pandas - 案例(美国各州人口普查)
需求:
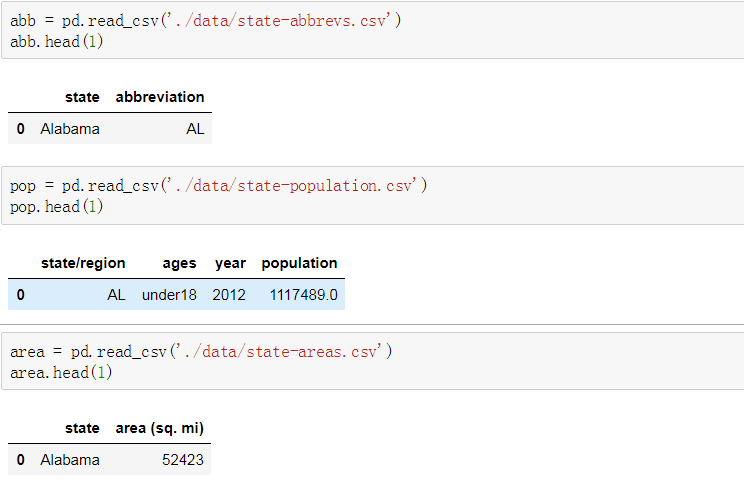
- 导入文件,查看原始数据
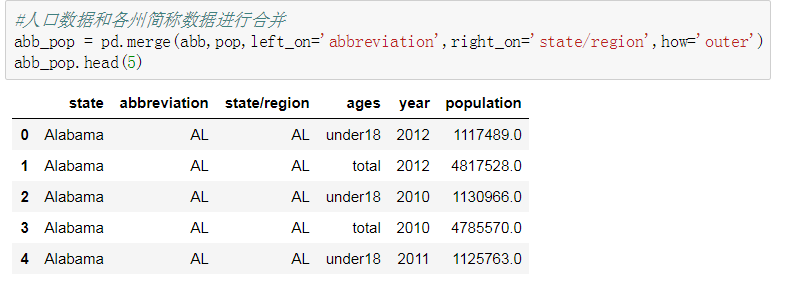
- 将人口数据和各州简称数据进行合并
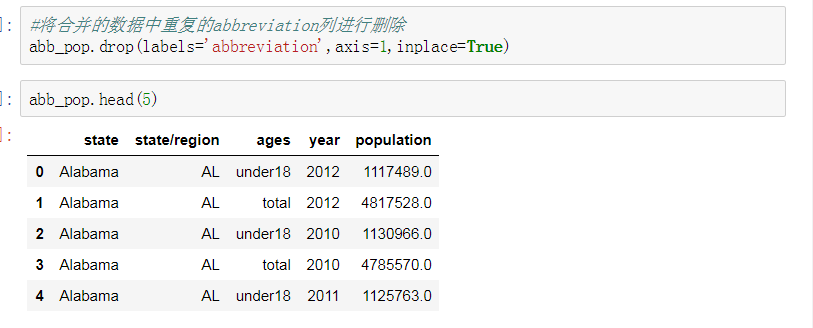
- 将合并的数据中重复的abbreviation列进行删除
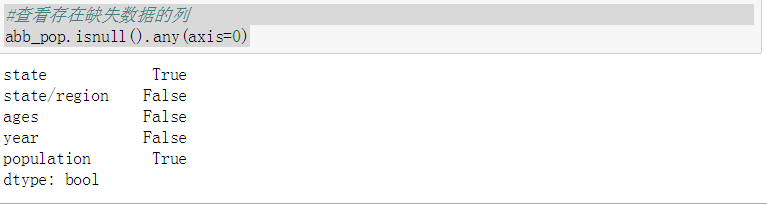
- 查看存在缺失数据的列
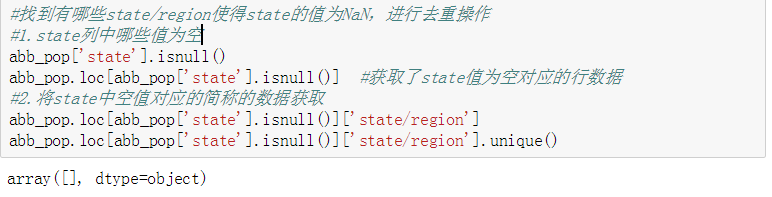
- 找到有哪些state/region使得state的值为NaN,进行去重操作
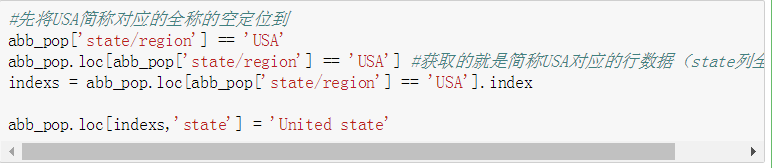
- 为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN
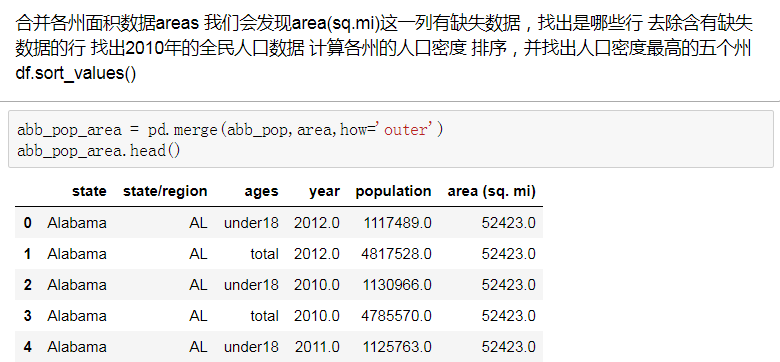
- 合并各州面积数据areas
- 我们会发现area(sq.mi)这一列有缺失数据,找出是哪些行
- 去除含有缺失数据的行
- 找出2010年的全民人口数据
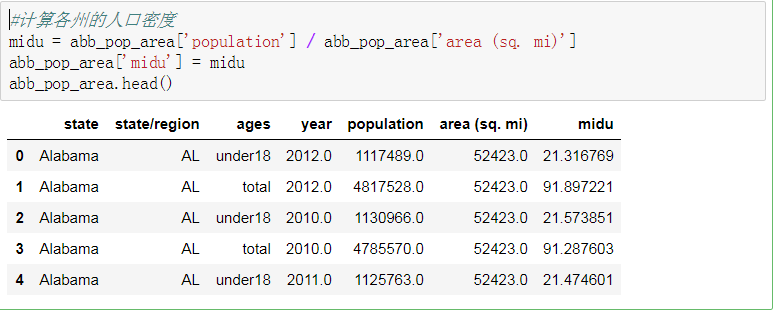
- 计算各州的人口密度
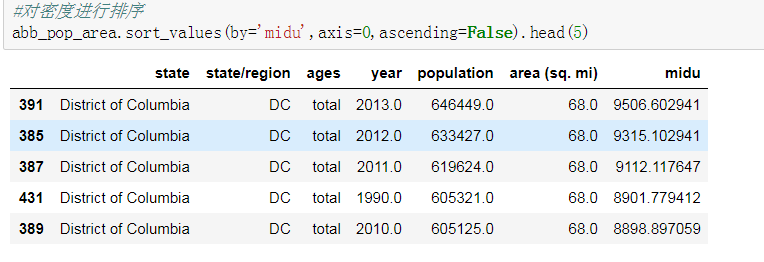
- 排序,并找出人口密度最高的五个州 df.sort_values()
1. 导入文件,查看原始数据
import numpy as np from pandas import DataFrame,Series import pandas as pd
2. 将人口数据和各州简称数据进行合并
3. 将合并的数据中重复的abbreviation列进行删除
4. 查看存在缺失数据的列
5. 找到有哪些state/region使得state的值为NaN,进行去重操作
6. 为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN

7. 合并各州面积数据areas
8. 我们会发现area(sq.mi)这一列有缺失数据,找出是哪些行

9. 去除含有缺失数据的行

10. 找出2010年的全民人口数据

11. 计算各州的人口密度
12. 排序,并找出人口密度最高的五个州 df.sort_values()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号