

Python--2 入门
Python 2.x与3.x 版本简介
目前市场上有两个Python的版本并存着, 分别是Python 2.x和Python3.x
新的Python程序建议侂用Python 3创版本的语法
• Python 2.x是过去的版本
o 解释器名称是 python
• Python 3.x是现在和未来主流的版本
o 解释器名称是python3
o 相对于Python的早期版本, 这是一个较大的升级
o 为了不带入过多的累赘, Python 3.0在设计的时候没有考虑向下兼容
. 许多早期Python版本设计的程序都无法在Python3.0上正常执行
o Python 3.0发布于2008年
o 到目前为止, Python3.0的稳定版本已经有很多年了
• Python 3.3发布于2012
• Python 3.4发布于2014
• Python 3.5发布于2015
. 为了照顾现有的程序, 官方提供了一个过渡版本-- Python 2.6
o 基本使用了Python 2.x的语法和库
o 同时考虑了向Python3.0的迁移, 允许使用部分Python3.0的语法与函数
2010年中推出的Python2.7被确定为最后一个Python2.x版本
提示:如果开发时, 无法立即使用Python 3.0 (还有极少的第三方库不支持 3.0 的语法), 建议先使用Python 3.0版本进行开发
.然后使用Python 2.6、 Python 2.7来执行, 并且做一些兼容性处理。
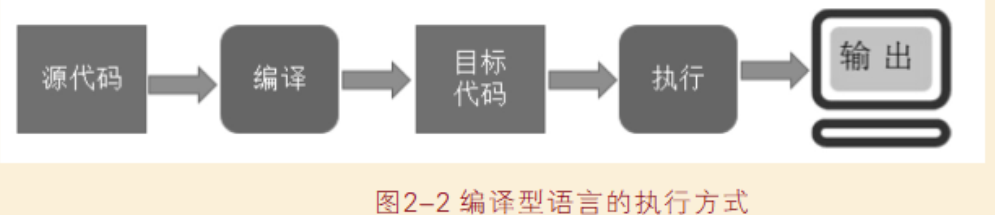
解释型语言:边读源程序边执行。
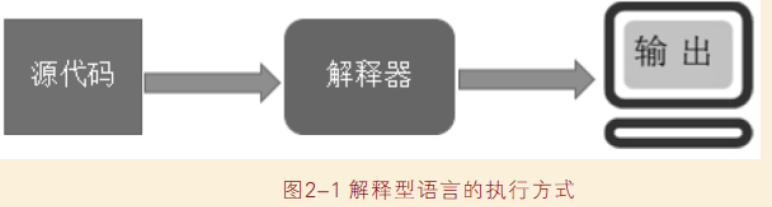
编译型语言:将源代码编译成目标代码后再执行,以后再执行时不需要编译。


1 1 C:\Users\kongd>python 2 2 Python 3.6.2 (v3.6.2:5fd33b5, Jul 8 2017, 04:57:36) [MSC v.1900 64 bit (AMD64)] on win32 3 3 Type "help", "copyright", "credits" or "license" for more information. 4 4 >>> print('hello world') 5 5 hello world 6 6 >>> 7 7 8 8 hello.py: 9 9 #!/usr/bin/python 10 10 print('hello world')
- #!/usr/bin/python指定解释器(Linux)也可以使用#!/usr/bin/env python
- 两者区别:#!/usr/bin/python是告诉操作系统执行这个脚本的时候,调用/usr/bin下的python解释器;
-
- #!/usr/bin/env python这种用法是为了防止操作系统用户没有将python装在默认的/usr/bin路径里。当系统看到这一行的时候,首先会到env设置里查找python的安装路径,再调用对应路径下的解释器程序完成操作。
1 "D:\Program Files\Python36\python.exe" E:/python/day1/hello.py 2 hello world


关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
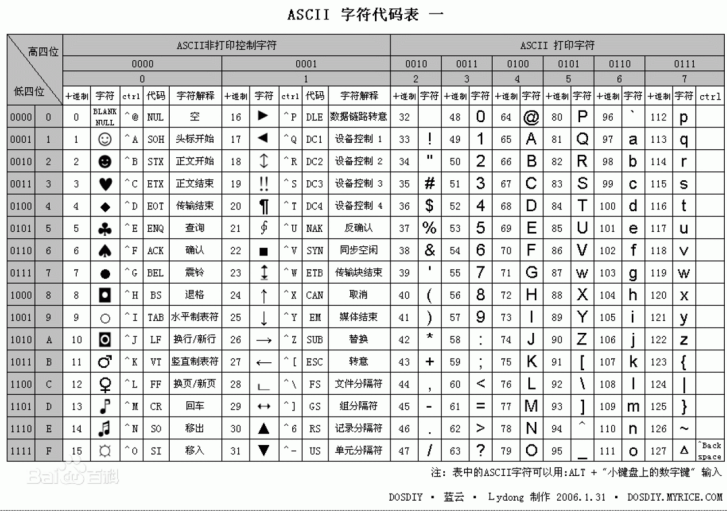
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
-
- Python内部提供的模块
- 业内开源的模块
- 程序员自己开发的模块
- 示例:判断用户名密码输入是否正确
1 import getpass 2 3 user = input('input username: ') 4 pwd = getpass.getpass('input password: ') 5 6 if user == 'xp' and pwd == 'xp0001': 7 print("welcome %s" % user) 8 else: 9 print("Error username or password")
创建py文件注意事项:
- 程序就是用来处理数据的,而变量就是用来存储数据的
变量就是代表某个数据(值)的名称。程序是用来处理数据的,而变量是用来存储数据的。
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
1 import keyword 2 print(keyword.kwlist) 3 "D:\Program Files\Python36\python.exe" E:/python/day1/lesson.py 4 ['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
2、变量命名
1 name = 'tom' 2 3 print(id(name)) 4 print(type(name)) 5 3127464526712 6 <class 'str'>
定义一个变量,为变量赋值,在内存中开辟一个空间保存变量值
- 在内存中创建了一个’ABC’的字符串;
- 在内存中创建了一个名为a的变量,并把它指向’ABC’。



为了更充分的利用内存空间以及更有效率的管理内存,变量是有不同的类型的,如下所示:
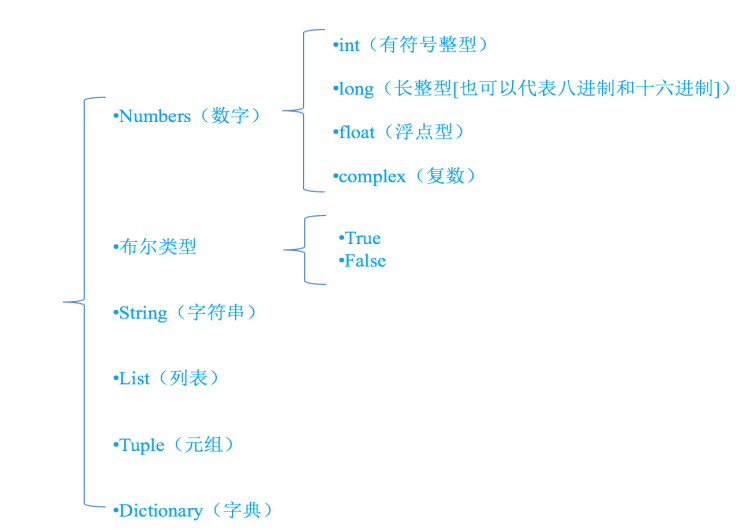
•怎样知道一个变量的类型呢?
◦在python中,只要定义了一个变量,而且它有数据,那么它的类型就已经确定了,不需要咱们开发者主动的去说明它的类型,系统会自动辨别
◦可以使用type(变量的名字),来查看变量的类型
type显示变量类型,在交互模式中输入变量名,显示变量值
>>> name="tom" >>> type(name) <class 'str'> >>> num=100 >>> type(num) <class 'int'> >>> list1=[1,2,3] >>> type(list1) <class 'list'> >>> tuple1=(1,2,3) >>> type(tuple1) <class 'tuple'> >>> dict1={"name":"tom","age":21} >>> type(dict1) <class 'dict'>
- 输出
1 >>> print("hello world") 2 hello world
1 >>> print('The quick brown fox', 'jumps over', 'the lazy dog') 2 The quick brown fox jumps over the lazy dog
print()会依次打印每个字符串,遇到逗号“,”会输出一个空格,因此,输出的字符串是这样拼起来的:
1 >>> score=100 2 >>> print("my english score is %d"%score) 3 my english score is 100
%用法
1、整数的输出
%o —— oct 八进制
%d —— dec 十进制
%x —— hex 十六进制
>>> print('%o' % 20) 24 >>> print('%d' % 20) 20 >>> print('%x' % 20) 14
2、浮点数输出
(1)格式化输出
%f ——保留小数点后面六位有效数字
%.3f,保留3位小数位
%e ——保留小数点后面六位有效数字,指数形式输出
%.3e,保留3位小数位,使用科学计数法
%g ——在保证六位有效数字的前提下,使用小数方式,否则使用科学计数法
%.3g,保留3位有效数字,使用小数或科学计数法
>>> print('%f' % 1.11) # 默认保留6位小数 1.110000 >>> print('%.1f' % 1.11) # 取1位小数 1.1 >>> print('%e' % 1.11) # 默认6位小数,用科学计数法 1.110000e+00 >>> print('%.3e' % 1.11) # 取3位小数,用科学计数法 1.110e+00 >>> print('%g' % 1111.1111) # 默认6位有效数字 1111.11 >>> print('%.7g' % 1111.1111) # 取7位有效数字 1111.111 >>> print('%.2g' % 1111.1111) # 取2位有效数字,自动转换为科学计数法 1.1e+03
(2)内置round()
round(number[, ndigits])
参数:
number - 这是一个数字表达式。
ndigits - 表示从小数点到最后四舍五入的位数。默认值为0。
返回值
该方法返回x的小数点舍入为n位数后的值。
round()函数只有一个参数,不指定位数的时候,返回一个整数,而且是最靠近的整数,类似于四舍五入,当指定取舍的小数点位数的时候,一般情况也是使用四舍五入的规则,但是碰到.5的情况时,如果要取舍的位数前的小数是奇数,则直接舍弃,如果是偶数则向上取舍。
注:“.5”这个是一个“坑”,且python2和python3出来的接口有时候是不一样的,尽量避免使用round()函数吧
3、字符串输出
%s
%10s——右对齐,占位符10位
%-10s——左对齐,占位符10位
%.2s——截取2位字符串
%10.2s——10位占位符,截取两位字符串
>>> print('%s' % 'hello world') # 字符串输出 hello world >>> print('%20s' % 'hello world') # 右对齐,取20位,不够则补位 hello world >>> print('%-20s' % 'hello world') # 左对齐,取20位,不够则补位 hello world >>> print('%.2s' % 'hello world') # 取2位 he >>> print('%10.2s' % 'hello world') # 右对齐,取2位 he >>> print('%-10.2s' % 'hello world') # 左对齐,取2位 he
4、 其他
(1)字符串格式代码

(2)常用转义字符

format用法
相对基本格式化输出采用‘%’的方法,format()功能更强大,该函数把字符串当成一个模板,通过传入的参数进行格式化,并且使用大括号‘{}’作为特殊字符代替‘%’
位置匹配
(1)不带编号,即“{}”
(2)带数字编号,可调换顺序,即“{1}”、“{2}”
(3)带关键字,即“{a}”、“{tom}”
>>> print('{} {}'.format('hello','world')) # 不带字段 hello world >>> print('{0} {1}'.format('hello','world')) # 带数字编号 hello world >>> print('{0} {1} {0}'.format('hello','world')) # 打乱顺序 hello world hello >>> print('{1} {1} {0}'.format('hello','world')) world world hello >>> print('{a} {tom} {a}'.format(tom='hello',a='world')) # 带关键字 world hello world
>>> '{0}, {1}, {2}'.format('a', 'b', 'c') 'a, b, c' >>> '{}, {}, {}'.format('a', 'b', 'c') # 3.1+版本支持 'a, b, c' >>> '{2}, {1}, {0}'.format('a', 'b', 'c') 'c, b, a' >>> '{2}, {1}, {0}'.format(*'abc') # 可打乱顺序 'c, b, a' >>> '{0}{1}{0}'.format('abra', 'cad') # 可重复 'abracadabra' 通过位置匹配
>>> 'Coordinates: {latitude}, {longitude}'.format(latitude='37.24N', longitude='-115.81W') 'Coordinates: 37.24N, -115.81W' >>> coord = {'latitude': '37.24N', 'longitude': '-115.81W'} >>> 'Coordinates: {latitude}, {longitude}'.format(**coord) 'Coordinates: 37.24N, -115.81W'
>>> c = 3-5j >>> ('The complex number {0} is formed from the real part {0.real} ' ... 'and the imaginary part {0.imag}.').format(c) 'The complex number (3-5j) is formed from the real part 3.0 and the imaginary part -5.0.' >>> class Point: ... def __init__(self, x, y): ... self.x, self.y = x, y ... def __str__(self): ... return 'Point({self.x}, {self.y})'.format(self=self) ... >>> str(Point(4, 2)) 'Point(4, 2)'
>>> >>> coord = (3, 5) >>> 'X: {0[0]}; Y: {0[1]}'.format(coord) 'X: 3; Y: 5' >>> a = {'a': 'test_a', 'b': 'test_b'} >>> 'X: {0[a]}; Y: {0[b]}'.format(a) 'X: test_a; Y: test_b'
- 输入
1 >>> name = input() 2 Mike 3 >>> name 4 'Mike'
1 >>> name = input("请输入你的姓名:") 2 请输入你的姓名:Tom 3 >>> name 4 'Tom'
1 Python2中的raw_input: 2 [root@localhost ~]# python2 3 Python 2.7.5 (default, Nov 6 2016, 00:28:07) 4 [GCC 4.8.5 20150623 (Red Hat 4.8.5-11)] on linux2 5 Type "help", "copyright", "credits" or "license" for more information. 6 >>> user = raw_input("please input your name: ") 7 please input your name: ZhangSan 8 >>> user 9 'ZhangSan' 10 >>> type(user) 11 <type 'str'> 12 >>> num = input("num: ") 13 num: 100+99 14 >>> num 15 199 16 >>> type(num) 17 <type 'int'>
1 #!/usr/bin/env python 2 3 #1. 提示用户输入信息 4 name = input("请输入姓名:") 5 qq = input("请输入QQ:") 6 tel = input("请输入手机号码:") 7 email = input("请输入邮箱:") 8 addr = input("请输入公司地址:") 9 10 #2. 从相应的变量中取出数据,然后进行打印 11 print("=======================") 12 print("姓名:%s"%name) 13 print("QQ:%s"%qq) 14 print("手机号码:%s"%tel) 15 print("邮箱:%s"%email) 16 print("公司地址:%s"%addr) 17 print("=======================") 18
#!/usr/bin/env python #1. 提示用户输入信息 name = input("请输入姓名:") qq = input("请输入QQ:") tel = input("请输入手机号码:") email = input("请输入邮箱:") addr = input("请输入公司地址:") #2. info变量,通过字符串拼接完成输出 info=''' ========================== 姓名:''' + name +''' QQ:''' + qq + ''' 手机号码:''' + tel + ''' 邮箱:''' + email + ''' 公司地址:'''+ addr + ''' ========================== ''' #3. 打印 print(info)
#!/usr/bin/env python #1. 提示用户输入信息 name = input("请输入姓名:") qq = input("请输入QQ:") tel = input("请输入手机号码:") email = input("请输入邮箱:") addr = input("请输入公司地址:") #2. info变量,通过%完成输出 info=''' ========================== 姓名:%s QQ:%s 手机号码:%s 邮箱:%s 公司地址:%s ========================== ''' %(name,qq,tel,email,addr) #3. 打印 print(info)
#!/usr/bin/env python #1. 提示用户输入信息 name = input("请输入姓名:") qq = input("请输入QQ:") tel = input("请输入手机号码:") email = input("请输入邮箱:") addr = input("请输入公司地址:") #2. info变量,通过format位置匹配输出 info=''' ========================== 姓名:{0} QQ:{1} 手机号码:{2} 邮箱:{3} 公司地址:{4} ========================== ''' .format(name,qq,tel,email,addr) #3. 打印 print(info)
#!/usr/bin/env python #1. 提示用户输入信息 name = input("请输入姓名:") qq = input("请输入QQ:") tel = input("请输入手机号码:") email = input("请输入邮箱:") addr = input("请输入公司地址:") #2. info变量,通过format名称匹配输出 info=''' ========================== 姓名:{name} QQ:{qq} 手机号码:{tel} 邮箱:{email} 公司地址:{addr} ========================== ''' .format(name=name,qq=qq,tel=tel,email=email,addr=addr) #3. 打印 print(info)
age = 22
‘’或“”注意:只能是英文输入的引号。
True或False
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算,今天我们暂只学习算数运算、比较运算、逻辑运算、赋值运算
算数运算
以下假设变量:a=10,b=20

比较运算
以下假设变量:a=10,b=20

注意:<>是python2中的用法,python3已经移除。
赋值运算
以下假设变量:a=10,b=20

逻辑运算

Python成员运算符
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组
|
运算符 |
描述 |
实例 |
|
in |
如果在指定的序列中找到值返回True,否则返回False。 |
x 在 y序列中 , 如果x在y序列中返回True。 |
|
not in |
如果在指定的序列中没有找到值返回True,否则返回False。 |
x 不在 y序列中 , 如果x不在y序列中返回True。 |
Python身份运算符
身份运算符用于比较两个对象的存储单元
|
运算符 |
描述 |
实例 |
|
is |
is是判断两个标识符是不是引用自一个对象 |
x is y, 如果 id(x) 等于 id(y) , is 返回结果 1 |
|
is not |
is not是判断两个标识符是不是引用自不同对象 |
x is not y, 如果 id(x) 不等于 id(y). is not 返回结果 1 |
作业:
1、编写程序,完成以下要求
1)提示用户进行输入数据
2)获取用户的数据(需要获取2个)
3)对获取的两个数据进行加减乘除运算,并输出结果
2、编写程序,完成下列信息的输出
=============================================
= 欢迎进入到身份认证系统V1.0
= 1. 登录
= 2. 退出
= 3. 认证
= 4. 修改密码
=============================================

 浙公网安备 33010602011771号
浙公网安备 33010602011771号