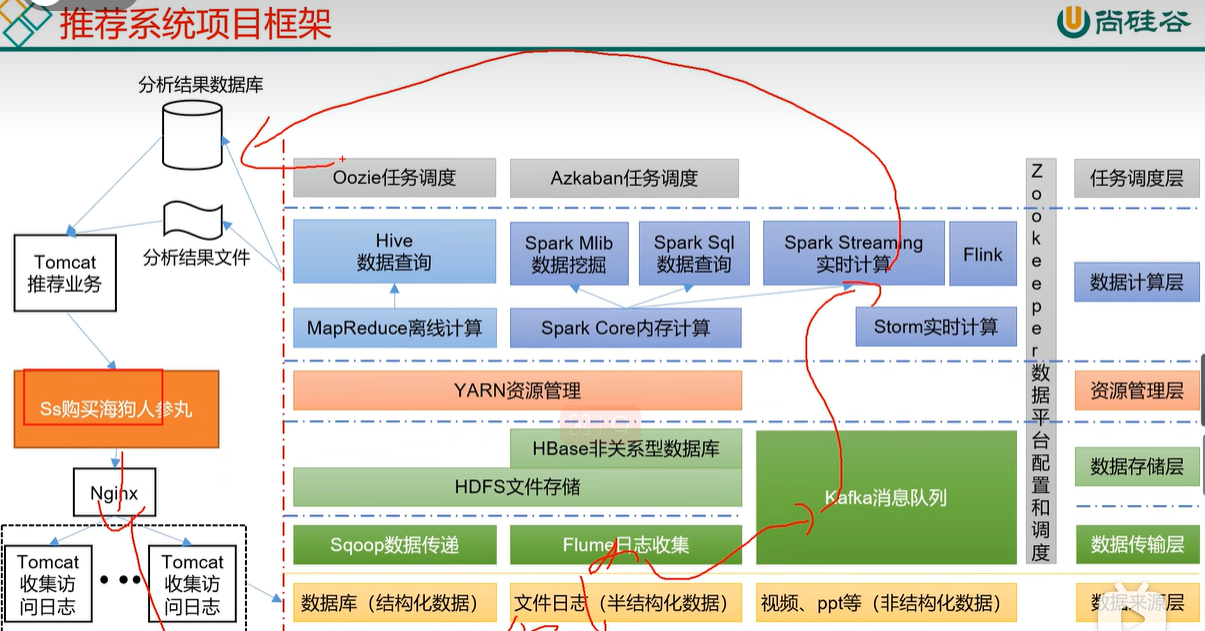
1.5 大数据技术整体生态体系
引自尚硅谷教程p17

1.6 软件推荐功能实现的大致流程
引自尚硅谷教程p17
1.7 hadoop的运行模式
引自尚硅谷教程p26

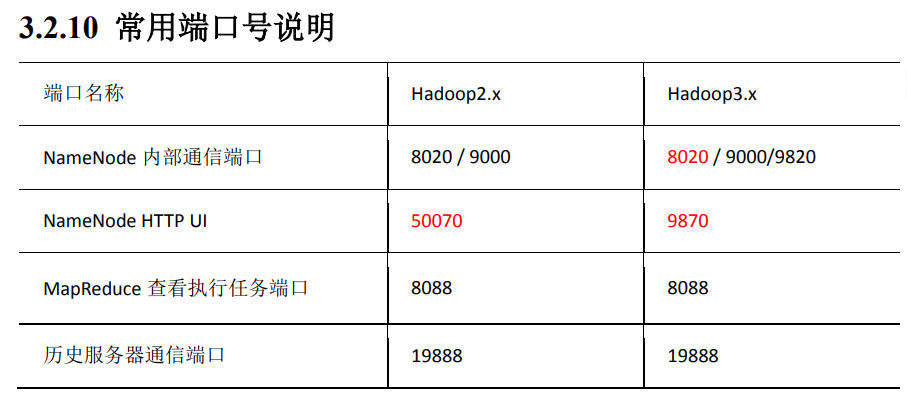
1.8 hadoop常用端口号
1.9 hadoop入门的两道面试题
引自尚硅谷教程p36
二、haddop的运行环境搭建
2.1 搭建模板虚拟机hadoop100
1. 安装vmware(B站或者其它网站上有,我是在百度网盘上下载的vmware16.2.3)
2. 安装centos7.5
3. 然后开始创建一个新的虚拟机,具体步骤如图所示:
1)点击创建新的虚拟机

2)自定义
3)不用动继续下一步
4)稍后安装操作系统
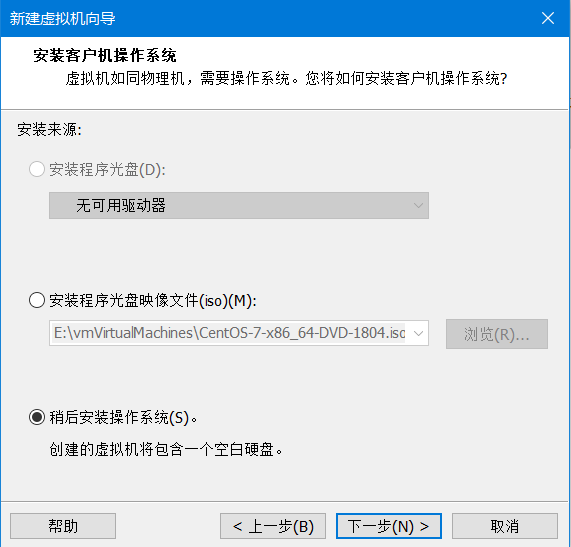
5)选择系统和版本
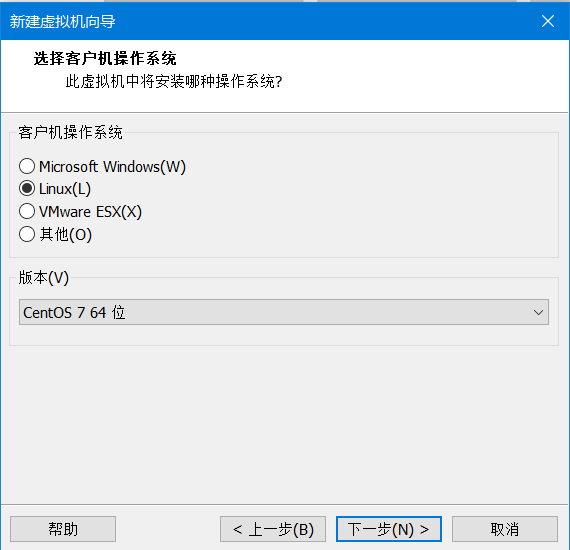
6)输入虚拟机名称和位置
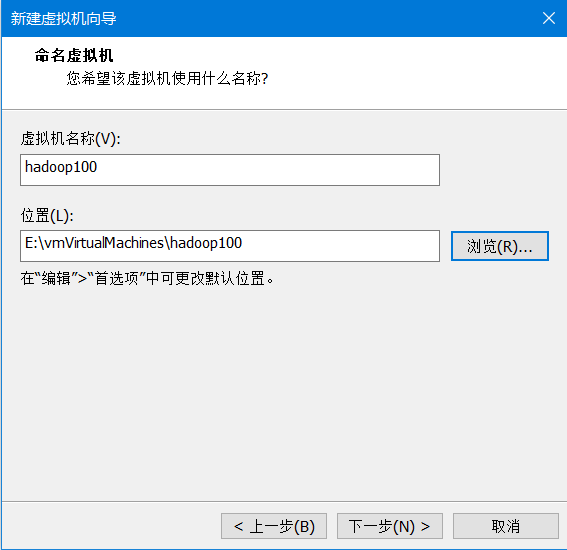
7)根据电脑的配置设置处理器数量和内核数
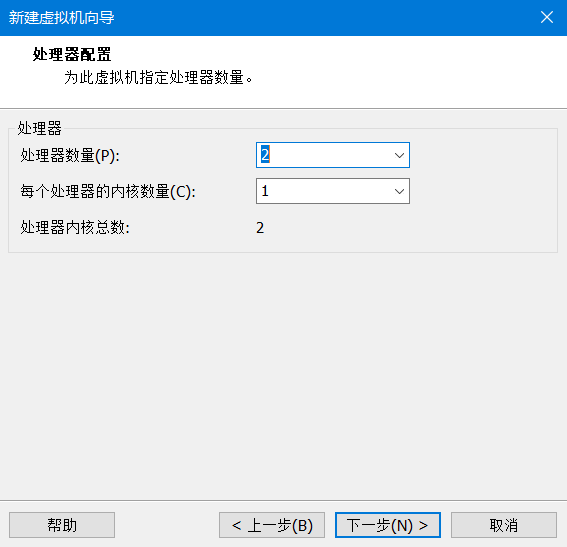
8)根据需要选择内存
9)使用net网络
10)接下来两步都使用推荐的就好
11)创建新的虚拟磁盘
12)根据需要设置磁盘大小
13)指定磁盘位置(还是和虚拟机放在一起)
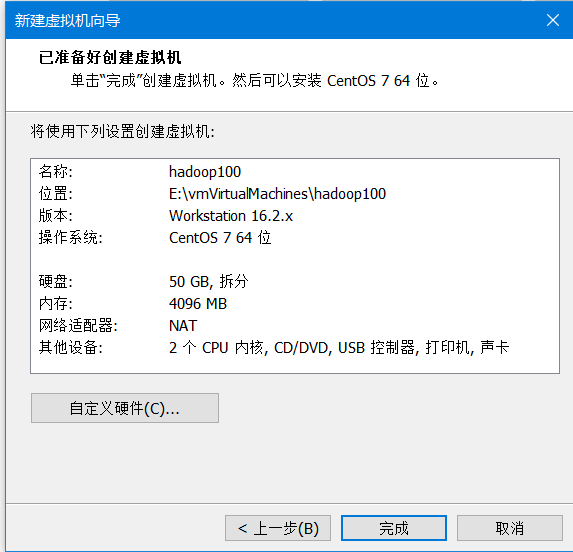
14)完成

4. 下面开始安装centos系统
1)先打开任务管理器性能查看虚拟化技术是否打开

2)点击CD/DVD插入系统硬盘
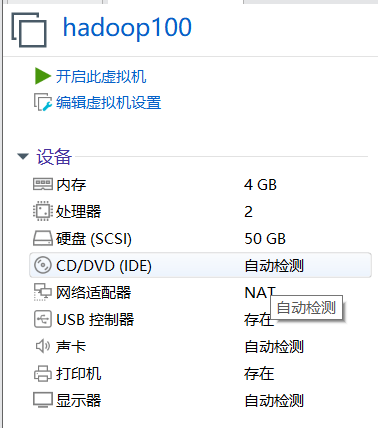
3)使用ISO映像文件
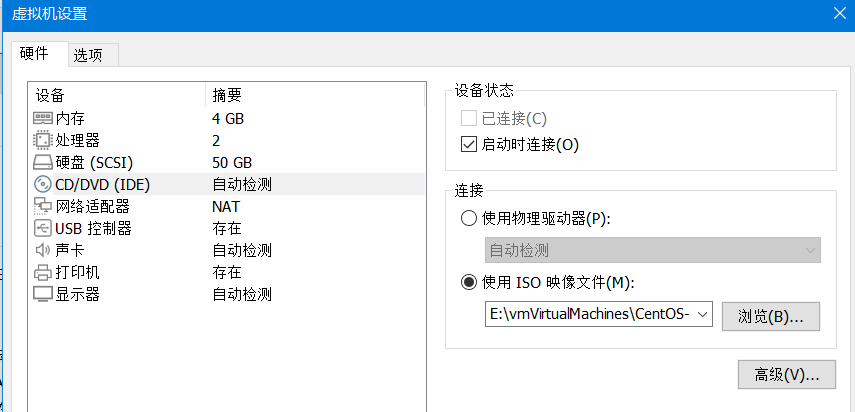
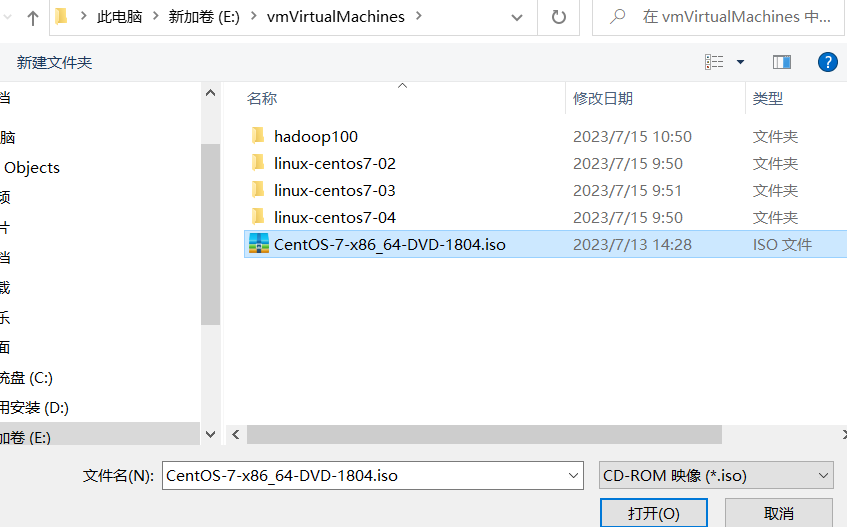
4)点击浏览打开之前下载的centos镜像
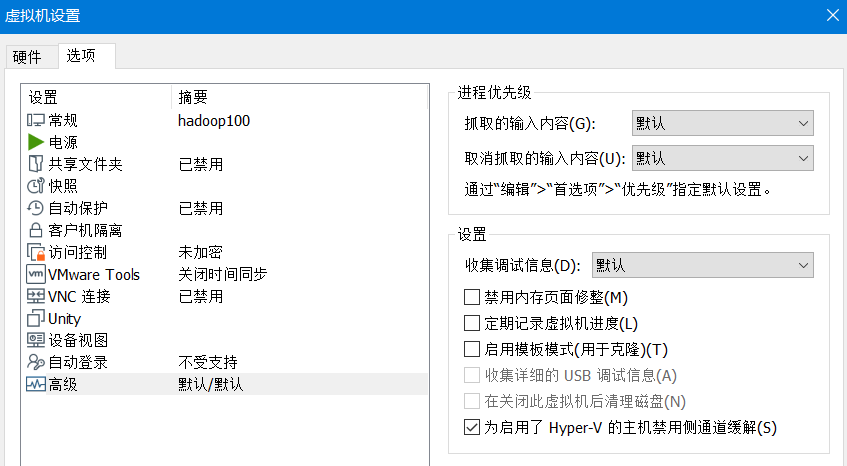
5)点击确定,然后编辑虚拟机设置->选项->高级(因为在电脑上安装了docker),把侧通道缓解关掉,要不然可能会导致虚拟机性能降低(因为已经把hyper-v关掉了,所以这一步删除掉)
6)打开虚拟机等待安装
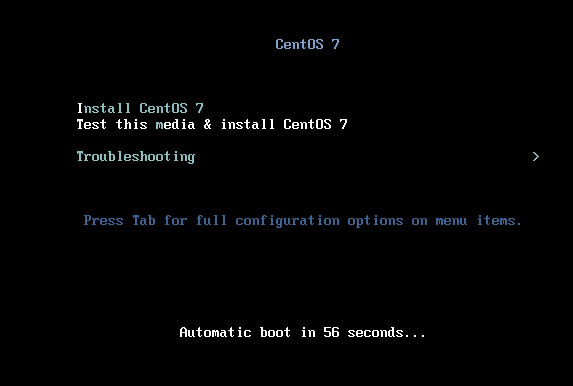
7)选择语言简体中文
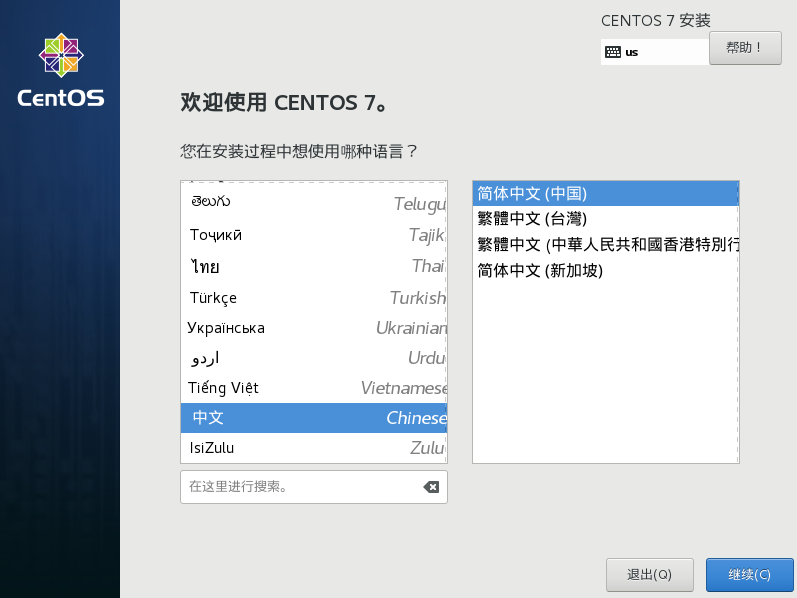
8)设置日期和时间
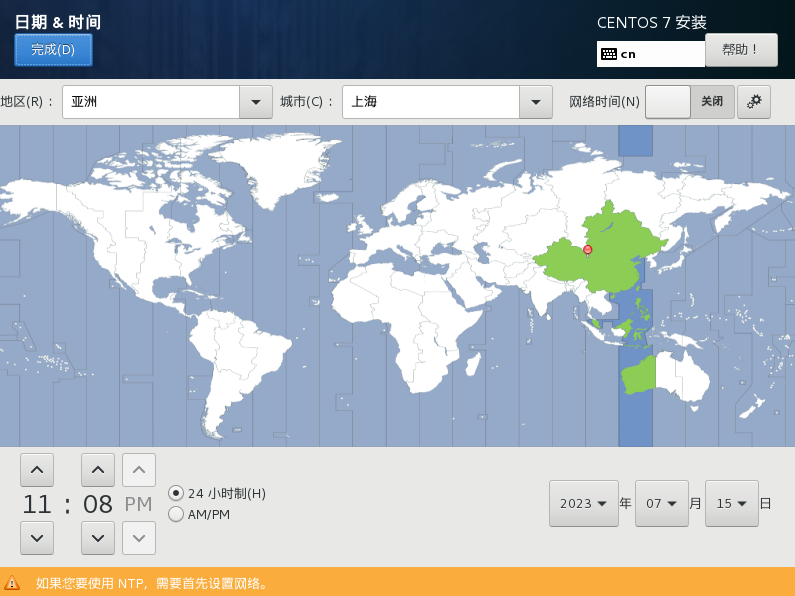
9)点击软件选择,设置安装的版本(由于我已经安装过一遍了,所以我就选择最小系统安装,没有桌面)
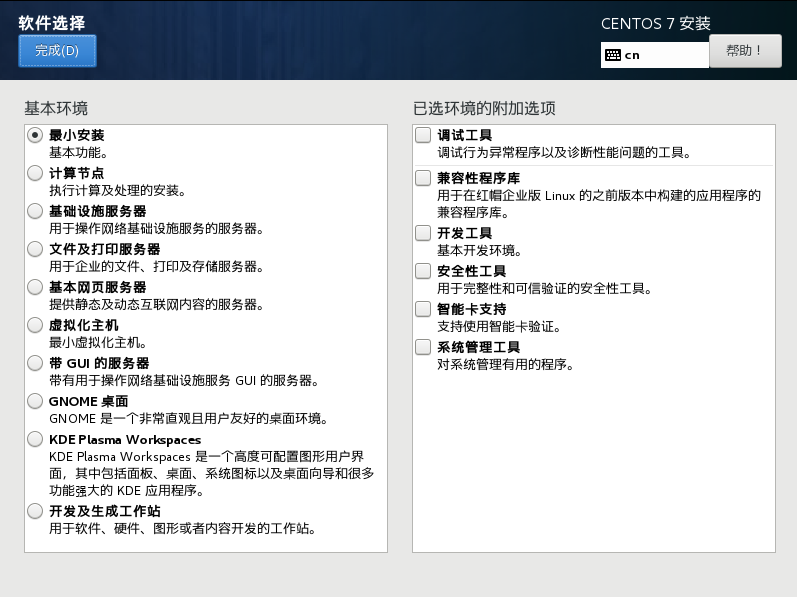
10)点击安装位置->点击我要配置分区->点击完成->来到手动分区页面
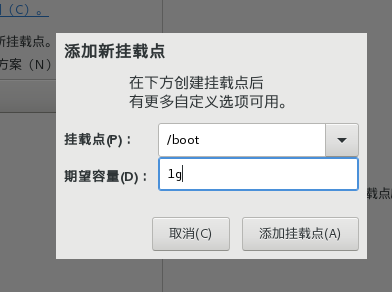
11)点击+号,首先添加挂载点/boot,容量设置为1g,这个是设置虚拟机开机所需要的内存,然后点击添加挂载点,并把文件系统设置为etx4
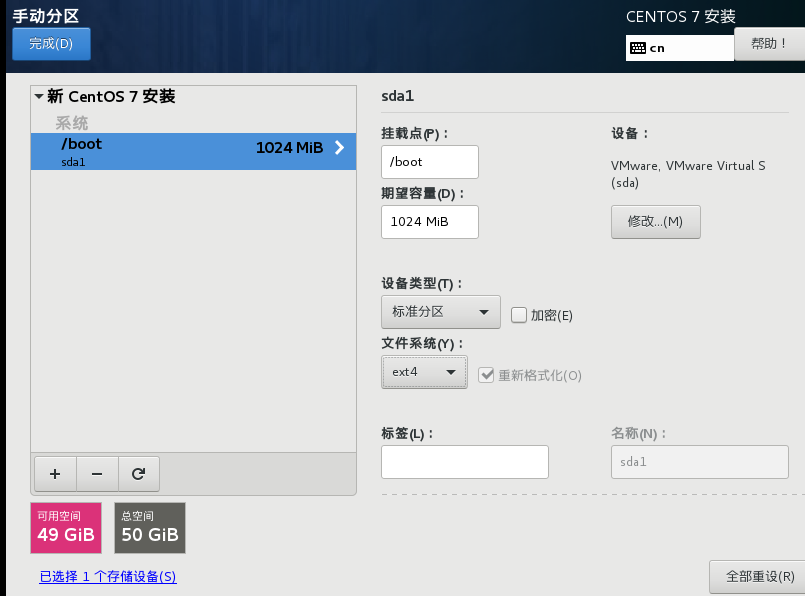
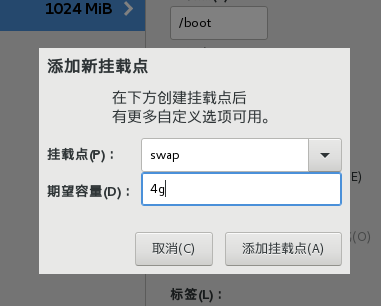
12)继续点击+号添加/swap挂载点,容量设置为4g,这个是相当于备用内存,当内存不够的时候就可以用这4g内存
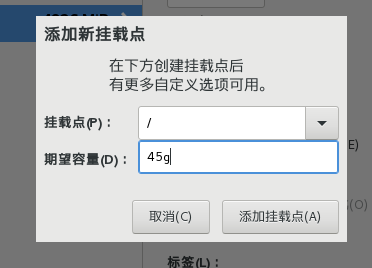
13)继续点击+号添加根目录/挂载点,剩下45g全部是根目录
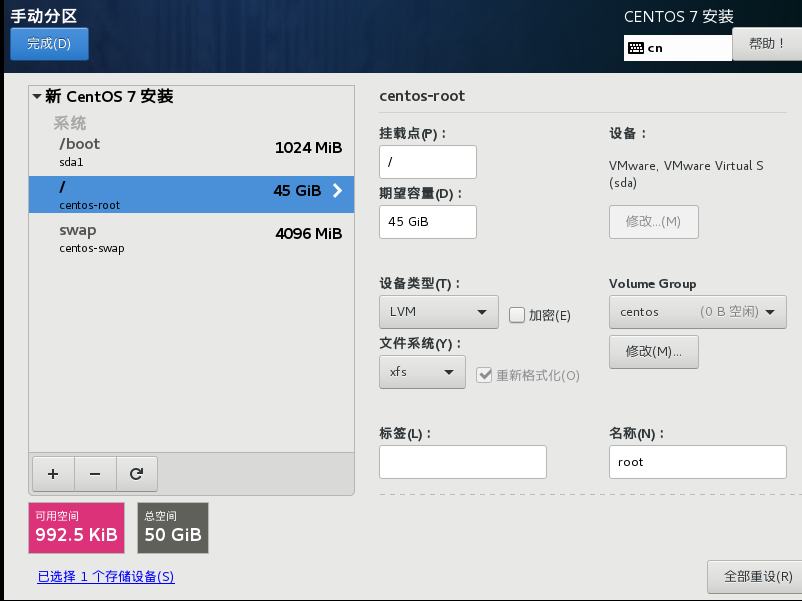
14)全部添加完毕,点击完成,然后点击接受更改
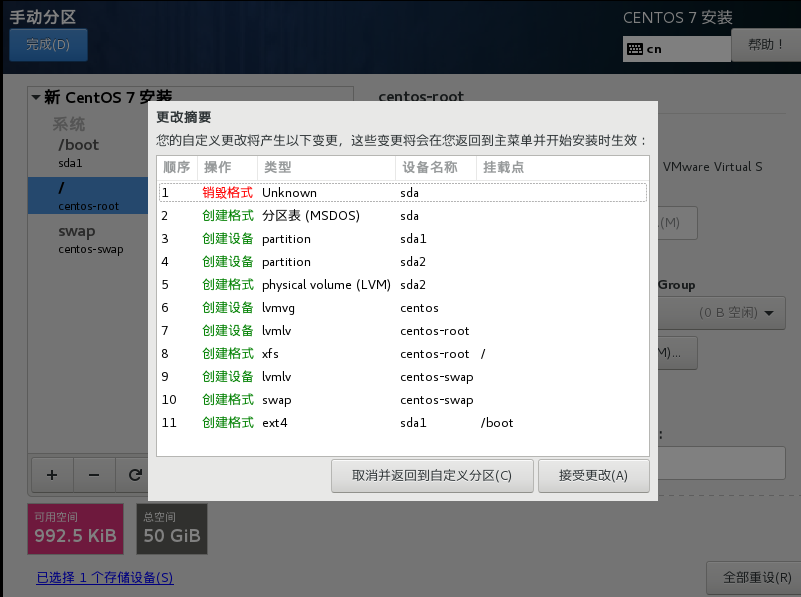
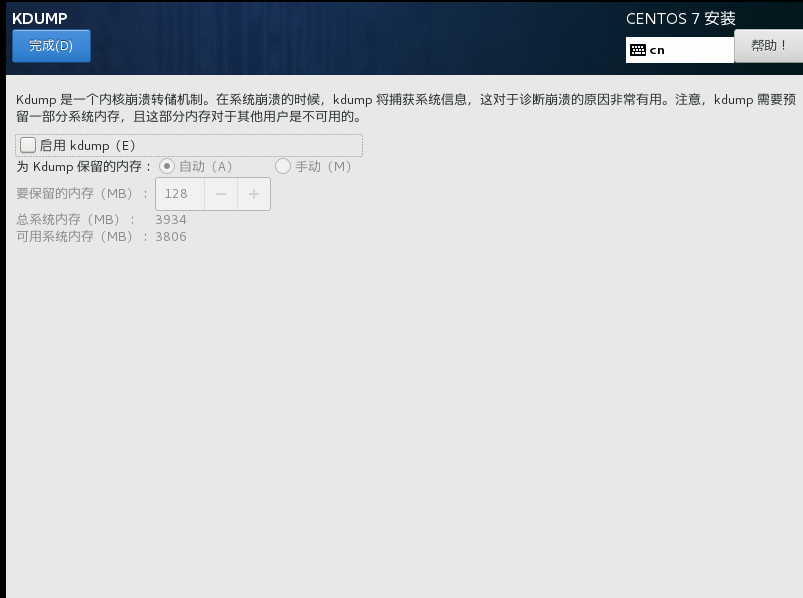
15)然后点击kdump,这个是设置当虚拟机崩溃的时候将崩溃的数据保存在哪里,用多少容量保存,由于学习阶段资源有限,所以不配置kdump,直接取消
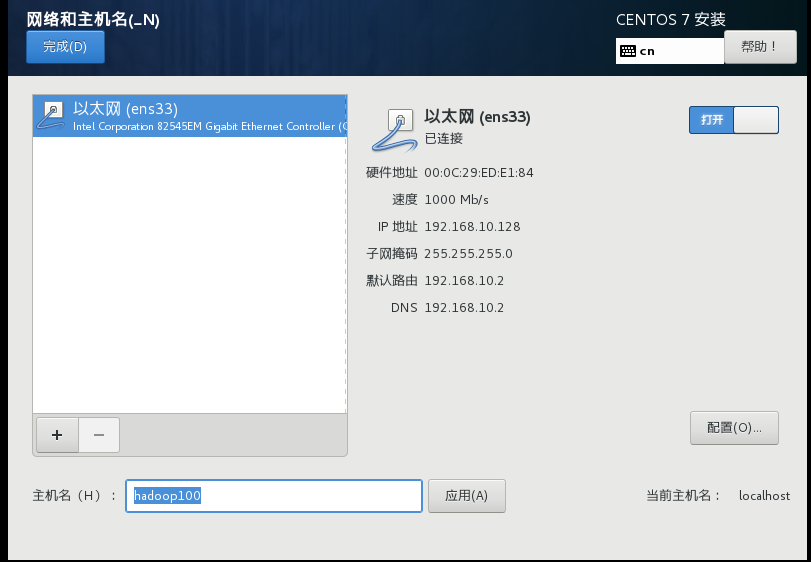
16)最后设置网络和主机名,将主机名称改为hadoop100,打开以太网
17)全部设置完成后点击开始安装,耐心等待,在安装期间可以设置一下root的密码(我设置了6个1),也可以创建一个普通用户,但是感觉好像也没什么用,所以暂时不创建,需要时再创建
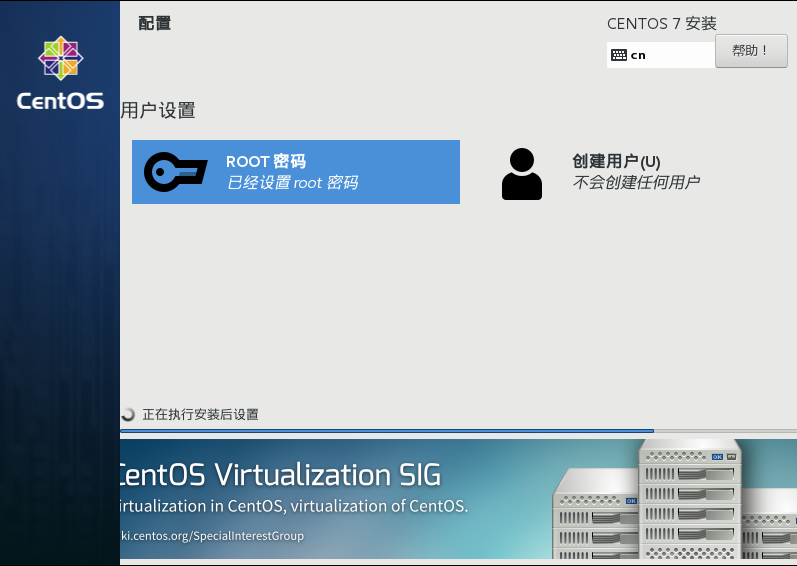
18)等半天,看它完成了以后点击重启,重启完成后就是这个页面,很简陋的页面,登录目前只有root一个用户,没有普通用户
5.下面开始配置IP地址和主机名称
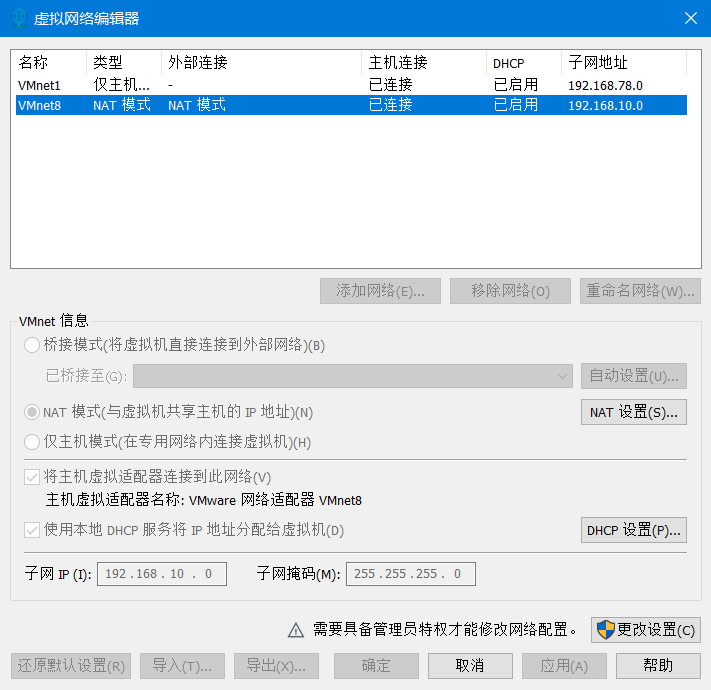
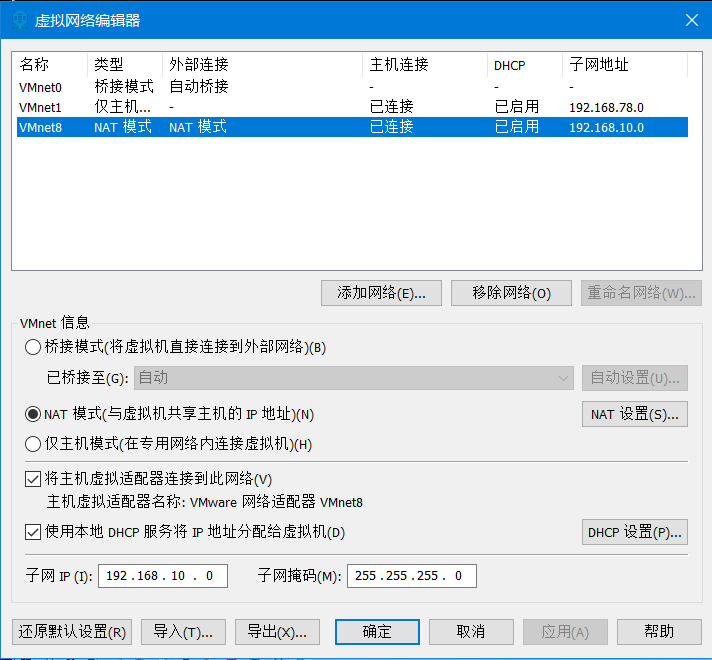
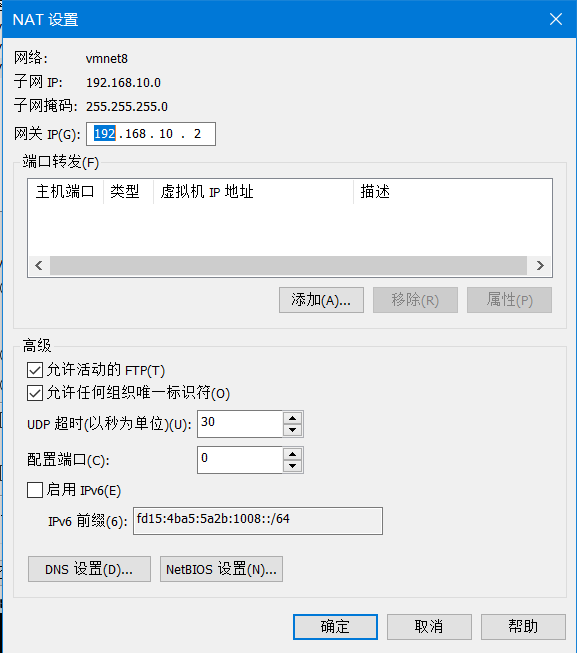
1)打开vmware->编辑->虚拟网络编辑器->点击vmnet8->更改设置->点击vmnet8->将子网IP修改为192.168.10.0->再点击nat设置->将网关IP修改为192.168.10.2后点击确定
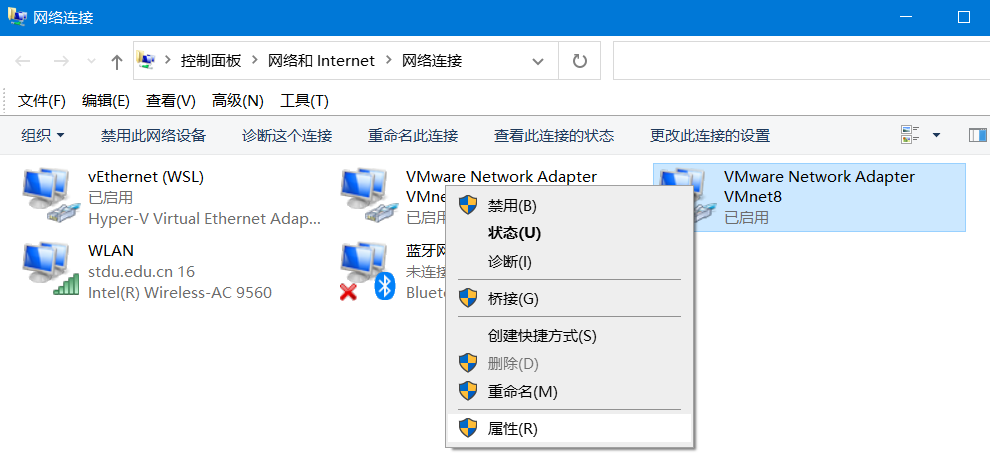
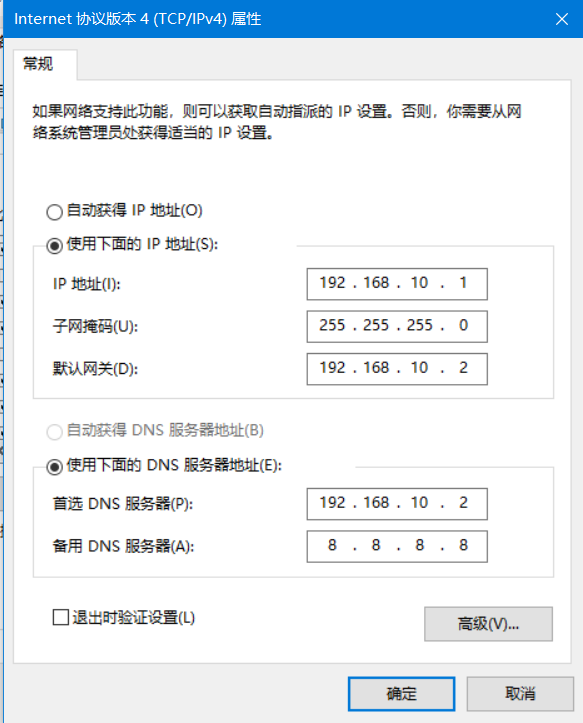
2)win10电脑->所有设置->网络和Internet->更改适配器选项->右键vmnet8点击属性->双击Internet版本协议4->将这些改为如图所示->点击确定
3)进入虚拟机电脑,使用root账号(当然目前只有这一个账号),进入后输入命令:vi /etc/sysconfig/network-scripts/ifcfg-ens33,将bootproto改为static,还要把onboot改成yes,然后添加如图所示的最后三行
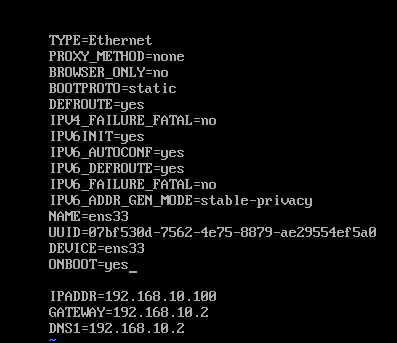
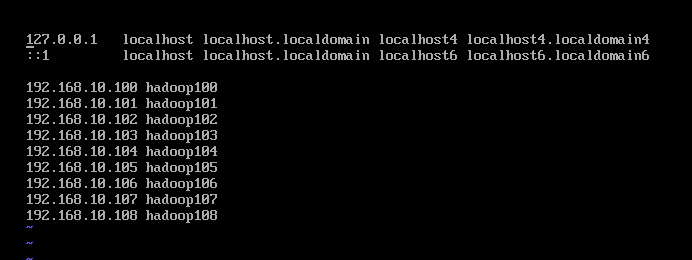
4)保存后再次输入命令:vi /etc/hostname 修改并查看主机名称,输入命令:vi /etc/hosts ,添加如图所示最后几行并保存退出
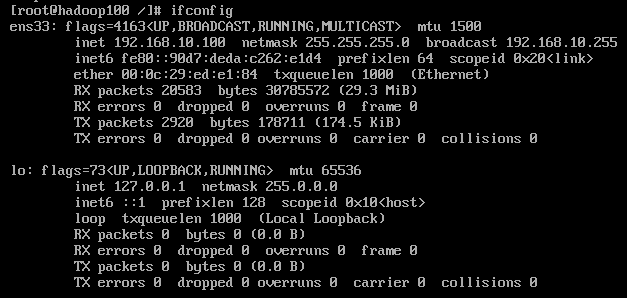
5)输入reboot命令重启,由于是最小安装,所以ifconfig命令识别不出来,输入命令:yum install net-tools,再次输入命令:ifconfig即可查看ip地址,ping baidu.com 查看是否可以连接外网,至此,ip地址和主机名称配置完毕。
6.Xshell远程连接
1)首先安装Xshell,自己装吧
2)先去window10 C:\Windows\System32\drivers\etc 路径下,打开hosts文件,直接记事本打开就可以,然后加入如图所示的几行
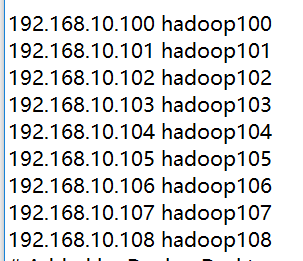
3)然后就可以用主机名称直接用xshell连接了,然后用户身份验证
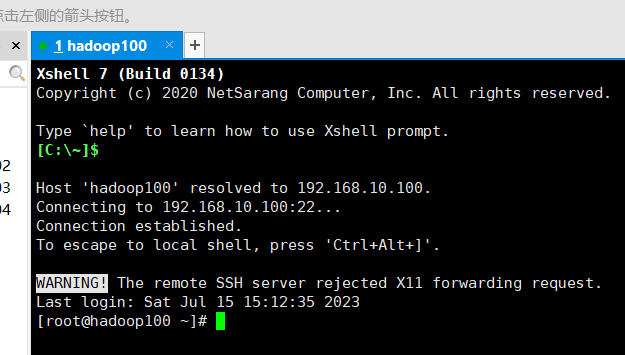
4)连接成功!连接成功以后在安装xftp,也是你自己装吧
7.完善模板虚拟机
1)输入命令:yum install -y epel-release 安装epel软件库,主要提供一些额外的软件包(首先确定是有网的)
2)centos最小版,没有net-tools包和vim工具,上面net-tools已经安装了,vim 我感觉可以不装,vi就可以用
3)然后就是关闭防火墙,一般公司只会在外部设置防火墙,内部服务器是不设置的,所以把防火墙关掉,每次开机也都关掉,即永久关闭防火墙,输入命令:systemctl stop firewalld 还有 systemctl disable firewalld.service
4)进入/opt/路径中创建一个software文件夹用来装以后下载的软件等,完成这些以后重启,模板机就搭好了
2.2 搭建hadoop集群
1. 克隆三台虚拟机
1)首先在克隆之前先把模板虚拟机关机,然后右键虚拟机->管理->克隆
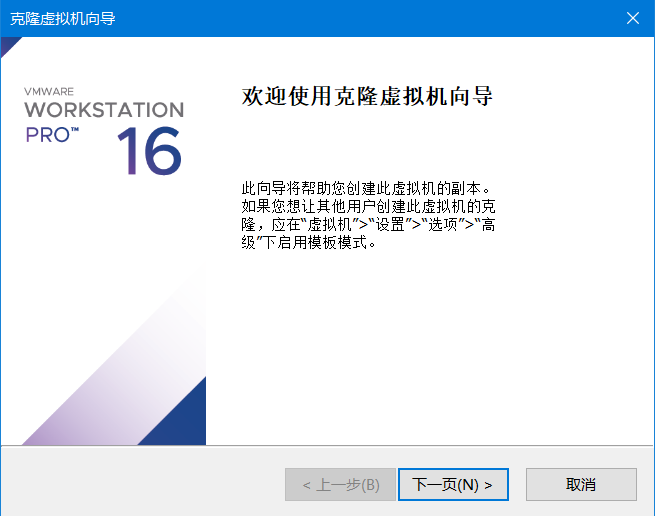
2)下一页->当前状态->下一页->创建完整克隆->下一页-
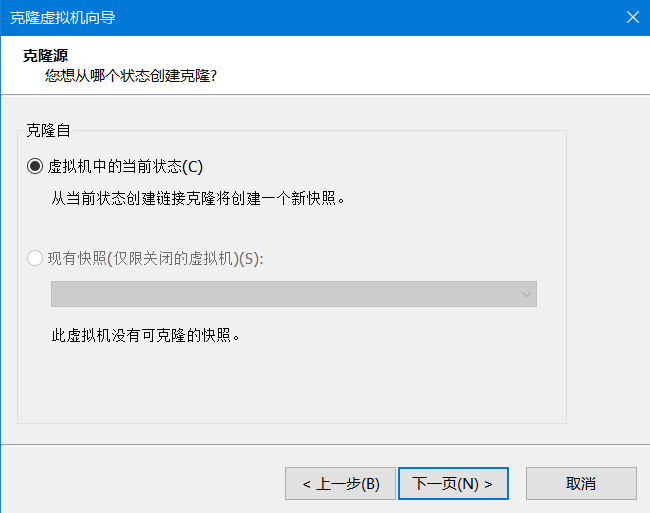
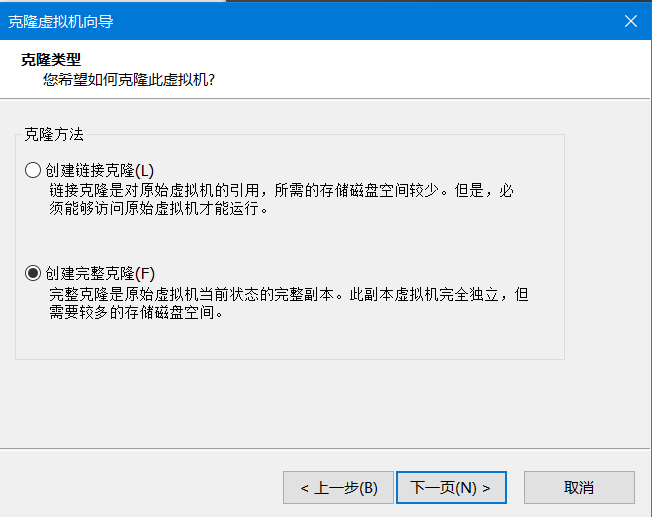
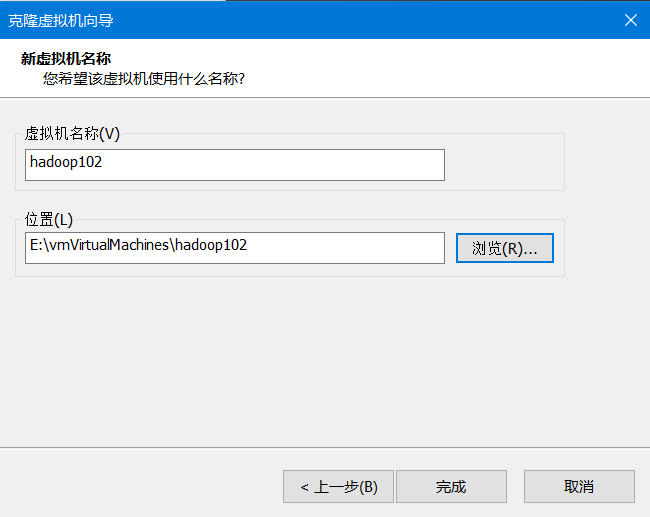
3)设置新克隆的虚拟机的名称和位置,这里是hadoop102->点击完成,很快就可以完成克隆,然后关闭,就克隆完毕了
4)同理,按照同样的方法克隆虚拟机hadoop103,hadoop104
2. 修改各个虚拟机的IP地址和主机名称
1)克隆完成后,由于hadoop102,103,104的IP地址和主机名称还是hadoop100的,所以还需要修改一下,逐个虚拟机输入命令:vi /etc/sysconfig/network-scripts/ifcfg-ens33 修改IP地址,然后输入命令:vi /etc/hostname 来修改主机名称,修改完成后输入reboot重启,因为如果你不重启的话上述命令还没有生效。
2)然后逐个虚拟机验证是否修改成功,可以使用hostname或者ifconfig 或者ping等,验证完成连接xshell。
3. 在hadoop102上安装并配置jdk和hadoop
1)从oracle网站下载jdk8,hadoop官网下载太慢了,照它这个速度得明年才能下完,用清华大学开源软件镜像站下载hadoop3.2.3,速度比较快。
2)然后把下载好的jdk和hadoop用xftp上传到hadoop102虚拟机中路径/opt/software中,使用命令解压jdk:tar -zxvf jdk-8u371-linux-x64.tar.gz,解压好后进入/etc/profile.d ,输入命令:vi my_env.sh,创建新的文件,输入如下代码并保存退出,然后输入命令:source /etc/profile 使修改的文件生效,最后输入java,检验是否配置成功。(出现长串java相关命令即为成功)
#JAVA_HOME export JAVA_HOME=/opt/software/jdk1.8.0_371 export PATH=$PATH:$JAVA_HOME/bin
3)现在开始解压hadoop,输入命令:tar -zxvf hadoop-3.2.3.tar.gz,输入命令:vi /etc/profile.d/my_env.sh,继续在该文件中输入如下代码并保存退出,同样的输入命令:source /etc/profile 使修改的文件生效,最后输入hadoop,检验是否配置成功。
#HADOOP_HOME export HADOOP_HOME=/opt/software/hadoop-3.2.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
4.使用scp安全拷贝命令将数据拷贝到hadoop103和104中
引自尚硅谷教程p27

1)在hadoop102虚拟机输入命令:scp -r /opt/software/jdk1.8.0_371/ root@hadoop103:/opt/software/,然后输入yes,再输入hadoop103的密码,然后在虚拟机hadoop103查看是否拷贝成功。
2)相反的,也可以在hadoop103虚拟机中输入命令:scp -r root@hadoop102:/opt/software/hadoop-3.2.3/ /opt/software/,输入yes,再输入hadoop102的密码,将hadoop安全拷贝到hadoop103中,在hadoop103中查看是否拷贝成功。(这分别是安全拷贝命令scp的两种拷贝方式:推送数据和拉取数据)。
3)还有一种比较神奇滴,就是在hadoop103虚拟机上将hadoop102上的数据拷贝到hadoop104上,输入命令scp -r root@hadoop102:/opt/software/ root@hadoop104:/opt/software/*,然后就是需要依次输入hadoop102的密码,输入yes,再输入hadoop104的密码就可以了。
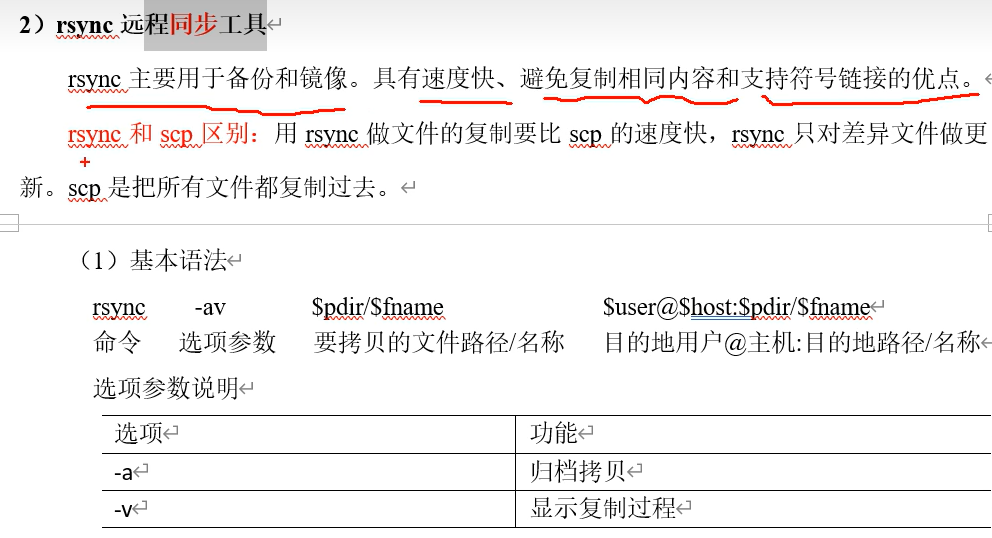
5.使用rsync命令分发
相比scp,rsync只拷贝有变化的部分,效率比scp高,所以在第一次复制时就是用scp命令,后续发生变化有部分改动时可以使用rsync命令。
引自尚硅谷教程p27
6.创建xsync脚本分发集群
1)在~/路径下输入命令:mkdir bin ,创建bin文件,进入bin文件夹,输入命令:vi xsync创建xsync文件,将如下代码填入后保存退出,现在该文件还没有可执行的权限,所以输入命令:chmod 777 xsync,赋予其执行权限,在使用该命令之前,输入命令:yum install -y rsync(上一步已经下载好的话可以跳过)(注意!!!每一台虚拟机都要下载rsync),下载好后现在使用xsync脚本将该bin目录同步到集群所有的虚拟机内,进入到~/目录,输入命令:xsync bin/ ,接下来每台虚拟机需要输入两遍密码,传输完成后进入另外两台虚拟机检查是否分发成功。
#!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in hadoop102 hadoop103 hadoop104 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done
2)确认该分发脚本可以使用后,输入命令:xsync /etc/profile.d/my_env.sh ,即将之前设置好的环境变量也分发到其它虚拟机上去,完成后查看是否成功。分发该环境变量后还需要在每台虚拟机上输入命令:source /etc/profile ,使环境变量生效,完成后输入: java或者hadoop检查其是否生效。
7.设置集群ssh免密登录
1)首先在hadoop102上输入命令:ssh-keygen -t rsa (任何路径下都可以执行),然后连续回车三次,会生成hadoop102虚拟机的公钥和私钥,进入到 /.ssh/目录(该目录是隐藏文件,可以在/目录下使用ls -al命令查看到所有隐藏文件)下就可以看到该虚拟机的公钥和私钥,为了可以实现在hadoop102上无密访问hadoop103,需要将hadoop102的公钥拷贝到hadoop103上,输入命令:ssh-copy-id hadoop103 (同样的在任何路径下都可以),然后输入hadoop103的密码,即可免密连接103。输入命令:ssh hadoop103 可检验是否可以免密登录hadoop103,进入成功后输入exit即可退出。按照同样的方法,把公钥拷贝到hadoop102、104,是的,本机ssh访问也需要输入密码,而且注意虚拟机上的不同用户ssh是不互通的,普通用户的ssh免密只针对普通用户有效,root用户还是需要密码,按需设置就好。由于本机上只有root一个用户,所以就配置一遍了。
2)同理,在hadoop103上按照上述方法配置对三台虚拟机(包括本机)设置ssh免密登录,hadoop104同理。全部设置完成后,xsync集群分发命令就可以无需密码快速分发了。而且每台虚拟机进入到 ~/.ssh/ 目录下后可以看到存在 authorized_keys 文件,该文件是保存可以无密登录自己虚拟机的其它虚拟机。
8.配置完全分布式的hadoop102、103、104集群
集群部署规划,引自尚硅谷教程p30

1)首先在hadoop102虚拟机配置core-site.xml文件,进入到/opt/software/hadoop-3.2.3/etc/hadoop/路径下找到core-site.xml文件,(因为我只配置了root一个用户,增加用户的话按需修改)将如下代码插入到正确的位置中
<!--指定namenode的地址--> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:8020</value> </property> <!--指定hadoop数据的存储目录--> <property> <name>hadoop.tmp.dir</name> <value>/opt/software/hadoop-3.2.3/data</value> </property> <!-- 配置 HDFS 网页登录使用的静态用户为 root --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property>
2)下面配置hdfs-site.xml,与core-site.xml在相同目录下,将如下代码插入到正确的位置上
<!--nn web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop102:9870</value> </property> <!--2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:9868</value> </property>
3)配置yarn-site.xml文件,目录同上,将如下代码插入到正确的位置上
<!--指定MR走shuffle--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--指定Resourcemanager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> <!--环境变量的继承--> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property>
4)配置mapred-site.xml文件,目录同上,将如下代码插入到正确的位置上
<!--指定mapreduce程序运行在yarn上--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
5)配置workers文件,目录同上,输入集群中所有的虚拟机主机名称,以本集群为例,输入如下代码,且不允许有空格和回车等
hadoop102 hadoop103 hadoop104
6)在hadoop102上配置完成后还需要执行命令:xsync /opt/software/hadoop-3.2.3/etc/hadoop/ 来分发到集群中其它的虚拟机上,然后进入其它虚拟机检查一下。
9.启动集群
引自尚硅谷教程p31

1)第一次启动集群需要进行初始化,后续则不在需要初始化。首先在hadoop102虚拟机上进入 /opt/software/hadoop-3.2.3 路径下输入命令:hdfs namenode -format ,和格式化差不多,如果没有报错的话就是初始化成功了,成功以后,在该目录下会出现data和logs两个目录,注意在 /opt/software/hadoop-3.2.3/data/dfs/name/current 目录下的 VERSION 文件记载了该集群的版本信息。
2)初始化成功后就可以启动hdfs了,在hadoop102上进入 /opt/software/hadoop-3.2.3 下输入 sbin/start-dfs.sh 命令启动,然后用jps查看各个虚拟机上运行的结点是否正确,当然了,我就知道你第一次肯定启动不起来,或者崩溃或者缺少结点怎么办呢,首先把每台虚拟机的结点都停掉,停不掉的用kill -9 命令强制停,然后把每台虚拟机上的 /opt/software/hadoop-3.2.3/ 路径下的 data 和 logs 目录删除掉,然后执行上述的初始化命令,最后才可以重新启动。
3)说一下我自己遇到的问题,我的集群倒是没有崩溃,因为我只有root这一个用户,然后启动hdfs的时候报这个错了(如下图)

我也是第一次遇到这个问题,然后上网搜了一下,有很多解决办法,然后我就挑了一个办法,就是在hadoop目录下的sbin目录下,在 start-dfs.sh 和 stop-dfs.sh 这两个文件的顶部添加以下代码
HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
在 start-yarn.sh 文件和 stop-yarn.sh 文件顶部输入以下代码
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
因为我的结点根本就没有启动起来,所以我没有删除data和logs文件,也没有重新初始化,直接在hadoop102上改完以后分发到另外两台然后直接启动,成功了。启动hdfs成功后就可以访问hdfs的外部网站,网站地址:http://hadoop102:9870/
4)访问成功后进入hadoop103进入/opt/software/hadoop-3.2.3/输入命令:sbin/start-yarn.sh,启动成功后查看节点是否缺失。正确启动后可以进入网站http://hadoop103:8088/查看yarn的资源调度页面。至此,集群启动成功。
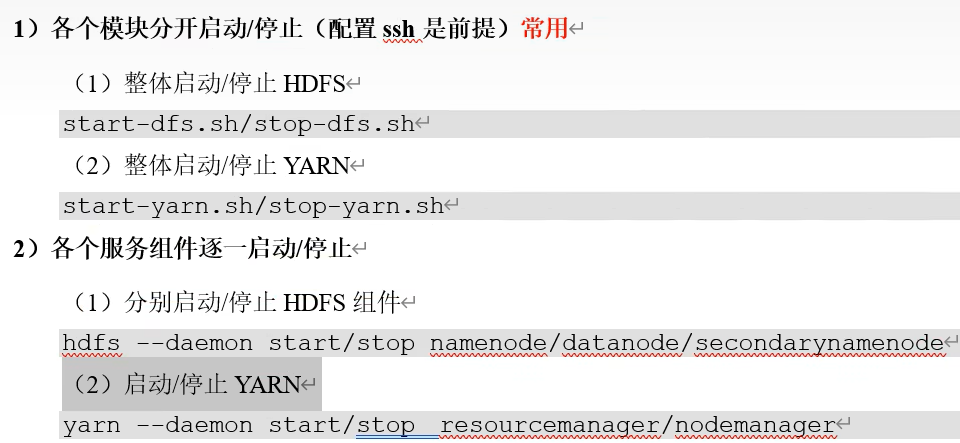
10.集群启动/停止方式总结
引自尚硅谷教程p35
11.配置历史服务器
1)为了查看程序的历史运行情况,需要配置历史服务器。首先进入hadoop102虚拟机 /opt/software/hadoop-3.2.3/etc/hadoop/ 路径内,更改 mapred-site.xml 文件,添加如下代码
<!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop102:10020</value> </property> <!-- 历史服务器 web 端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop102:19888</value> </property>
2)保存退出后输入命令:xsync mapred-site.xml 分发到其它虚拟机上。配置完成后如果yarn是开着的,需要把yarn关掉重新开启,如果yarn没有开,就直接启动yarn就可以了。启动成功后还需要在hadoop102的路径 /opt/software/hadoop-3.2.3/ 目录下输入命令: bin/mapred --daemon start historyserver 来启动历史服务器,启动成功后jps检查是否存在JobHistoryServer进程。至此,历史服务器配置完成,可以在http://hadoop102:19888/网站查看历史任务进程。
12.配置日志聚集
1)可以方便的查看到程序的运行详情,方便开发调试。首先进入到hadoop102虚拟机 /opt/software/hadoop-3.2.3/etc/hadoop 路径下,更改 yarn-site.xml 文件,添加如下代码
<!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://hadoop102:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为 7 天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
2)配置完成后保存退出,使用 xsync yarn-site.xml 分发,然后在hadoop102 下关闭历史服务器,输入命令:mapred --daemon stop historyserver ,然后进入hadoop关闭yarn再打开yarn,回到hadoop102 再打开历史服务器。
13.编写集群启停脚本和查看集群jps脚本
1)首先在hadoop102上进入 ~/bin/ 路径下,输入命令:vi myhadoop.sh ,(和xsync同一级目录)添加如下代码
#!/bin/bash if [ $# -lt 1 ] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== 启动 hadoop 集群 ===================" echo " --------------- 启动 hdfs ---------------" ssh hadoop102 "/opt/software/hadoop-3.2.3/sbin/start-dfs.sh" echo " --------------- 启动 yarn ---------------" ssh hadoop103 "/opt/software/hadoop-3.2.3/sbin/start-yarn.sh" echo " --------------- 启动 historyserver ---------------" ssh hadoop102 "/opt/software/hadoop-3.2.3/bin/mapred --daemon start historyserver" ;; "stop") echo " =================== 关闭 hadoop 集群 ===================" echo " --------------- 关闭 historyserver ---------------" ssh hadoop102 "/opt/software/hadoop-3.2.3/bin/mapred --daemon stop historyserver" echo " --------------- 关闭 yarn ---------------" ssh hadoop103 "/opt/software/hadoop-3.2.3/sbin/stop-yarn.sh" echo " --------------- 关闭 hdfs ---------------" ssh hadoop102 "/opt/software/hadoop-3.2.3/sbin/stop-dfs.sh" ;; *) echo "Input Args Error..." ;; esac
输入命令:chmod 777 myhadoop.sh 赋予其执行权限,然后执行命令:myhadoop.sh stop ,查看其执行情况是否关闭成功,然后执行命令:myhadoop.sh start ,查看是否启动成功。
2)现在开始编写查看集群所有虚拟机java进程的脚本,同样进入hadoop102虚拟机 ~/bin/ 目录下,输入命令:vi jpsall ,添加如下代码
#!/bin/bash for host in hadoop102 hadoop103 hadoop104 do echo =============== $host =============== ssh $host jps done
添加完成后输入命令:chmod 777 jpsall 来赋予脚本执行权限,然后用xsync分发myhadoop.sh 和jpsall两个脚本,使其在任何一台虚拟机上都可以运行。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义