python+fiddler下载vip视频 && ts视频可合并
如果你只想在线看视频可以去看这篇博客:python实现通过指定浏览器免费观看vip视频
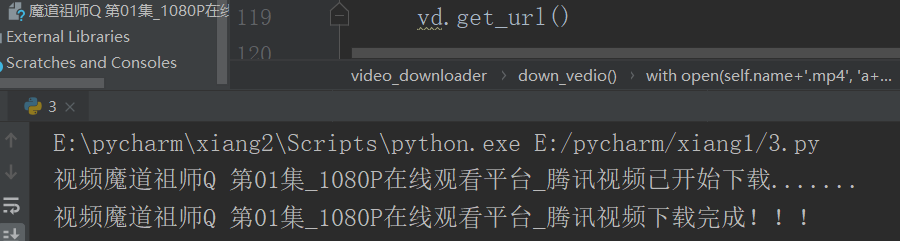
先看一下我们程序运行的结果
我们要解析的接口就是(就是这个“接口+视频地址”可以解析出vip视频,但是你只能看,不能下载,这里我们讲怎么去通过python下载它)
self.api = 'http://jx.idc126.net/jx/?url='
1、我们打开fiddler抓包工具,然后打开解析视频页面,对其进行抓包


2、我们通过分析fiddler抓取的数据包可以找出来一个post请求的数据包,它的响应数据里面有一个m3u8文件
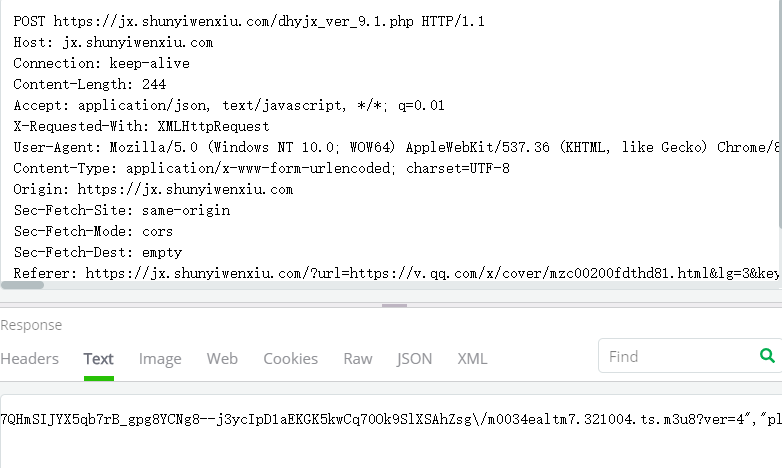
3、这个文件是干什么的呢,我们下载下来看看(或者你可以不下载,通过request来得到它)
下面给出一部分
#EXTM3U #EXT-X-VERSION:3 #EXT-X-MEDIA-SEQUENCE:0 #EXT-X-TARGETDURATION:13 #EXT-X-PLAYLIST-TYPE:VOD #EXTINF:11.960, 00_m0034ealtm7.321004.1.ts?index=0&start=0&end=11960&brs=0&bre=1346643&ver=4&token=417e80a5285647da52a3ce86f2f3de94 #EXTINF:11.640, 01_m0034ealtm7.321004.1.ts?index=1&start=11960&end=23600&brs=1346644&bre=2687835&ver=4&token=b873fda12617909f994f8047cb8e6153 #EXTINF:11.520, 02_m0034ealtm7.321004.1.ts?index=2&start=23600&end=35120&brs=2687836&bre=4974103&ver=4&token=150a9d4990a7730f645144382b2fa55f #EXTINF:10.240, 03_m0034ealtm7.321004.1.ts?index=3&start=35120&end=45360&brs=4974104&bre=8842955&ver=4&token=9eeb5378d61d9f2b1abbc0e001d4412c #EXTINF:10.040, 04_m0034ealtm7.321004.1.ts?index=4&start=45360&end=55400&brs=8842956&bre=11803391&ver=4&token=47a6828e844862815e2e5ac8420dbe17
4、很懵,不知道这是什么,那我们先去看看抓取到的视频数据包,你把它的请求头在浏览器中打开就会下载一个ts文件,这是一个视频文件
它不全,只是视频的一部分(几十秒,或十几秒)
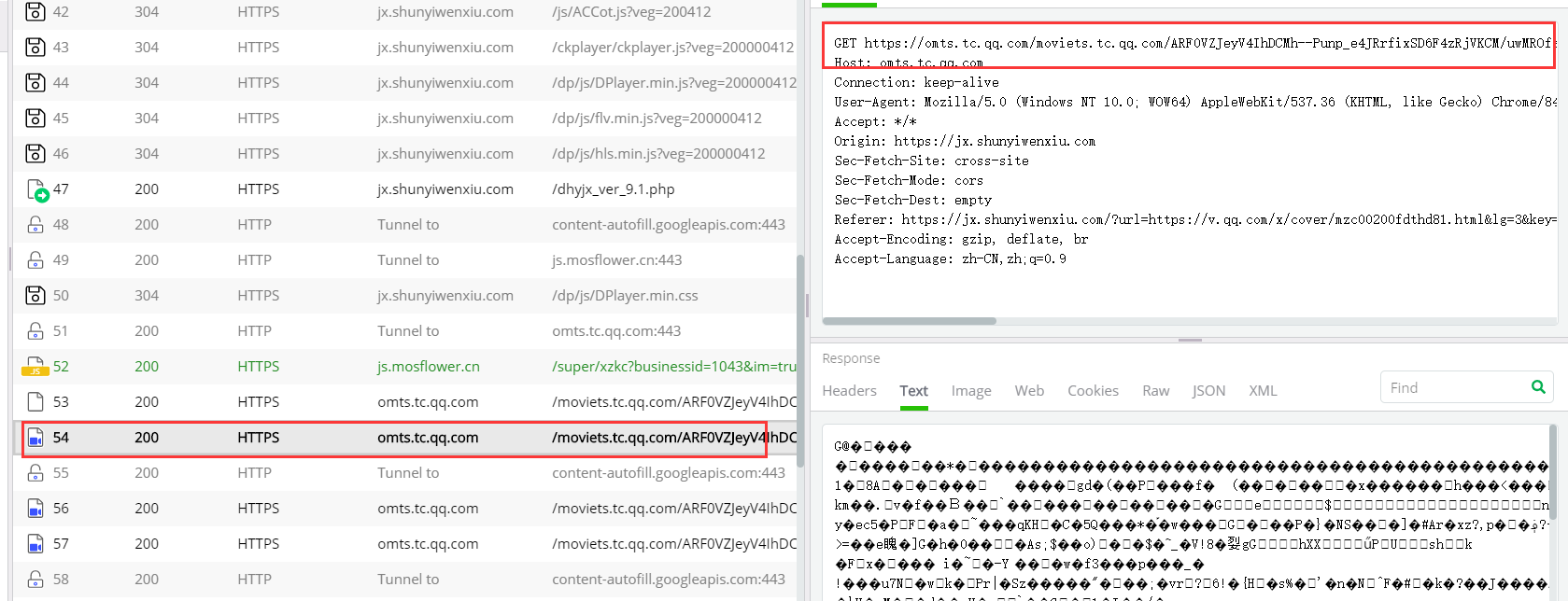
5、我们可以从上图中看到这样的视频数据包不止一个,那么这个时候就很难受了,一个视频十几秒,难不成一个大视频我们分成无数的小视频去看(oh!no!)
这个时候我就在想了,可以可以把多个ts视频合并成一个,答案是可以(yes!yes!yes!)
既然这样,我们就可以通过“ab”方式去到所有ts小视频写入视频内容到一个mp4文件里面
这样的话我们就去看看这些ts小视频的url有没有什么规律(正常思维嘛^_^)
https://omts.tc.qq.com/moviets.tc.qq.com/ARF0VZJeyV4IhDCMh--Punp_e4JRrfixSD6F4zRjVKCM/uwMROfz2r5xhIaQXGdGnC2df64gZXNTMZvhtgq7maR8xuHpV/dSIdb30WOoG1mXzTAY4_dppqT81rMbPF0VeWLtyDlV_netQkbPmwLbZo-p30yJ8n3nObUSaqJGp_xD0NfrgEdzFdufZ7QHmSIJYX5qb7rB_gpg8YCNg8--j3ycIpD1aEKGK5kwCq70Ok9SlXSAhZsg/00_m0034ealtm7.321004.1.ts?index=0&start=0&end=11960&brs=0&bre=1346643&ver=4&token=417e80a5285647da52a3ce86f2f3de94 HTTP/1.1
https://omts.tc.qq.com/moviets.tc.qq.com/ARF0VZJeyV4IhDCMh--Punp_e4JRrfixSD6F4zRjVKCM/uwMROfz2r5xhIaQXGdGnC2df64gZXNTMZvhtgq7maR8xuHpV/dSIdb30WOoG1mXzTAY4_dppqT81rMbPF0VeWLtyDlV_netQkbPmwLbZo-p30yJ8n3nObUSaqJGp_xD0NfrgEdzFdufZ7QHmSIJYX5qb7rB_gpg8YCNg8--j3ycIpD1aEKGK5kwCq70Ok9SlXSAhZsg/01_m0034ealtm7.321004.1.ts?index=1&start=11960&end=23600&brs=1346644&bre=2687835&ver=4&token=b873fda12617909f994f8047cb8e6153 HTTP/1.1
https://omts.tc.qq.com/moviets.tc.qq.com/ARF0VZJeyV4IhDCMh--Punp_e4JRrfixSD6F4zRjVKCM/uwMROfz2r5xhIaQXGdGnC2df64gZXNTMZvhtgq7maR8xuHpV/dSIdb30WOoG1mXzTAY4_dppqT81rMbPF0VeWLtyDlV_netQkbPmwLbZo-p30yJ8n3nObUSaqJGp_xD0NfrgEdzFdufZ7QHmSIJYX5qb7rB_gpg8YCNg8--j3ycIpD1aEKGK5kwCq70Ok9SlXSAhZsg/02_m0034ealtm7.321004.1.ts?index=2&start=23600&end=35120&brs=2687836&bre=4974103&ver=4&token=150a9d4990a7730f645144382b2fa55f HTTP/1.1
6、视频链接很长,这里怎么找我就不去说了,直接说结果
上面视频链接前部分都一样,后半部分不同,但是后半部分来自于上面的那个m3u8文件中(找了半天,呼~~~~~)
7、这个时候我们就要去找一下视频链接前半部分在哪,这里还是说结果
视频链接前半部分就是m3u8文件的前半部分链接(很牛掰!!!)
8、找到现在可以说只要能获取m3u8文件和链接,那么所有问题都无了
那么我们就去分析一下m3u8这个文件链接在哪搞出来的
没错!就是最开始的post请求的响应文本
那么我们就去搞这个post请求的请求头
#post请求的url地址 POST http://jx.idc126.net/jx/api.php#post请求的参数
url=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fmzc00200fdthd81.html&referer=&ref=0&time=1596331710&type=&other=aHR0cHM6Ly92LnFxLmNvbS94L2NvdmVyL216YzAwMjAwZmR0aGQ4MS5odG1s&ios=
分析一下这个url(你可以多找几个这样的post请求对比着看)
我们的url参数就是我们要看的vip视频地址,time的值在“解析接口+vip视频地址”这个网页的html中,other的值不变就行

其实也不用问怎么找出来的,就一直找,,,,没什么说的
找完了,在程序中构造一个data的数据,然后一步一步进行就行
post+data----->m3u8链接+文件--------->搞出视频链接前半部分+后半部分--------->讲多个ts视频用ab方式写入一个文件
代码(爱奇艺/腾讯视频/优酷/芒果/土豆/乐视的播放链接都可以):
import requests,re,json,sys class video_downloader(): def __init__(self, url): self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36' } self.get_name(url) # self.server = 'https://omts.tc.qq.com/' self.api = 'http://jx.idc126.net/jx/?url=' self.get_url_api = 'http://jx.idc126.net/jx/api.php' self.url = url.split('#')[0] self.target = self.api + self.url self.s = requests.session() """ 函数说明:获取key、time、url等参数 Parameters: 无 Returns: 无 Modify: 2017-09-18 """ def get_name(self,url): res = requests.get(url, headers=self.headers) res.encoding = res.apparent_encoding html = res.text pattern1 = '<title>(.*?)</title>' self.name = re.search(pattern1, html).group(1) def get_key(self): req = self.s.get(url=self.target) req.encoding = 'utf-8' html = req.text pattern1 = "url':'(.*?)'" self.param_url = re.search(pattern1, html, re.S) limit = 0 if limit == 5: sys.exit(0) if self.param_url == None: self.get_key() limit = limit+1 else: self.param_url = self.param_url.group(1) pattern2 = "time':'(.*?)'" self.param_time = re.search(pattern2, html, re.S) if self.param_time == None: self.get_key() limit = limit+1 else: self.param_time = self.param_time.group(1) """ 函数说明:获取视频地址 Parameters: 无 Returns: video_url - 视频存放地址 Modify: 2017-09-18 """ def get_url(self): data = { 'time': self.param_time, 'other': 'aHR0cHM6Ly92LnFxLmNvbS94L2NvdmVyL216YzAwMjAwZmR0aGQ4MS5odG1s', 'url': self.param_url, 'type': '', 'ref': '0' } req = self.s.post(url=self.get_url_api,data=data) req.encoding = req.apparent_encoding #print(req.text) self.down_pre_url = json.loads(req.text)['url'] self.down_pre_url = self.down_pre_url.replace('\\','') req = self.s.get(self.down_pre_url) html = req.text # print(html) pattern1 = ',.(.*?)#' res = re.finditer(pattern1, html, re.S) self.update_url() print('视频{}已开始下载.......'.format(self.name)) for i in res: # print(i.group(1)) self.get_down_vedio(i.group(1)) self.down_vedio() print('视频{}下载完成!!!'.format(self.name)) ''' pattern1 = ',.(.*?)#' url_old = re.search(pattern1, html, re.S).group(1) index = url_old.find('start') url_new = url_old[0:index + 6] + '1' + url_old[index + 7:len(url_old)] print(self.down_pre_url) print(url_new) return url_new''' def get_down_vedio(self,down_suf_url): # print(self.down_pre_url[0:aim + 1]) self.vedio_url = self.down_pre_url+down_suf_url # print(self.vedio_url) def update_url(self): aim = 0 for i in range(0, len(self.down_pre_url) - 5): if self.down_pre_url[i - 1] == '/': aim = i - 1 self.down_pre_url = self.down_pre_url[0:aim + 1] def down_vedio(self): film = requests.get(self.vedio_url, headers=self.headers).content with open(self.name+'.mp4', 'a+b') as f: f.write(film) if __name__ == '__main__': url = 'https://v.qq.com/x/cover/mzc00200fdthd81.html' #vip视频链接 vd = video_downloader(url) vd.get_key() vd.get_url() # https://v.qq.com/x/cover/mzc00200fdthd81.html # http://www.iqiyi.com/w_19rqswhlx9.html?vfm=m_103_txsp
