
Spring系列19:SpEL详解
本文内容
-
SpEL概念
-
快速入门
-
关键接口
-
全面用法
-
bean定义中使用
SpEL概念
Spring 表达式语言(简称“SpEL”)是一种强大的表达式语言,支持在运行时查询和操作对象图。语言语法类似于 Unified EL,但提供了额外的功能,最值得注意的是方法调用和基本的字符串模板功能。
虽然 SpEL 是 Spring 产品组合中表达式评估的基础,但它不直接与 Spring 绑定,可以独立使用。
表达式语言支持以下功能:
- 字面表达式
- 布尔和关系运算符
- 正则表达式
- 类表达式
- 访问属性、数组、列表和映射
- 方法调用
- 关系运算符
- 调用构造函数
- bean引用
- 数组构造
- 内联的list
- 内联的map
- 三元运算符
- 变量
- 用户自定义函数
- 集合选择
- 模板化表达式
快速入门
通过几个案例快速体验SpEL表达式的使用。
案例1 Hello World
纯字面意义的字符串输出,体验使用的基本步骤。
@Test
public void test_hello() {
// 1 定义解析器
SpelExpressionParser parser = new SpelExpressionParser();
// 2 使用解析器解析表达式
Expression exp = parser.parseExpression("'Hello World'");
// 3 获取解析结果
String value = (String) exp.getValue();
System.out.println(value);
}
// 结果
Hello World
案例2 字符串方法的字面调用
在表达式中调用字符串的普通方法和构造方法。
@Test
public void test_String_method() {
// 1 定义解析器
SpelExpressionParser parser = new SpelExpressionParser();
// 2 使用解析器解析表达式
Expression exp = parser.parseExpression("'Hello World'.concat('!')");
// 3 获取解析结果
String value = (String) exp.getValue();
System.out.println(value);
exp = parser.parseExpression("'Hello World'.bytes");
byte[] bytes = (byte[]) exp.getValue();
exp = parser.parseExpression("'Hello World'.bytes.length");
int length = (Integer) exp.getValue();
System.out.println("length: " + length);
// 调用
exp = parser.parseExpression("new String('hello world').toUpperCase()");
System.out.println("大写: " + exp.getValue());
}
// 结果
Hello World!
length: 11
大写: HELLO WORLD
案例3 针对特定对象解析表达式
SpEL 更常见的用法是提供针对特定对象实例(称为根对象)进行评估的表达式字符串。案例演示如何从 Inventor 类的实例中检索名称属性或创建布尔条件。
Inventor相关类定义如下
public class Inventor {
private String name;
private String nationality;
private String[] inventions;
private Date birthdate;
private PlaceOfBirth placeOfBirth;
// 省略其它方法
}
public class PlaceOfBirth {
private String city;
private String country;
// 省略其它方法
}
表达式解析测试
@Test
public void test_over_root() {
// 创建 Inventor 对象
GregorianCalendar c = new GregorianCalendar();
c.set(1856, 7, 9);
Inventor tesla = new Inventor("Nikola Tesla", c.getTime(), "Serbian");
// 1 定义解析器
ExpressionParser parser = new SpelExpressionParser();
// 指定表达式
Expression exp = parser.parseExpression("name");
// 在 tesla对象上解析
String name = (String) exp.getValue(tesla);
System.out.println(name); // Nikola Tesla
exp = parser.parseExpression("name == 'Nikola Tesla'");
// 在 tesla对象上解析并指定返回结果
boolean result = exp.getValue(tesla, Boolean.class);
System.out.println(result); // true
}
执行过程分析和关键接口
执行过程分析
上面的案例中SpEL表达式的使用步骤中涉及了几个概念和接口:
- 用户表达式:我们定义的表达式,如
1+1!=2 - 解析器:ExpressionParser 接口,负责将用户表达式解析成SpEL认识的表达式对象
- 表达式对象:Expression接口,SpEL的核心,表达式语言都是围绕表达式进行的
- 评估上下文:EvaluationContext 接口,表示当前表达式对象操作的对象,表达式的评估计算是在上下文上进行的。
通过下面的简单案例debug分析执行过程。
@Test
public void test_debug(){
SpelExpressionParser parser = new SpelExpressionParser();
SimpleEvaluationContext context = SimpleEvaluationContext.forReadOnlyDataBinding().build();
Boolean value = parser.parseExpression("1+1!=2").getValue(context, Boolean.class);
System.out.println(value);
}
源码debug如下,分2大阶段,建议自行debug一次:
解析阶段:InternalSpelExpressionParser#doParseExpression() 无关源码已经删除
// 用户提供的表达式1+1!=2
private String expressionString = "";
// 分词流
private List<Token> tokenStream = Collections.emptyList();
@Override
protected SpelExpression doParseExpression(String expressionString, @Nullable ParserContext context)
throws ParseException {
try {
// 1 读取到用户的表达式 1+1!=2
this.expressionString = expressionString;
// 2.1 定义分词器Tokenizer
Tokenizer tokenizer = new Tokenizer(expressionString);
// 2.2 分词器将字符串拆分为分词流
this.tokenStream = tokenizer.process();
this.tokenStreamLength = this.tokenStream.size();
this.tokenStreamPointer = 0;
this.constructedNodes.clear();
// 3 将分词流解析成抽象语法树 表示为SpelNode接口
SpelNodeImpl ast = eatExpression();
Assert.state(ast != null, "No node");
// 4、将抽象语法树包装成 Expression 表达式对象
return new SpelExpression(expressionString, ast, this.configuration);
}
catch (InternalParseException ex) {
throw ex.getCause();
}
}
评估求值阶段:SpelExpression#getValue(),无关源码已经删除
// 解析阶段生成的抽象语法树对象 SpelNodeImpl
private final SpelNodeImpl ast;
public <T> T getValue(EvaluationContext context, @Nullable Class<T> expectedResultType) throws EvaluationException {
Assert.notNull(context, "EvaluationContext is required");
// ...
// 6.1 应用活动上下文和解析器的配置
ExpressionState expressionState = new ExpressionState(context, this.configuration);
// 6.2 在上下中抽象语法树进行评估求值
TypedValue typedResultValue = this.ast.getTypedValue(expressionState);
checkCompile(expressionState);
// 6.3 将结果进行类型转换
return ExpressionUtils.convertTypedValue(context, typedResultValue, expectedResultType);
}
方便理解,流程图如下图:
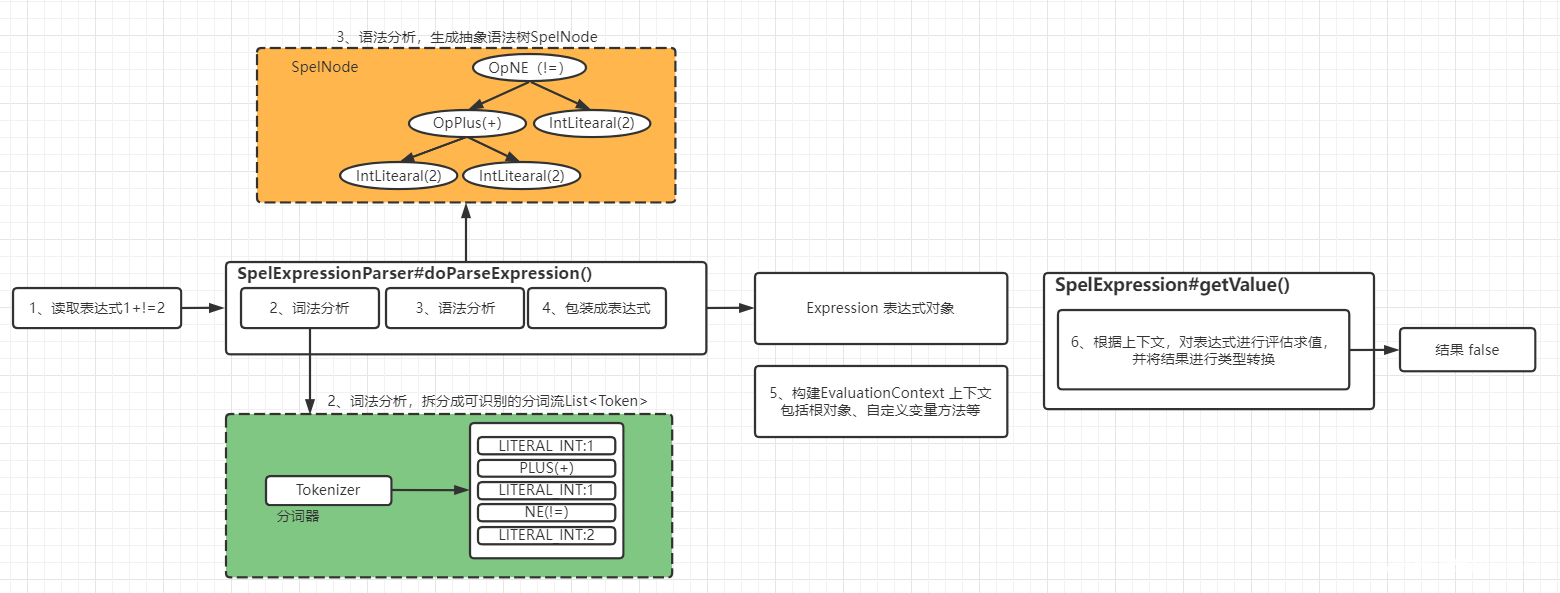
汇总下执行过程:
- 解析器 SpelExpressionParser 读取用户提供的表达式
1+1!=2 - 词法分析:解析器 SpelExpressionParser 使用分词器拆分用户字符串表达式成分词流
- 语法分析:解析器 SpelExpressionParser 将分词流生成内部的抽象语法树
- 包装表达式:对外提供Expression接口来简化表示抽象语法树,从而隐藏内部实现细节,并提供getValue简单方法用于获取表达式
- 用户提供表达式上下文对象(非必须),SpEL使用EvaluationContext接口表示上下文对象,用于设置根对象、自定义变量、自定义函数、类型转换器等
- 在表达式上下文中调用内部抽象语法树进行评估求值并转换结果类型到目标类型。
ExpressionParser 接口
ExpressionParser 接口将表达式字符串解析为可以计算的编译表达式。支持解析模板以及标准表达式字符串。
关键方法parseExpressio(),在解析失败时抛出 ParseException 异常。
public interface ExpressionParser {
// 解析表达式字符串并返回一个可用于重复评估的表达式对象。
Expression parseExpression(String expressionString) throws ParseException;
// 解析表达式字符串并返回一个可用于重复评估的表达式对象。 指定解析评估上下文
Expression parseExpression(String expressionString, ParserContext context) throws ParseException;
}
实现类 TemplateAwareExpressionParser 增加了对模板的解析支持。
常用的实现类 SpelExpressionParser 增加了 SpelParserConfiguration 解析器配置,实例是可重用和线程安全的。

Expression 接口
Expression 指能够根据上下文对象评估自身的表达式。封装先前解析的表达式字符串的详细信息。为表达式求值提供通用抽象。
关键方法如下:
getValue()在解析计算失败会抛出 EvaluationException 异常
public interface Expression {
// 获取原始表达式
String getExpressionString();
// 获取表达式计算值 默认上下文 默认类型
Object getValue() throws EvaluationException;
// 获取表达式计算值 指定上下文、根对象、期望返回值类型
<T> T getValue(EvaluationContext context, @Nullable Object rootObject, @Nullable Class<T> desiredResultType)
throws EvaluationException;
// 在提供的上下文中将此表达式设置为提供的值。
void setValue(@Nullable Object rootObject, @Nullable Object value) throws EvaluationException;
}
SpelExpression 接口表示已准备好在指定上下文中评估的已解析(有效)表达式。表达式可以独立评估,也可以在指定的上下文中评估。在表达式评估期间,可能会要求上下文解析对类型、bean、属性和方法的引用。
ParserContext 接口
ParserContext接口代表提供给表达式解析器的输入,可以影响表达式解析和编译。
源码如下:
public interface ParserContext {
// 是否是模板
boolean isTemplate();
// 模板表达式的前缀
String getExpressionPrefix();
// 模板表达式的后缀
String getExpressionSuffix();
// 启用模板表达式解析模式的默认 ParserContext 实现。表达式前缀是“#{”,表达式后缀是“}”。
ParserContext TEMPLATE_EXPRESSION = new ParserContext() {
@Override
public boolean isTemplate() {
return true;
}
@Override
public String getExpressionPrefix() {
return "#{";
}
@Override
public String getExpressionSuffix() {
return "}";
}
};
}
EvaluationContext 接口
EvaluationContext 接口评估表达式以解析属性、方法或字段并帮助执行类型转换。表达式是在在评估上下文中执行的,遇到引用时使用上下文来解析。
源码及关键方法如下:
public interface EvaluationContext {
// 返回默认的根上下文对象,可以在评估表达式时被覆
TypedValue getRootObject();
// 返回访问器列表用于属性的读写访问
List<PropertyAccessor> getPropertyAccessors();
// 返回解析器列表用于定位构造函数。
List<ConstructorResolver> getConstructorResolvers();
// 返回方法解析器以查找方法
List<MethodResolver> getMethodResolvers();
// 返回 bean解析器以通过名称查找bean
@Nullable
BeanResolver getBeanResolver();
// 返回类型定位器用于查找类型,支持简单类型名称和全程
TypeLocator getTypeLocator();
// 返回类型转换器用于类型转换
TypeConverter getTypeConverter();
// 返回一个类型比较器,用于比较对象对是否相等
TypeComparator getTypeComparator();
// 返回一个操作符重载器,该操作符重载器可能支持多个标准类型集之间的数学操作。
OperatorOverloader getOperatorOverloader();
// 将此评估上下文中的命名变量设置为指定值。
void setVariable(String name, @Nullable Object value);
// 在此求值上下文中查找指定变量。
@Nullable
Object lookupVariable(String name);
}
Spring 中提供了2个实现类:
-
StandardEvaluationContext
公开全套 SpEL 语言功能和配置选项。可以使用它来指定默认根对象并配置每个可用的评估相关策略。功能强大且高度可配置,此上下文使用所有适用策略的标准实现,基于反射来解析属性、方法和字段。
-
SimpleEvaluationContext
侧重于基本 SpEL 功能和自定义选项的子集,针对简单的条件评估和特定的数据绑定场景。
SimpleEvaluationContext 旨在仅支持 SpEL 语言语法的子集。它不包括 Java 类型引用、构造函数和 bean 引用。要求明确选择对表达式中的属性和方法的支持级别,默认情况下,create() 静态工厂方法只允许对属性进行读取访问。获取构建器以配置所需的确切支持级别,针对以下一项或某种组合:
- 仅自定义 PropertyAccessor(无反射)
- 只读访问的数据绑定属性
- 用于读取和写入的数据绑定属性
SpEl用法一网打尽
基本字面表达式
支持的文字表达式类型是字符串、数值(int、real、hex)、boolean 和 null。字符串由单引号分隔。要将单引号本身放在字符串中,使用两个单引号字符。数字支持使用负号、指数表示法和小数点。默认情况下,使用 Double.parseDouble() 解析实数。
@Test
public void test_literal() {
ExpressionParser parser = new SpelExpressionParser();
// 字符串 "Hello World"
String helloWorld = (String) parser.parseExpression("'Hello World'").getValue();
System.out.println(helloWorld);
double num = (Double) parser.parseExpression("6.0221415E+23").getValue();
System.out.println(num);
// int 2147483647
int maxValue = (Integer) parser.parseExpression("0x7FFFFFFF").getValue();
System.out.println(maxValue);
// 负数
System.out.println((Integer) parser.parseExpression("-100").getValue());
// boolean
boolean trueValue = (Boolean) parser.parseExpression("true").getValue();
System.out.println(trueValue);
// null
Object nullValue = parser.parseExpression("null").getValue();
System.out.println(nullValue);
}
// 结果
Hello World
6.0221415E23
2147483647
-100
true
null
属性、数组、列表、Map
属性: 指定属性名,通过"."支持多级嵌套。
数组:[index] 方式
列表:[index] 方式
Map:['key'] 方式
直接看案例。
通用的对象,后面案例通用
public class SpELTest2 {
// 解析器
SpelExpressionParser parser;
// 评估上下文
SimpleEvaluationContext context;
@Before
public void before() {
parser = new SpelExpressionParser();
context = SimpleEvaluationContext.forReadOnlyDataBinding().build();
}
}
/**
* 属性 数组 列表 map 索引
*/
@Test
public void test2(){
Inventor inventor = new Inventor("发明家1", "中国");
// 发明作品数组
inventor.setInventions(new String[] {"发明1","发明2","发明3","发明4"});
// 1 属性
String name = parser.parseExpression("name").getValue(context, inventor, String.class);
System.out.println("属性: " + name);
// 属性: 发明家1
// 2 数组表达式
String invention = parser.parseExpression("inventions[3]").getValue(context, inventor, String.class);
System.out.println("数组表达式: " + invention);
// 数组表达式: 发明4
// 3 List
List strList = Arrays.asList("str1", "str2", "str3");
String str = parser.parseExpression("[0]").getValue(context, strList, String.class);
System.out.println(str);
// str1
// 4 map
Map map = new HashMap<String, String>();
map.put("xxx", "ooo");
map.put("xoo", "oxx");
String value = parser.parseExpression("['xoo']").getValue(context, map, String.class);
System.out.println(value);
// oxx
}
内联List
使用 {} 表示法直接在表达式中表示列表
// 内联List
@Test
public void test3() {
List numbers = (List) parser.parseExpression("{1,3,5,7}").getValue(context);
System.out.println(numbers);
//[1, 3, 5, 7]
List listOfList = (List) parser.parseExpression("{{1,3,5,7},{0,2,4,6}}").getValue(context);
System.out.println(listOfList);
// [[1, 3, 5, 7], [0, 2, 4, 6]]
}
内联Map
使用 {key:value} 表示法直接在表达式中表示映射
/**
* 4 内联Map
*/
@Test
public void test4(){
Map<String, Object> infoMap =
(Map<String, Object>) parser.parseExpression("{'name':'name', password:'111'}").getValue();
System.out.println(infoMap);
//{name=name, password=111}
Map mapOfMap =
(Map) parser.parseExpression("{name:{first:'xxx', last:'ooo'}, password:'111'}").getValue(context);
System.out.println(mapOfMap);
// {name={first=xxx, last=ooo}, password=111}
}
集合选择
选择是一种强大的表达式语言功能,通过从其元素中进行选择将源集合转换为另一个集合。
Map 筛选的元素是 Map.Entry,可以使用 key 和 value 来筛选。
3种用法:
- 从集合按条件筛选生成新集合:
.?[selectionExpression] - 从集合按条件筛选后取第一个元素:
.?[selectionExpression] - 从集合按条件筛选后取最后一个元素:
.?[selectionExpression]
/**
* 集合选择
*/
@Test
public void test15(){
Society society = new Society();
// 发明者列表
for (int i = 0; i < 5; i++) {
Inventor inventor = new Inventor("发明家" + i, i % 2 == 0 ? "中国" : "外国");
society.getMembers().add(inventor);
}
// 1、 List 筛选 .?[selectionExpression]
List<Inventor> list = (List<Inventor>) parser.parseExpression("members.?[nationality == '中国']").getValue(society);
list.forEach(item -> {
System.out.println(item.getName() + " : " + item.getNationality());
});
// 发明家0 : 中国
// 发明家2 : 中国
// 发明家4 : 中国
// 2、 List 取第一个.^[selectionExpression] 取最后一个.$[selectionExpression]
Inventor first = parser.parseExpression("members.^[nationality == '中国']").getValue(society, Inventor.class);
Inventor last = parser.parseExpression("members.$[nationality == '中国']").getValue(society, Inventor.class);
System.out.println(first.getName() + " : " + first.getNationality());// 发明家0 : 中国
System.out.println(last.getName() + " : " + last.getNationality()); // 发明家4 : 中国
// 3 Map 筛选维度是 Map.Entry,其键和值可作为用于选择的属性访问
society.getOfficers().put("1", 100);
society.getOfficers().put("2", 200);
society.getOfficers().put("3", 300);
Map mapNew = (Map) parser.parseExpression("officers.?[value>100]").getValue(society);
System.out.println(mapNew); // {2=200, 3=300}
}
集合映射
一个集合通过映射的方式转换成新的集合,如从 Map 映射成 List,语法是: .![projectionExpression]
/**
* 集合映射
*/
@Test
public void test16(){
Society society = new Society();
// 发明者列表
for (int i = 0; i < 5; i++) {
Inventor inventor = new Inventor("发明家" + i, i % 2 == 0 ? "中国" : "外国");
society.getMembers().add(inventor);
}
// 1、 List<Inventor> 映射到 List<String> 只要name
List<String> nameList = (List<String>) parser.parseExpression("members.![name]").getValue(society);
System.out.println(nameList); // [发明家0, 发明家1, 发明家2, 发明家3, 发明家4]
// 2 Map映射到List
society.getOfficers().put("1", 100);
society.getOfficers().put("2", 200);
society.getOfficers().put("3", 300);
List<String> kvList= (List<String>) parser.parseExpression("officers.![key + '-' + value]").getValue(society);
System.out.println(kvList); // [1-100, 2-200, 3-300]
}
数组定义
直接使用 new 方式 ,注意: 多维数组不可以初始化。
/**
* 数组生成
*/
@Test
public void test5(){
int[] numbers1 = (int[]) parser.parseExpression("new int[4]").getValue(context);
// 一维数组可以初始化
int[] numbers2 = (int[]) parser.parseExpression("new int[]{1,2,3}").getValue(context);
// 多维数组不可以初始化
int[][] numbers3 = (int[][]) parser.parseExpression("new int[4][5]").getValue(context);
}
关系运算符
-
使用标准运算符表示法支持关系运算符(等于、不等于、小于、小于或等于、大于和大于或等于)和等价的英文字符缩写表示。
标准符号 等价英文缩写 <lt>gt<=le>=ge==eq!=ne/div%mod!not注意特殊的
null比任何比较都小,所以-1 < null为false,0 > null为false,如果数字比较使用0代替null更好。 -
支持 instanceof
小心原始类型,因为它们会立即装箱到包装器类型,因此
1 instanceof T(int)的计算结果为false,而1 instanceof T(Integer)的计算结果为true。 -
通过
matches支持正则表达式
/**
* 关系运算符
*/
@Test
public void test() {
// true
boolean trueValue = parser.parseExpression("2 == 2").getValue(Boolean.class);
// false
boolean falseValue = parser.parseExpression("2 < -5.0").getValue(Boolean.class);
// false
boolean falseValue2 = parser.parseExpression("2 gt -5.0").getValue(Boolean.class);
// true
boolean trueValue2 = parser.parseExpression("'black' < 'block'").getValue(Boolean.class);
// null 比任何比较数小
// true
Boolean value = parser.parseExpression("100 > null").getValue(boolean.class);
// false
Boolean value2 = parser.parseExpression("-1 < null").getValue(boolean.class);
System.out.println(value);
System.out.println(value2);
// instanceof 支持
// false
Boolean aBoolean = parser.parseExpression("'xxx' instanceof T(Integer)").getValue(Boolean.class);
System.out.println(aBoolean);
// 支持正则表达式 matches
// true
Boolean match = parser.parseExpression(
"'5.00' matches '^-?\\d+(\\.\\d{2})?$'").getValue(Boolean.class);
// false
Boolean notMatch = parser.parseExpression(
"'5.0067' matches '^-?\\d+(\\.\\d{2})?$'").getValue(Boolean.class);
System.out.println(match);
System.out.println(notMatch);
}
逻辑运算符
支持标准符号和英文字符缩写:
and(&&)or(||)not(!)
/**
* 逻辑运算符
*/
@Test
public void test8() {
Society societyContext = new Society();
// -- AND --
// false
boolean falseValue = parser.parseExpression("true and false").getValue(Boolean.class);
// true
String expression = "isMember('Nikola Tesla') and isMember('Mihajlo Pupin')";
boolean trueValue = parser.parseExpression(expression).getValue(societyContext, Boolean.class);
// -- OR --
// true
boolean trueValue2 = parser.parseExpression("true or false").getValue(Boolean.class);
// true
expression = "isMember('Nikola Tesla') or isMember('Albert Einstein')";
boolean trueValue3 = parser.parseExpression(expression).getValue(societyContext, Boolean.class);
// -- NOT --
// false
boolean falseValue2 = parser.parseExpression("!true").getValue(Boolean.class);
// -- AND and NOT --
expression = "isMember('Nikola Tesla') and !isMember('Mihajlo Pupin')";
boolean falseValue3 = parser.parseExpression(expression).getValue(societyContext, Boolean.class);
}
数学运算符
可以对数字和字符串使用加法运算符,字符串只支持"+"。
/**
* 数学运算符
*/
@Test
public void test9(){
// Addition
int two = parser.parseExpression("1 + 1").getValue(Integer.class); // 2
String testString = parser.parseExpression(
"'test' + ' ' + 'string'").getValue(String.class); // 'test string'
// Subtraction
int four = parser.parseExpression("1 - -3").getValue(Integer.class); // 4
double d = parser.parseExpression("1000.00 - 1e4").getValue(Double.class); // -9000
// Multiplication
int six = parser.parseExpression("-2 * -3").getValue(Integer.class); // 6
double twentyFour = parser.parseExpression("2.0 * 3e0 * 4").getValue(Double.class); // 24.0
// Division
int minusTwo = parser.parseExpression("6 / -3").getValue(Integer.class); // -2
double one = parser.parseExpression("8.0 / 4e0 / 2").getValue(Double.class); // 1.0
// Modulus
int three = parser.parseExpression("7 % 4").getValue(Integer.class); // 3
int value = parser.parseExpression("8 / 5 % 2").getValue(Integer.class); // 1
int minusTwentyOne = parser.parseExpression("1+2-3*8").getValue(Integer.class); // -21
}
赋值操作符
赋值运算符 =用于设置属性。通常在对 setValue 的调用中完成,但也可以在对 getValue 的调用中完成
/**
* 赋值操作
*/
@Test
public void test(){
Inventor inventor = new Inventor();
EvaluationContext context = SimpleEvaluationContext.forReadWriteDataBinding().build();
// setValue 中
parser.parseExpression("Name").setValue(context, inventor, "xxx");
// 等价于在 getValue 赋值
String name = parser.parseExpression(
"Name = 'xxx'").getValue(context, inventor, String.class);
System.out.println(name); // xxx
}
三目运算与 Elvis 操作符
三元运算符表示执行 if-then-else 条件逻辑。
parser.parseExpression("name != null ? name : 'null name'").
使用三目运算符语法,通常必须重复一个变量两次如上面的name。Elvis 运算符是三元运算符语法的缩写,借鉴了Groovy 语言的语法。
parser.parseExpression("name?:'null name'")
为什么
?:叫Elvis操作符 ? 之前挺纳闷的,后来发现是与美国摇滚歌星Elvis(猫王)的发型相似而得名。
案例如下:
/**
* 三目运算和简化
*/
@Test
public void test17(){
Inventor inventor = new Inventor("not null name", "");
String name = (String) parser.parseExpression("name != null ? name : 'null name'").getValue(inventor);
System.out.println("三目:" + name);
// 使用 Elvis运算符
name = (String) parser.parseExpression("name?:'null name'").getValue(inventor);
System.out.println("Elvis运算符:" + name);
}
嵌套属性安全访问?.
多级属性访问如国家城市城镇nation.city.town三级访问,如果中间的 city是null则会抛出 NullPointerException 异常。为了避免这种情况的异常,SpEL借鉴了Groovy的语法?.,如果中间属性为null不会抛出异常而是返回null。
/**
* 多级属性安全访问
*/
@Test
public void test18(){
Inventor inventor = new Inventor("xx", "oo");
inventor.setPlaceOfBirth(new PlaceOfBirth("北京", "中国"));
// 正常访问
String city = parser.parseExpression("PlaceOfBirth?.city").getValue(context, inventor, String.class);
System.out.println(city); // 北京
// placeOfBirth为null
inventor.setPlaceOfBirth(null);
String city1 = parser.parseExpression("PlaceOfBirth?.city").getValue(context, inventor, String.class);
System.out.println(city1); // null
// 非安全访问 异常
String city3 = parser.parseExpression("PlaceOfBirth.city").getValue(context, inventor, String.class);
System.out.println(city3); // 抛出异常
}
方法调用
使用典型的 Java 编程语法来调用方法。可以在字面上调用方法。还支持可变参数。
/**
* 方法调用
*/
@Test
public void test6(){
String bc = parser.parseExpression("'abc'.substring(1, 3)").getValue(String.class);
System.out.println(bc);
// bc
Society societyContext = new Society();
// 传递参数
boolean isMember = parser.parseExpression("isMember('Mihajlo Pupin')").getValue(
societyContext, Boolean.class);
System.out.println(isMember);
// false
}
构造方法new
使用 new 运算符调用构造函数。对除原始类型(int、float 等)和 String 之外的所有类型使用完全限定的类名。
/**
* new 调用构造方法
*/
@Test
public void test12(){
Inventor value =
parser.parseExpression("new com.crab.spring.ioc.demo20.Inventor('ooo','xxx')").getValue(Inventor.class);
System.out.println(value.getName() + " " + value.getNationality()); // ooo xxx
String value1 = parser.parseExpression("new String('xxxxoo')").getValue(String.class);
System.out.println(value1); // xxxxoo
}
类类型T
使用特殊的 T 运算符指定 java.lang.Class 的实例(类型)。
类中的静态变量、静态方法属于Class, 可以通过T(xxx).xxx调用。
@Test
public void test11(){
// 1 获取类的Class java.lang包下的类可以不指定全路径
Class value = parser.parseExpression("T(String)").getValue(Class.class);
System.out.println(value);
// 2 获取类的Class 非java.lang包下的类必须指定全路径
Class dateValue = parser.parseExpression("T(java.util.Date)").getValue(Class.class);
System.out.println(dateValue);
// 3 类中的静态变量 静态方法属于Class 通过T(xxx)调用
boolean trueValue = parser.parseExpression(
"T(java.math.RoundingMode).CEILING < T(java.math.RoundingMode).FLOOR")
.getValue(Boolean.class); // true
System.out.println(trueValue);
Long longValue = parser.parseExpression("T(Long).parseLong('9999')").getValue(Long.class);
System.out.println(longValue);// 9999
}
表达式模板 #{}
表达式模板允许将文字文本与一个或多个评估块混合。每个评估块都由前缀和后缀字符分隔,默认是#{ }。支持实现接口ParserContext自定义前后缀。
调用parseExpression()时指定 ParserContext参数如new TemplateParserContext()
/**
* 表达式模板 #{}
*/
@Test
public void test19() {
String randomStr = parser.parseExpression("随机数字是: #{T(java.lang.Math).random()}", new TemplateParserContext())
.getValue(String.class);
System.out.println(randomStr);
}
定义和使用变量
可以使用#variableName 语法来引用表达式中的变量。通过在 EvaluationContext 实现上使用 setVariable 方法设置变量。
/**
* 变量 #
*/
@Test
public void test13() {
Inventor inventor = new Inventor("xxx", "xxx");
SimpleEvaluationContext context = SimpleEvaluationContext.forReadWriteDataBinding().build();
context.setVariable("newName", "new ooo");
// 使用预先的变量赋值 Name 属性
parser.parseExpression("Name = #newName").getValue(context, inventor);
System.out.println(inventor.getName()); // new ooo
}
#this 和 #root 变量
#this 变量始终被定义并引用当前评估对象(针对那些非限定引用被解析)。
#root 变量始终被定义并引用根上下文对象。
注册和使用自定义方法
函数可以当做一种变量来注册和使用的。2种方式注册:
- 按变量设置方式
EvaluationContext#setVariable(String name, @Nullable Object value) - 按明确的方法设置方式
StandardEvaluationContext#public void registerFunction(String name, Method method),其实底下也是按照变量处理。
/**
* 方法注册和使用
*/
@Test
public void test20() throws NoSuchMethodException {
// 注册 org.springframework.util.StringUtils.startsWithIgnoreCase(String str,String prefix)
Method method = StringUtils.class.getDeclaredMethod("startsWithIgnoreCase",String.class,String.class);
// 方式1 变量方式
SimpleEvaluationContext simpleEvaluationContext = SimpleEvaluationContext.forReadOnlyDataBinding().build();
simpleEvaluationContext.setVariable("startsWithIgnoreCase" ,method);
Boolean startWith = parser.parseExpression("#startsWithIgnoreCase('123', '111')").getValue(simpleEvaluationContext,
Boolean.class);
System.out.println("方式1: " + startWith);
// 方式2 明确方法方式
StandardEvaluationContext standardEvaluationContext = new StandardEvaluationContext();
standardEvaluationContext.registerFunction("startsWithIgnoreCase" ,method);
Boolean startWit2 =
parser.parseExpression("#startsWithIgnoreCase('123', '111')").getValue(simpleEvaluationContext,
Boolean.class);
System.out.println("方式2: " + startWit2);
}
bean引用
如果评估上下文已经配置了 bean 解析器,可以使用 @ 符号从表达式中查找 bean。直接看案例。
@Configuration
@ComponentScan
public class BeanReferencesTest {
// 注入一个bean
@Component("myService")
static class MyService{
}
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext =
new AnnotationConfigApplicationContext(BeanReferencesTest.class);
SpelExpressionParser parser = new SpelExpressionParser();
// 使用 StandardEvaluationContext
StandardEvaluationContext standardEvaluationContext = new StandardEvaluationContext();
// 需要注入一个BeanResolver来解析bean引用,此处注入 BeanFactoryResolver
standardEvaluationContext.setBeanResolver(new BeanFactoryResolver(applicationContext));
// 使用 @ 来引用bean
MyService myService = parser.parseExpression("@myService").getValue(standardEvaluationContext, MyService.class);
System.out.println(myService);
}
}
思考下 FactoryBean 如何引用?
Spring bean定义中使用
基于 XML 或基于注释的配置元数据的 SpEL 表达式来定义 BeanDefinition 实例的语法都是 #{ <expression string> }。
应用程序上下文中的所有 bean 都可以作为具有公共 bean 名称的预定义变量使用。常用的包括但限于:
- 标准上下文环境
environment,类型为org.springframework.core.env.Environment - JVM系统属性
systemProperties,类型为Map<String, Object> - 系统环境变量
systemEnvironment,类型为Map<String, Object>
注意: 作为预定义变量的不需要使用 #前缀。
xml 方式
可以使用表达式设置属性或构造函数参数值,直接上案例。
配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean class="com.crab.spring.ioc.demo20.MyBean" id="myBean">
<!--SpeL调用类静态方法-->
<property name="randomNumber" value="#{ T(java.lang.Math).random() * 100.0 }"/>
<!--SpeL读取系统属性中的用户名-->
<property name="name" value="#{ systemProperties['user.name']}"/>
</bean>
<!-- 引用别的bean的属性-->
<bean class="com.crab.spring.ioc.demo20.MyBean" id="myBean2">
<!--@引用bean实例 其实所有注入容器的bean都是预定义变量,不需要@也行-->
<property name="name" value="#{@myBean.randomNumber}"/>
<property name="randomNumber" value="#{myBean.randomNumber}"/>
</bean>
</beans>
测试程序和结果
/**
* xml方式在bean定义中使用SpEL
*/
@Test
public void test() {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("demo20/spring.xml");
Map<String, MyBean> beansOfType = context.getBeansOfType(MyBean.class);
beansOfType.entrySet().forEach(entry -> System.out.println(entry.getKey() + " : " + entry.getValue()));
context.close();
// myBean : MyBean{randomNumber=72.45707551702549, name='dell'}
// myBean2 : MyBean{randomNumber='dell', name='72.45707551702549'}
}
注解方式
要指定默认值,可以将 @Value 注释放在字段、方法以及方法或构造函数参数上。直接看案例。
@Component
@ComponentScan
public class MyComponent {
private String language;
@Value("#{ systemProperties['user.language']}")
private String locale;
private String name;
@Value("#{ systemProperties['user.name']}")
public void setName(String name) {
this.name = name;
}
@Autowired
public MyComponent(@Value("#{ systemProperties['user.language']}") String language) {
this.language = language;
}
// ...
}
测试,观察输出结果。
@Test
public void test(){
AnnotationConfigApplicationContext context =
new AnnotationConfigApplicationContext(MyComponent.class);
MyComponent bean = context.getBean(MyComponent.class);
System.out.println(bean);
// MyComponent{language='zh', locale='zh', name='dell'}
}
总结
本文从原理到实战案例详解介绍了SpEL表达式。纸上得来终觉浅,绝知此事要躬行,案例比较多,好好消化。本文也可以作为SpEL使用手册来使用。
知识分享,转载请注明出处。学无先后,达者为先!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号