python爬取酷我音乐
我去!!!我之后一定按照搜索方式下载歌曲~~~~~~~~~
1、首先打开我们本次主讲链接:http://www.kuwo.cn/
2、刚开始我就随便点了一个地方,然后开始在后台找歌曲的链接地址。但是这也使我分析页面分析的很复杂。因为像在酷我音乐,这样的模块都有一个pid,分析参数的时候找了半天还要找pid,,,结果发现这是一个固定值,那就没有意义了,因为pid是一个固定值我总不能只去下载这个模块里面的歌曲,,,想下载其他歌曲还要改代码,这样子就不行了。。。。所以还是从搜索框开始,搜索到哪首歌曲,然后去看看下载哪个歌手唱的

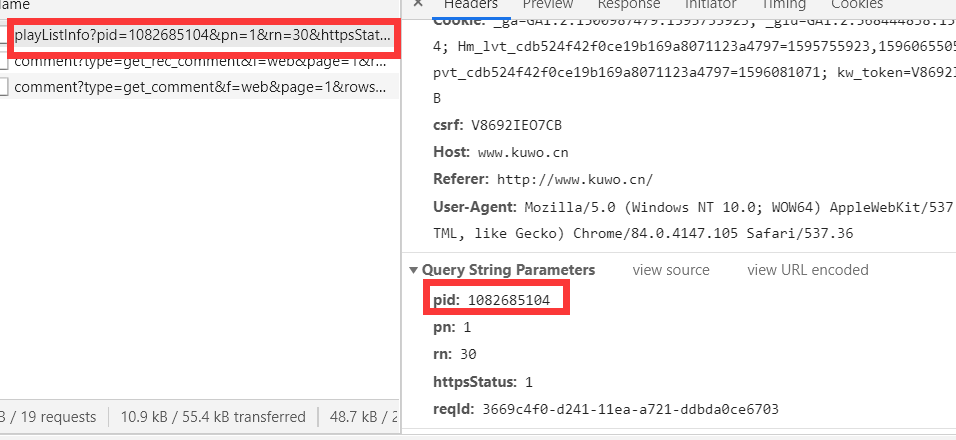
3、酷我很狡猾,当我随便搜索一首歌,然后找这首歌的数据包的时候,如果你用这个数据包的请求头直接在你的浏览器上访问会出现403等错误,反正就是访问不到。我找了半天也找不到,突然觉得酷我很牛掰。我去分析网易云/QQ音乐的时候都没有这个问题。
之后弄了半天才搞清楚,你只要加上一些请求头信息就可以访问成功了。。。。
看来是我太。。。了
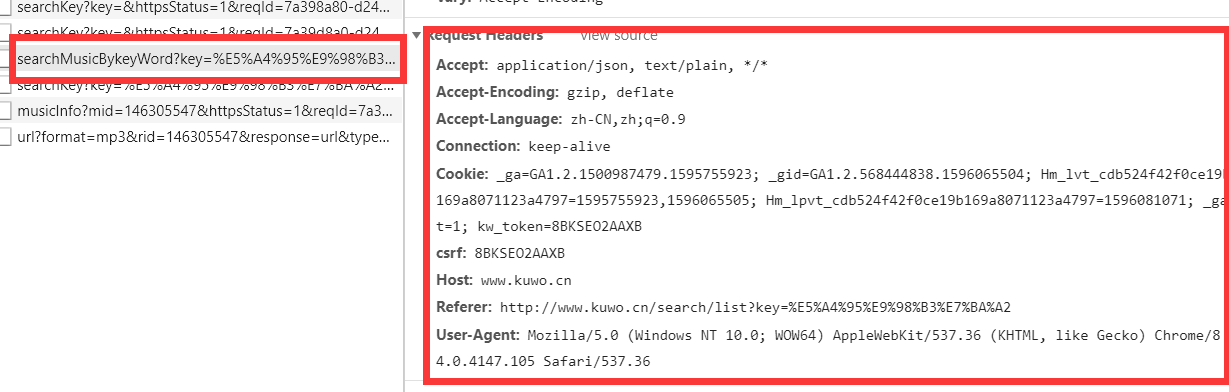
在pycharm上加上请求头,在访问就会成功。不只这个链接是这样,酷我的好多链接访问都要加上请求头(我giao~~~),搞懂这个之后下面就不是问题了
4、因为这个数据包内包含了你搜索歌曲的这一页所有的信息,所以我们要把它爬下来,以便到时候选择
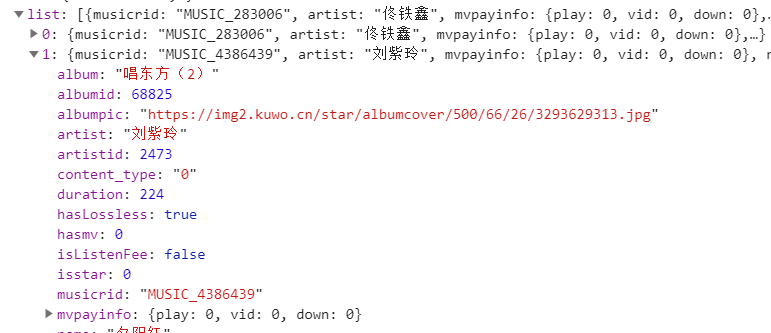
5、之后我们播放歌曲,然后分析一下歌曲的播放链接,下面图片上所显示数据包的url字段就是歌曲的url地址
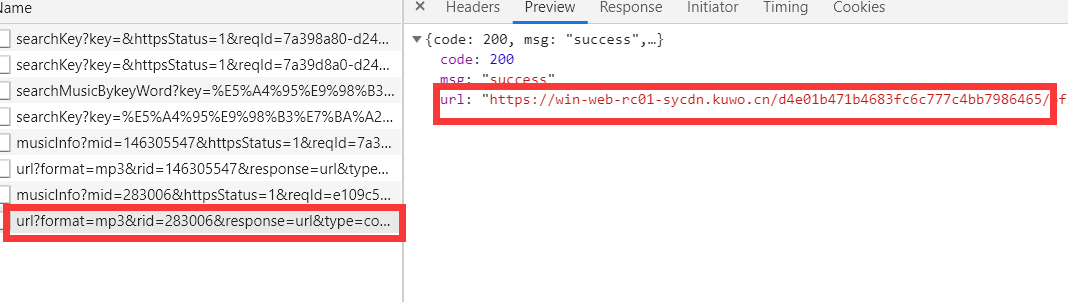
6、之后我们就要分析一下它的请求头
http://www.kuwo.cn/url?format=mp3&rid=283006&response=url&type=convert_url3&br=128kmp3&from=web&t=1596099527340&httpsStatus=1&reqId=e109c5d1-d242-11ea-84b1-4bd35f78cc6c
我giao,发现有好多参数,多播放几首歌曲,发现rid,t,reqId字段的值都不是固定的
本能以为就是在js文件里面生成的(可能爬取网易云爬多了。。。),我找呀找,,,找呀找,,还是没有找到(呜呜呜~~~~~)
于是我特别迷茫,,特特特特别别别迷茫~~~~~~~~
最后才发现,t和reqId字段虽然不是固定的,但是你可以把它当作固定的,,,,啊啊啊啊啊啊啊,服了,恶心人
于是就只需要找rid字段的值就行了

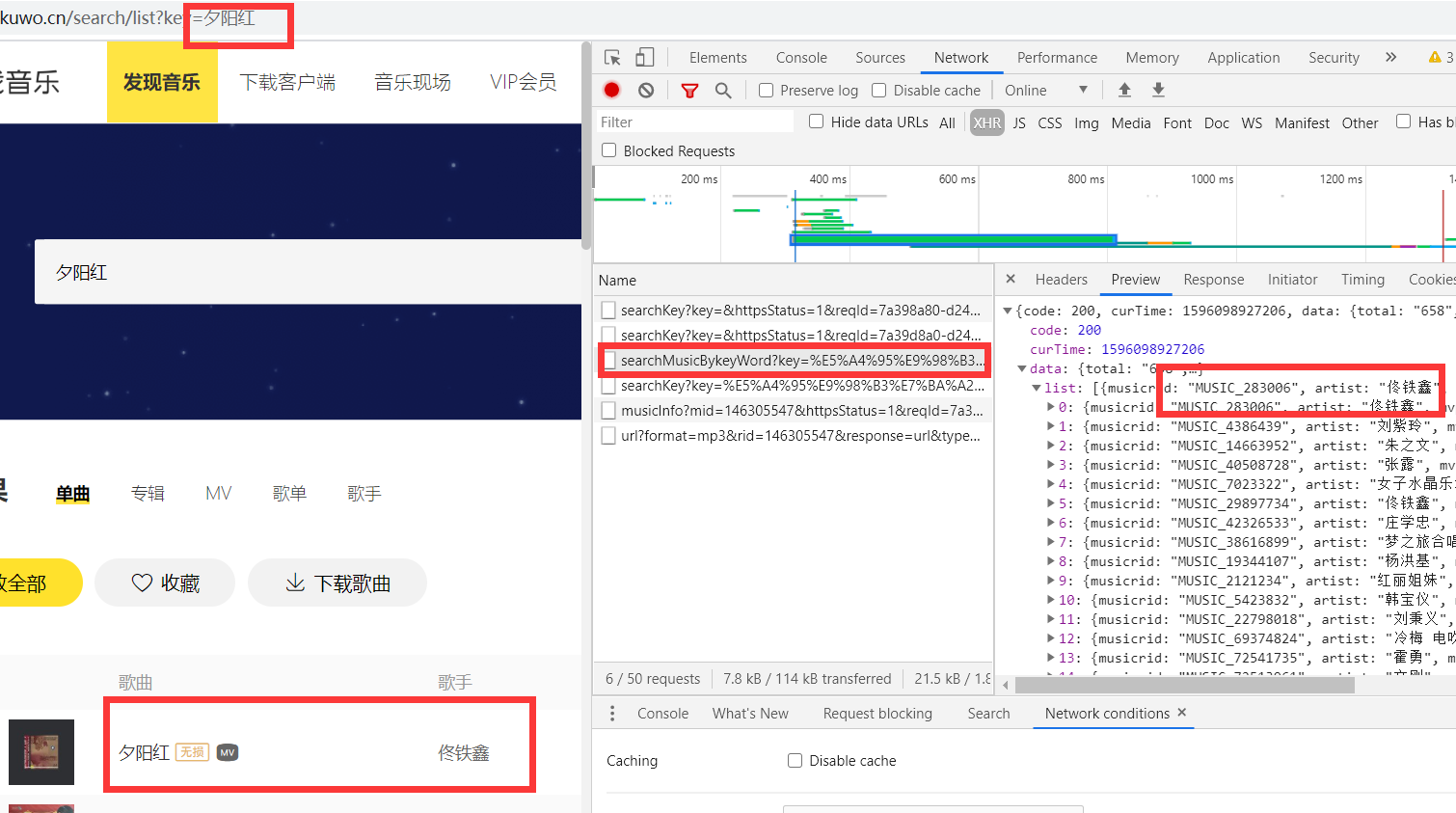
我在搜索框里面找它,给我显示没有(???从此世界上又少了一个单纯的人)rid都找到了,我们就分析一下这个数据包的请求头
http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key=%E5%A4%95%E9%98%B3%E7%BA%A2&pn=1&rn=30&httpsStatus=1&reqId=7a39ffb0-d241-11ea-84b1-4bd35f78cc6c
很明显key就是你要搜索的内容,pn就是页数,其他值还是当成固定值就行
我真的无语了,既然reqId可以当成固定值,那他还每次都变变变,不管哪个链接都有reqId,它还一直值都不一样,,我真想说zang话
代码(代码也没有整理,将就将就吧!)
import requests import json headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36' } headers1 = { 'Accept': 'application/json, text/plain, */*', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Connection': 'keep-alive', 'Cookie': '_ga=GA1.2.1500987479.1595755923; _gid=GA1.2.568444838.1596065504; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1595755923,1596065505; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1596076178; kw_token=P5XA2TZXG9', 'csrf': 'P5XA2TZXG9', 'Host': 'www.kuwo.cn', 'Referer': 'http://www.kuwo.cn/search/list?key=%E5%A4%95%E9%98%B3%E7%BA%A2', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36' } headers2 = { 'Accept': 'application/json, text/plain, */*', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Connection': 'keep-alive', 'Cookie': '_ga=GA1.2.1500987479.1595755923; _gid=GA1.2.568444838.1596065504; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1595755923,1596065505; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1596078189; _gat=1; kw_token=IJATWHHGI8', 'csrf': 'IJATWHHGI8', 'Host': 'www.kuwo.cn', 'Referer': 'http://www.kuwo.cn/search/list?key=%E6%A2%A6%E7%9A%84%E5%9C%B0%E6%96%B9', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36', } key_name = input('请输入你要查找的歌曲名称:') num = input('请输入你要查看歌曲列表第几页:') url2 = 'http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key={}&pn={}&rn=30&httpsStatus=1&reqId=da11ad51-d211-11ea-b197-8bff3b9f83d2e'.format(key_name,num) response = requests.get(url2,headers=headers2) #访问歌曲列表 print(response.text) response.encoding = response.apparent_encoding #这个apparent_encoding就是让系统根据页面来判断用何种编码 response = response.json() # 得到josn字典dict music_list = response["data"]["list"] #得到歌曲列表 print("共计" + str(len(music_list)) + "结果: ") all_singers = [] #放置所有歌手人名 names = [] #放置歌曲名字 all_rid = [] #放置所有rid,rid是网页所需参数 a = 0 for music in music_list: #print(music) singer = music["artist"] # 歌手名 name = str(a) + " " + music["name"] # 歌曲名 rid = music["musicrid"] #取出rid,之后要对这个字符串进行切割 index = rid.find('_') rid = rid[index + 1:len(rid)] all_singers.append(singer) #将对应信息放到列表中 names.append(name) all_rid.append(rid) a = a + 1 infs = dict(zip(names, all_singers)) infs = json.dumps(infs, ensure_ascii=False, indent=4, separators=(',', ':')) infs = infs.replace('"', ' ') infs = infs.replace(':', '——————') print(infs) order = input("请输入歌曲前的序号:") musicrid = all_rid[int(order)] url1 = 'http://www.kuwo.cn/url?format=mp3&rid={}&response=url&type=convert_url3&br=128kmp3&from=web&t=1596078536164&httpsStatus=1&reqId=01528151-d212-11ea-b197-8bff3b9f83d2'.format(musicrid) res = requests.get(url1,headers=headers1) #访问歌曲列表 res.encoding = res.apparent_encoding res = res.json() # dict res_url = res["url"] #取出歌曲下载url地址 music = requests.get(res_url,headers=headers).content with open(names[int(order)]+'.mp3','wb') as f: f.write(music)

