Understanding Skylake's CHA
缓存一致性
CHA的出现是为了协调通信,解决缓存一致性的问题,也称为代理agent。
内存中的一份数据在处理器的多个core的cache line中存在的时候,每个core称为一个client。
为了实现缓存一致性必须有两个属性,第一写传播,第二写操作序列事务化。
总体意思是一个client对cache的操作必须按照顺序传播到所有其他的client。
实现缓存一致性的两种方法
- Snooping,侦听方法;可以理解成广播方法,一个client的请求和响应必须广播到所有的client上,缺点是client多的时候,要求的总线带宽比较大,优点是更快,更加简单。目前广泛是用在核心少的处理器的缓存一致性机制的实现里面。
- Directories Based,基于目录的方法;可以理解成基于请求的方法,需要维护一致性的cache被放在一个dir中,client发出请求,被允许之后,dir更新,其他地方的都置无效。
Skylake的CHA
首先要说的是Skylake的设计通过硬件缓存实现唯一client为cache负责基本上避免了cache line更新导致的大规模通信。
其次应该是实现了Dir Based的缓存一致性的方法。
最后CHA实现了6个UPI的通信协议
请求/侦听/应答/写回/不一致标准/不一致通行
Request/Snoop/Response/Write Back/Non-Coherent Statdard/Non-Coherent Bypass
CHA的作用
主要通过定位和仲裁数据减少die[client]之间的通信时间
CHA包含四个模块
- Coherency Agent 简称CA[分布存在,分布服务] 一致性代理,通常用作LLC/Core与Mesh网的接口
- Home Agent简称HA[分布存在,分布服务] 将读写请求排序保证内存一致性,所有内存访问都经过这个agent
- 1.35MB LLC[分布存在,全局服务]每个分片处在每个Core旁边
- Snoop Filter[分布存在,全局服务]可以称为缓存的缓存,维护缓存与所有core的对应关系
CHA的交互
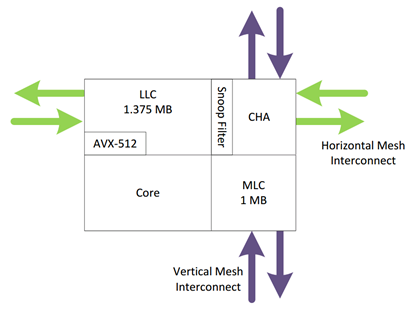
这里的LLC总的大小是1.375M,但是每个核心上的肯定只是一个分片。
Snoop Filter 是1.5M用来为LLC跟踪Cache line属于具体哪一个Core。避免在多核心之间反复snoop寻找。
因为这里的LLC和MLC缓存的数据是互相不包含的,也称为non inclusive的。所以Snoop Filter也跟踪当前Core的MLC的Cache Line。
当CHA收到一个请求的时候会同时访问LLC和Snoop Filter,这样当前Moudule的所有的Cache Line就都在CHA的掌握之中了。
万事走心 精益求美

 浙公网安备 33010602011771号
浙公网安备 33010602011771号