Hotchips 33 学习:Intel 数据中心计算卡Ponte Vecchio
Xe分为四个系列;

用模块化的方式组合:
Xe HPC的Xe Core:里面有8个Vector Engine和8个XMX Engine,以及8个深度脉动阵列;512KiB L1 Cache;
每个Vector Engine是512bit的,1个时钟周期可以完成512/32=16个FMA的操作;
因此1个Xe Core的IPC是8*16*2=256 FP32 FLPS;
每个Matrix Engine是4096bit的,IPC是上面的8倍,但是精度降低为TF32,因此IPC是2048TF32 FLOPS;

每个Xe Slice里面有16个Xe Core,另外还包含16个光线追踪的单元,和1个Hardware Context的模块;

每个Xe Stack是4个Xe Slice组成的;

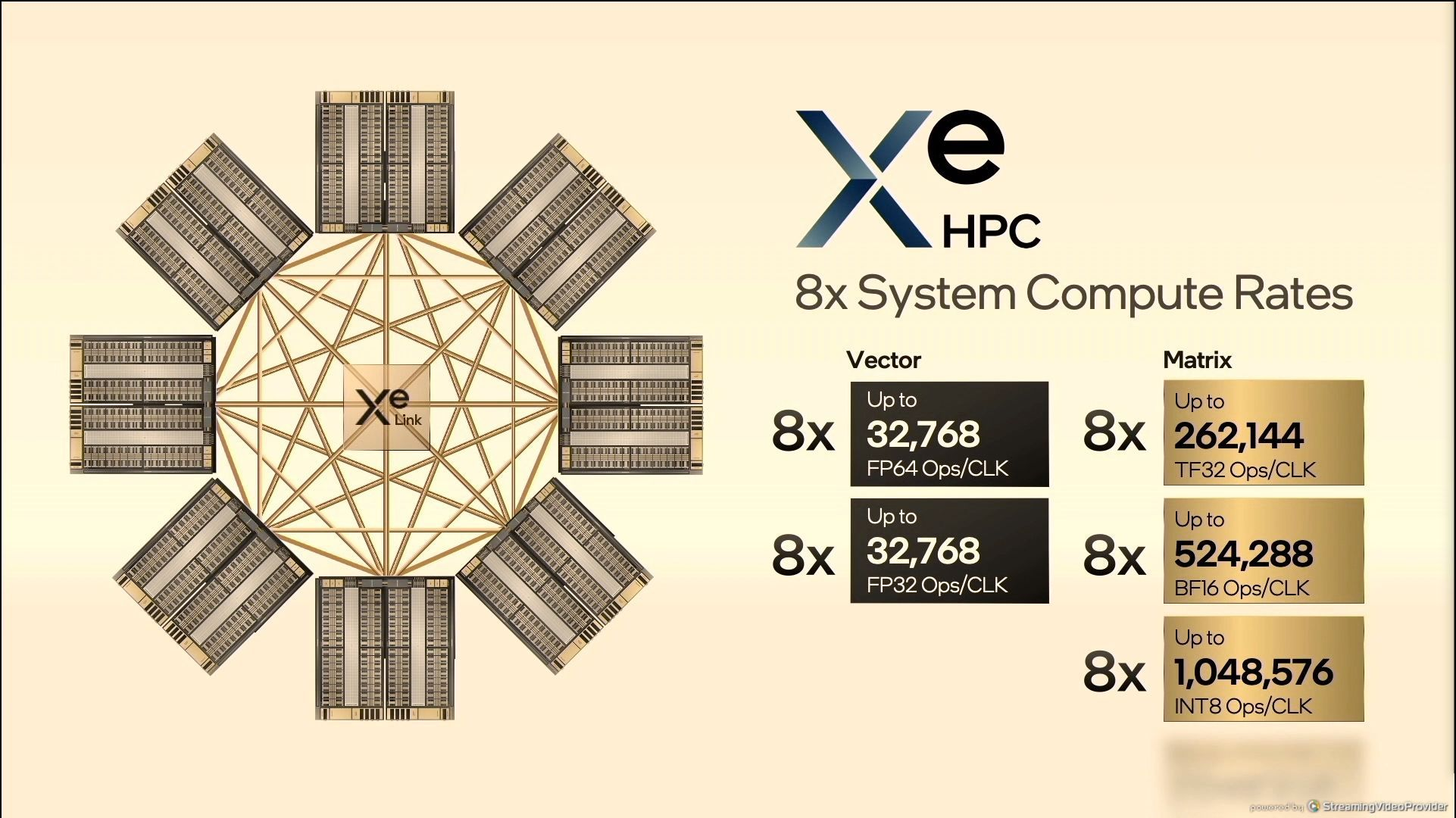
每个Tile可以是一个2-Stack的形式互联起来;

8个2-Stack的卡可以通过Xe Link形成全互联,那么IPC是8卡*2-Stack*4Slick*16Core*256 FP32 FLOPS=8*32768 FP32 FLOPS;
这个codename是取自意大利佛罗伦萨最古老的桥梁大约AD1345年,可以类比赵州桥的知名度大约AD600年;
计算Tile是TSMC N5制造,这里每个Tile上8个Core,应该就是1个Tile就是1个slice的意思。

Base Tile是Intel N7制造,功能可能相当于是硅中介

Xe Link Tile是TSMC N7,每个Tile支持8个Links;

其次是形态,OAM形态的卡,支持四卡互联,也支持4卡+2CPU的小计算系统;

单卡的性能数据,计算性能,显存带宽,互联带宽;
上面计算得到单个2-Stack的Tile的IPC是32768FP 32 FPLOPS,假设基频是X,那么X=45TFLOPS/32768=1.37GHz;

假设内存采用的是8个1024bit位宽的HBM2e,那么假设基频是Y,Y=5TB/8/1024=0.61GHz;(?感觉不应该这么低)。
上图8个应该是HBM2e,另外两个竖着的可能是Xe Link,中间部分就是Tile组成的计算单元。

如果单卡的算力是45TFPOS,那么6卡应该是270FLOPS,两个CPU按照10计算吧。
1E=1000P=10^6TFLOPs,那么大概需要10^6/280=3500台服务器。
参考文献:
万事走心 精益求美

 浙公网安备 33010602011771号
浙公网安备 33010602011771号