python爬取网易翻译 和MD5加密
一、程序需要知识
1、python中随机数的生成
# 生成 0 ~ 9 之间的随机数 # 导入 random(随机数) 模块 import random print(random.randint(0,9))
2、python获取当前时间和时间戳
import time,datetime #时间戳 print(time.time()) #今天的日期 print(datetime.date.today())
3、JavaScript parseInt(string,radix) 函数
| string | 必需。要被解析的字符串。 |
| radix |
可选。表示要解析的数字的基数。该值介于 2 ~ 36 之间。 如果省略该参数或其值为 0,则数字将以 10 为基础来解析。如果它以 “0x” 或 “0X” 开头,将以 16 为基数。 如果该参数小于 2 或者大于 36,则 parseInt() 将返回 NaN。 |
当参数 radix 的值为 0,或没有设置该参数时,parseInt() 会根据 string 来判断数字的基数。
举例,如果 string 以 "0x" 开头,parseInt() 会把 string 的其余部分解析为十六进制的整数。如果 string 以 0 开头,那么 ECMAScript v3 允许 parseInt() 的一个实现把其后的字符解析为八进制或十六进制的数字。如果 string 以 1 ~ 9 的数字开头,parseInt() 将把它解析为十进制的整数。
parseInt("10"); //返回 10 parseInt("19",10); //返回 19 (10+9) parseInt("11",2); //返回 3 (2+1) parseInt("17",8); //返回 15 (8+7) parseInt("1f",16); //返回 31 (16+15) parseInt("010"); //未定:返回 10 或 8 其实就是说string是radix进制,你把它转为十进制的数然后返回
4、python中的md5加密
def get_md5(t): #传入一个待加密的字符串t t = t.encode('utf-8') md5 = hashlib.md5(t).hexdigest() return md5 #md5就是加密后的字符串
二、js加密破解

你多翻译几次,得到多次请求和回应信息,比较一下就会发现红线处三个值一直在改变
其中 i 值比较明显就能看出来,这个就是你要翻译的字符,剩下三个想来也就只有搜索一下在哪个文件出现过

点击红线处,就会打开一个js文件
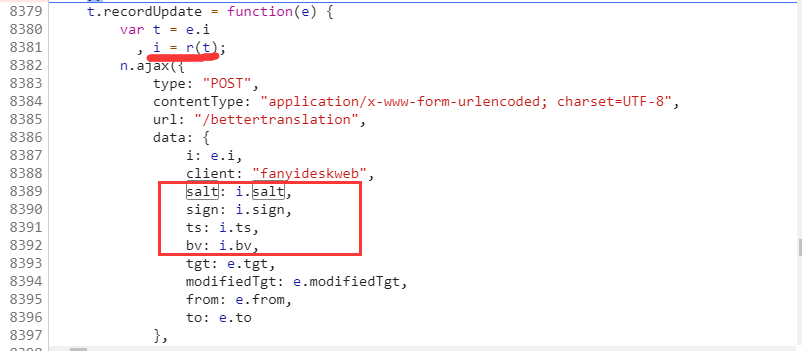
我们发现i这个对象是来自己r函数,逻辑就是r函数创建了一个对象,那就找一下r函数所在位置
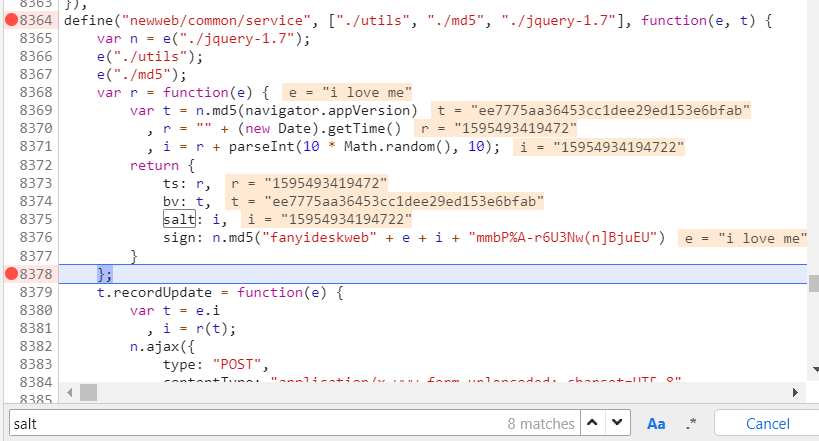
在文件中搜索这个词所在的位置,然后打断点看一下各变量的值
你发现t变量的值就是对一个字符串就行md5加密,如图

r变量的就是获取当前时间戳,然后乘于1000,因为不乘于1000得到的值的整数部分位数不够
i变量就是在r变量的基础上随机在后面加上一个[0,9]的数字
这个代码有些英文字母可以翻译,有些不可能。我也有点迷。在网上找了几个也是破js加密的代码发现也是和我一样的问题,,不太清楚哪里的错(如果某个大神找到了,带带我^_^)


import time import random import requests import json import hashlib headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Connection': 'keep-alive', 'Content-Length': '242', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Cookie': 'OUTFOX_SEARCH_USER_ID=-636625617@10.168.1.8; OUTFOX_SEARCH_USER_ID_NCOO=1075352995.079191; Hm_lvt_eaa57ca47dacb4ad4f5a257001a3457c=1568894226; JSESSIONID=aaaXQbfNVU1rgbPOx94nx; ___rl__test__cookies=1595473000749', 'Host': 'fanyi.youdao.com', 'Origin': 'http://fanyi.youdao.com', 'Referer': 'http://fanyi.youdao.com/', 'X-Requested-With': 'XMLHttpRequest', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36' } def get_md5(t): t = t.encode('utf-8') md5 = hashlib.md5(t).hexdigest() return md5 url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule' r = time.time()*1000 r = str(int(r)) i = r + str(random.randint(0,9)) e = input('请输入待翻译内容:') sign = get_md5("fanyideskweb" + e + i + "mmbP%A-r6U3Nw(n]BjuEU") bv = get_md5("5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36") data = { 'i': e, 'from': 'AUTO', 'to': 'AUTO', 'smartresult': 'dict', 'client': 'fanyideskweb', #'salt' : '15810537039389', #'sign' : '157b38258a2253c7899895880487edfd', #'ts' : '1581053703938', #'bv' : '901200199a98c590144a961dac532964', 'salt': i, 'sign': sign, 'ts': r, 'bv': bv, 'doctype': 'json', 'version': '2.1', 'keyfrom': 'fanyi.web', 'action': 'FY_BY_REALTlME' } #data = urllib.parse.urlencode(data).encode('utf-8') text = requests.post(url,headers=headers,data=data) dic = text.json() #print(dic) lis = dic['translateResult'] #print(lis) print(lis[0][0].get('tgt'))
我又在网上找到了另一种方式的代码,这个代码中文英文什么都能翻译,,,emmmm有点强
import urllib.request import urllib.parse import json import time while True: target = input("请输入需要翻译的内容:") url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' data = { 'i' : target, 'from' : 'AUTO', 'to' : 'AUTO', 'smartresult' : 'dict', 'client' : 'fanyideskweb', 'salt' : '15810537039389', 'sign' : '157b38258a2253c7899895880487edfd', 'ts' : '1581053703938', 'bv' : '901200199a98c590144a961dac532964', 'doctype' : 'json', 'version' : '2.1', 'keyfrom' : 'fanyi.web', 'action' : 'FY_BY_CLICKBUTTION' } head = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'} data = urllib.parse.urlencode(data).encode('utf-8') rep = urllib.request.Request(url, data, head) response = urllib.request.urlopen(rep) html = response.read().decode('utf-8') result = json.loads(html) result = result['translateResult'][0][0]['tgt'] print("翻译结果为:",result)

