单、双缓冲区学习笔记
缓冲区数据传输时间计算
单缓冲区
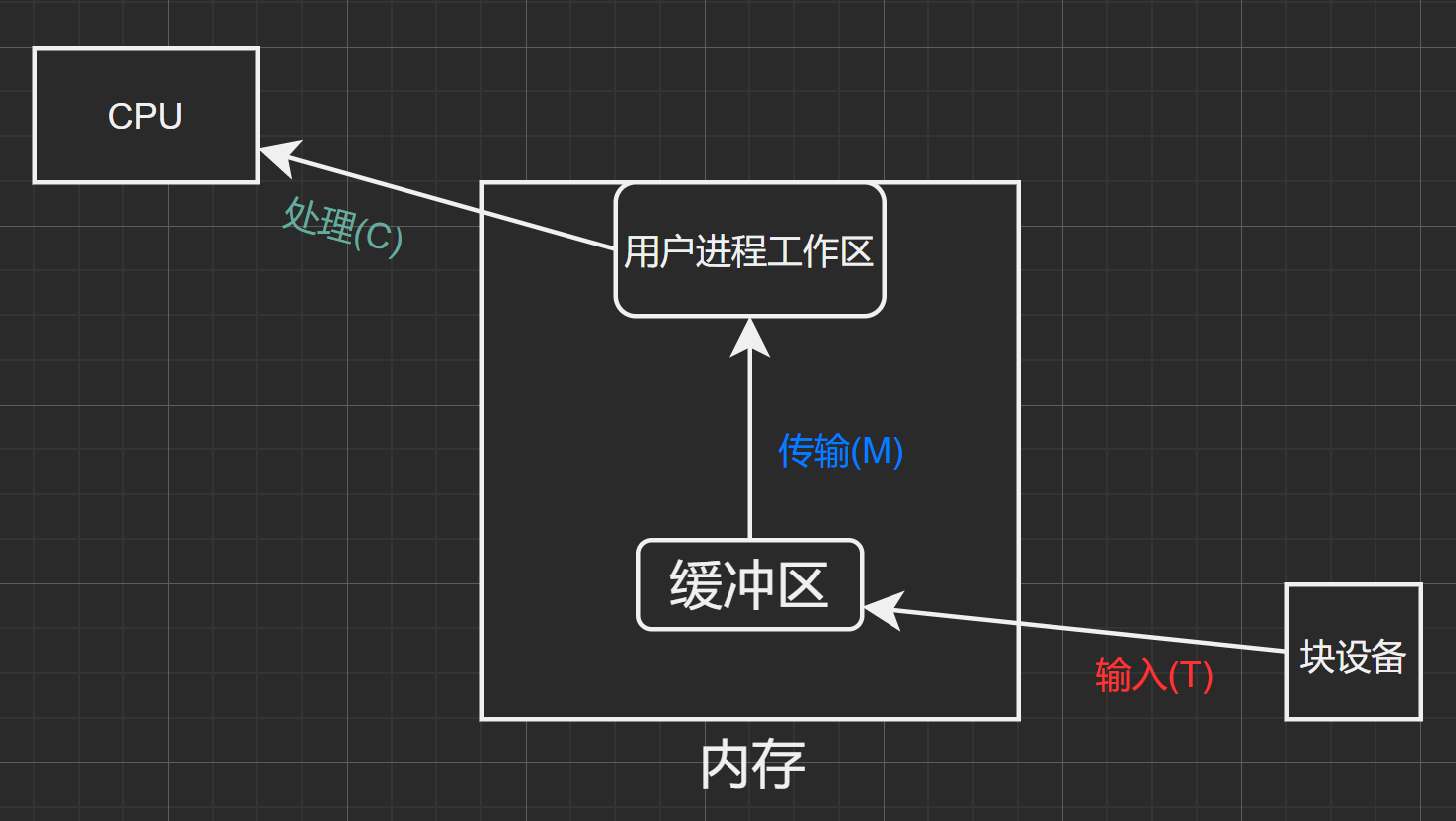 图1.1
图1.1
其中数据流之间的关系为: 图1.2
图1.2
-
这与缓冲区的特性有关,只有当缓冲区内为空时才能往里面传入数据;只有缓冲区为满时才能从中取出数据。
也意味着,对于缓冲区来说,同一时刻只能存在输入(T)与传输(M)中的一个操作。但是输入(T)与处理(C)操作可以同时存在。
处理时间(C) > 输入时间(T)的情况:
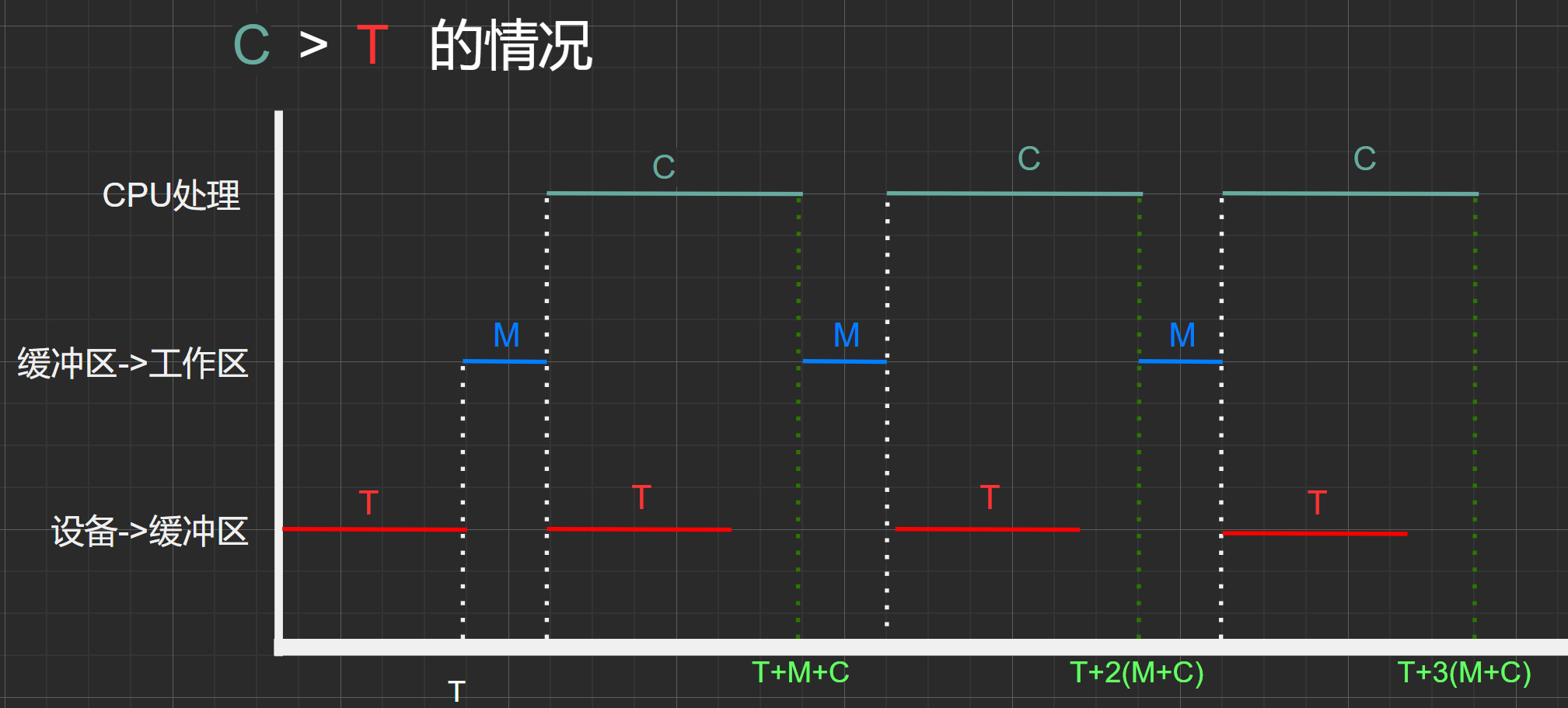 图1.3
图1.3
假设初始0时刻状态:缓冲区、工作区均为空。
这里稍微解释一下这甘特图的含义。从一开始经过T时间之后,缓冲区被充满了第一块数据。之后经过M时间后,该数据块从缓冲区传输到工作区。再经过C时间,该数据块在用户空间内被CPU处理,而从上面的 [数据流之间的关系] 图可以得知,在CPU处理该数据块时,可以并行的从设备中接着输入下一块数据块到缓冲区中(在CPU刚开始处理数据块时缓冲区为空),而由于C>T所以在CPU处理完上一块数据时,缓冲区已经被充满下一块数据。从上面的 [数据流之间的关系] 图可以得知C操作与M操作只能串行,即在工作区未完全为空时不能提前将缓冲区中的数据传输到工作区,所以下一个M需要等待C执行完毕之后才能进行。后面的过程与此类似。
这里可以一个周期为单位来分析数据块的处理情况(一块数据块从设备->缓冲区->工作区->cup处理),一个周期:下一次达到当前状态时所需经过的最少时间。
如:
- \(T\)时间点:缓冲区为满,工作区为空
- \(T+M+C\)时间点:缓冲区为满,工作区为空,状态与时刻\(T\)相同
- 可得,时间:\((T+M+C)-T=M+C\) 为一个周期,其中处理了一个数据块(C)
- 因此,在处理时间(C) > 输入时间(T)的情况下,平均处理一个数据块所需时间为\(M+C\)
按照上面的推理,我们可知道,当时间点为:\(T+2(M+C)\)时,以及处理了两个数据块。
碎碎念:虽然仅仅从一块数据块的从设备->缓冲区->工作区->cup处理的时间为\(0\)~\((T+M+C)\) 很容易让人以为两块数据块的处理时间为\(2*(T+M+C)\),我做题就这么算错了 ,实际上为\(T+2(M+C)\) ,为什么不能这么算呢?因为对于连续处理数据快来说,相邻的两个周期内有一段时间是重合的。
处理时间(C) < 输入时间(T)的情况:
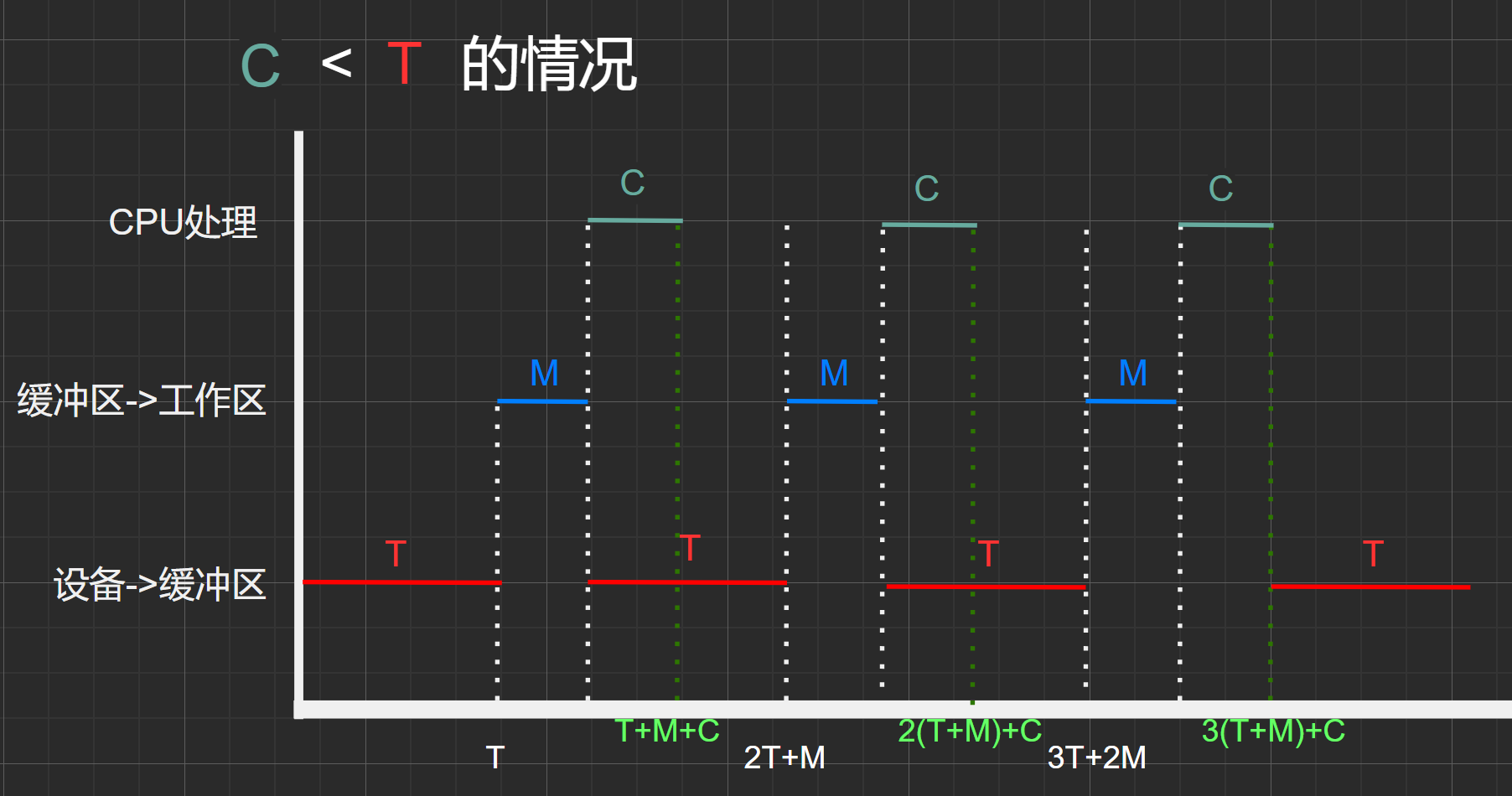 图1.4
图1.4
同上面情况类型。
从一开始经过T时间之后,缓冲区被充满了第一块数据。之后经过M时间后,该数据块从缓冲区传输到工作区。再经过C时间,该数据块在用户空间内被CPU处理,而从上面的 [数据流之间的关系] 图可以得知,在CPU处理该数据块时,可以并行的从设备中接着输入下一块数据块到缓冲区中(在CPU刚开始处理数据块时缓冲区为空),而由于C<T所以在CPU处理完上一块数据时,缓冲区还未传输完下一块数据。
假设初始0时刻状态:缓冲区、工作区均为空。
- \(T\)时间点:缓冲区为满,工作区为空
- \(2T+M\)时间点:缓冲区为满,工作区为空,状态与时刻\(T\)相同
- 可得,时间:\((2T+M)-T=T+C\) 为一个周期,其中处理了一个数据块(C)
- 因此,在处理时间(C) < 输入时间(T)的情况下,平均处理一个数据块所需时间为\(T+C\)
碎碎念:类似于上情况的碎碎念,不过需要注意的是,这里所要求处理第二个数据块的时间所以不应该包括第三个\(T\),因为那个\(T\)是属于第三个数据块周期的。所以该情况下处理两个块的耗时为:\(2*(T+M)+C\)
找关系,单缓冲区平均处理一个数据块耗时
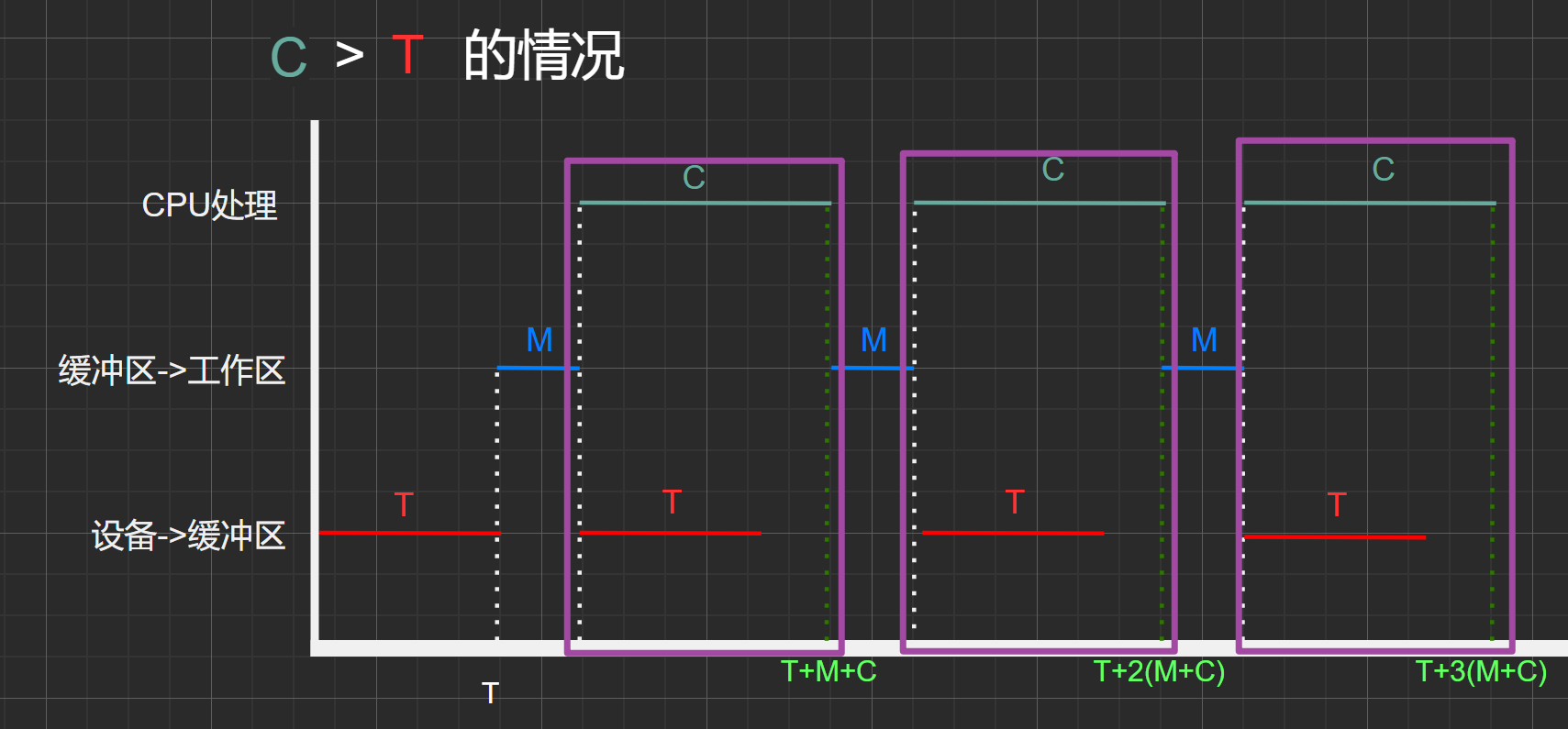 图1.5
图1.5
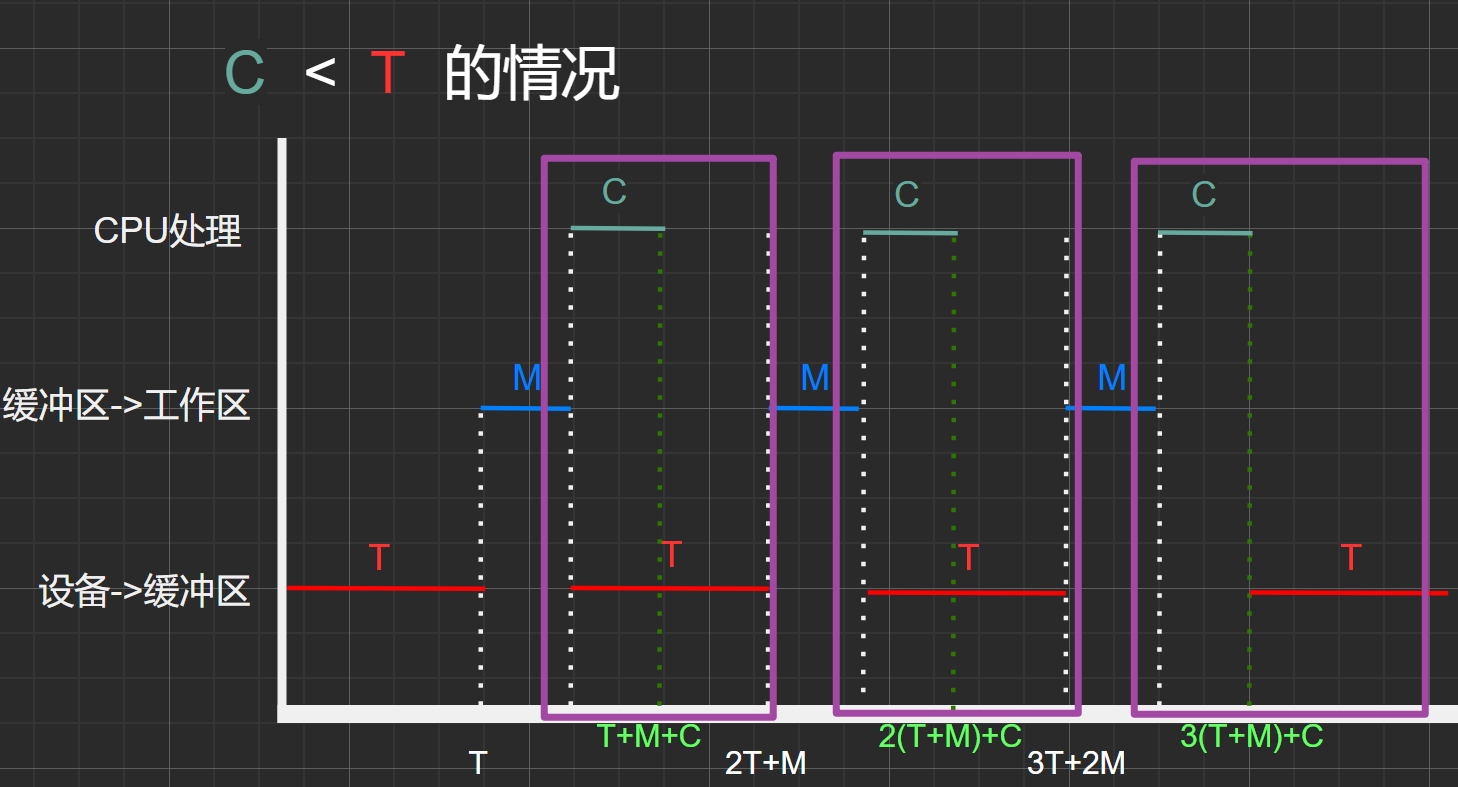 图1.6
图1.6
仔细观察上图,不难发现这个现象:每个周期内,区间总时间内有一部分是重叠,且时间取最大值:\(MAX(C,T)\)
这里并不难理解,因为这两个操作是并行的,也就是说可以同时进行。但是作为周期循环的中间媒介 缓冲区的相关操作M与这两个操作又是串行的,因此需要单独算上该时间。
**因此,不论是 C>T 还是 C<T ,缓冲区平均处理一个数据块的时间为:\(MAX(C,T)+M\) **
看到这结论时,估计大家会想起我在上面碎碎念时谈到关于处理两个数据块的耗时问题,会很自然的想处理两个数据块的耗时是不是可以直接\(2*[MAX(C,T)+M]\)呢?但是实际上两种情况中处理两个数据块无论是哪一个情况都不符合这结果。
因为我们所求时间为:\(设备->缓冲区->工作区->CPU处理\)
与我们求公式时选定的周期时间:\(缓冲区->工作区->MAX(CPU处理,设备->缓冲区)\)
不一致。
接下来让我们找一找内在联系
图1.7
可以看出,\([0,T+3(M+C)]\) 内处理了三个数据块。
所需时间 =\(T+M+MAX(C,T)+M+MAX(C,T)+M+C\)
=\(T+M+C+2[M+MAX(C,T)]\)
=\(T+M+MAX(C,T)+2[M+MAX(C,T)]\)
=\(3[M+MAX(C,T)]+T\)
=>\(N*缓冲区平均处理一块数据块时间+T\),其中N为处理的数据块数
=\(3*(M+C)+T\)
用该公式求解碎碎念:
将公式中的3改成2即可得到答案。
图1.8
可以看出,\([0,C+3(M+C)]\) 内处理了三个数据块。
所需时间:\(T+M+MAX(C,T)+M+MAX(C,T)+M+C\)
=\(T+M+C+2[M+MAX(C,T)]\)
=\(MAX(C,T)+M+C+2[M+MAX(C,T)]\)
=\(3[M+MAX(C,T)]+C\)
=>\(N*缓冲区平均处理一块数据块时间+C\),其中N为处理的数据块数
=\(3*(M+T)+C\)
用该公式求解碎碎念:
将公式中的3改成2即可得到答案。
再总结:
求N块数据块从设备->缓冲区->工作区->cup处理所需的时间。
\(N*[M+MAX(C,T)]+min(C,T)\)
\(=处理数据块的数量*[缓冲区->工作区+MAX(CPU处理,设备->缓冲区)]+min(CPU处理,设备->缓冲区)\)
例题:
设系统缓冲区和用户工作区均采用单缓冲,从外设读入一个数据块到系统缓冲区的时间为\(100\),从系统缓冲区读入一个数据块到用户工作区的时间为\(5\),对用户工作区中的一个数据块进行分析的时间为\(90\)(如下图)。进程从外设读入并分析\(2\)个数据块的最短时间为多少?
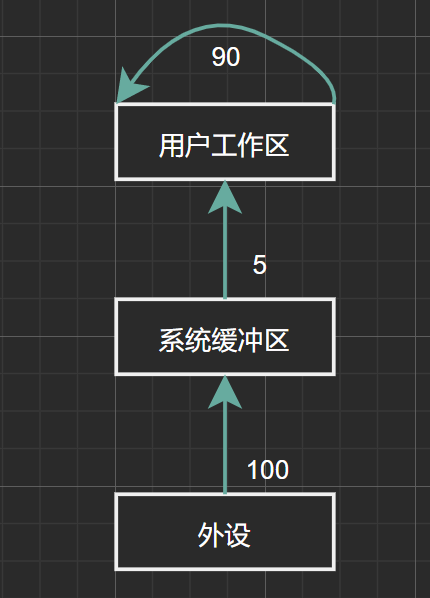 图1.11
图1.11
时间甘特图:
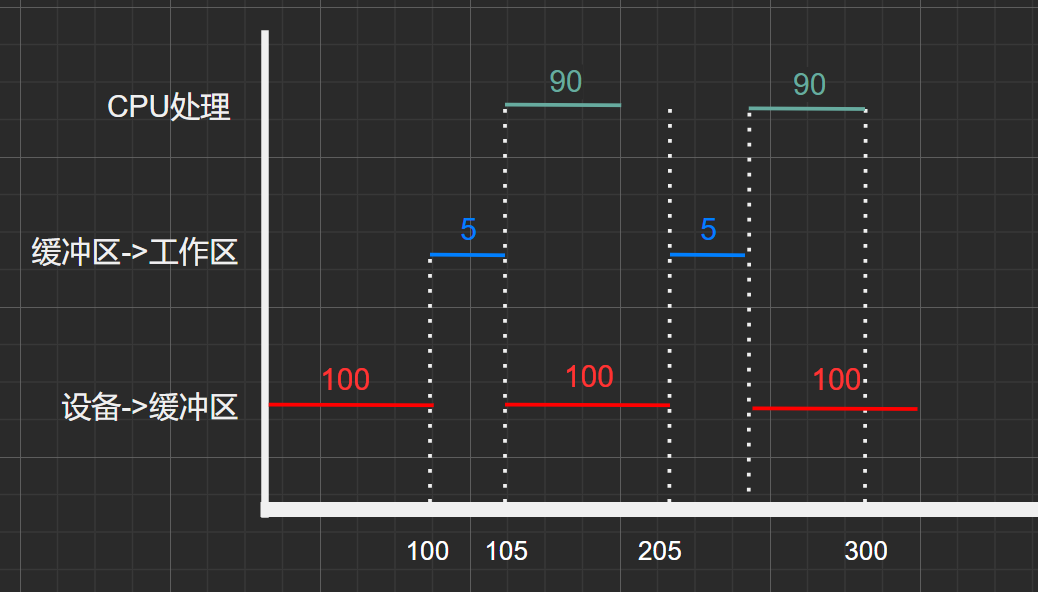 图1.12
图1.12
单缓冲区,套用公式:\(N*[M+MAX(C,T)]+min(C,T)\)
得: \(2*(5+100)+90=300\)
双缓冲区:
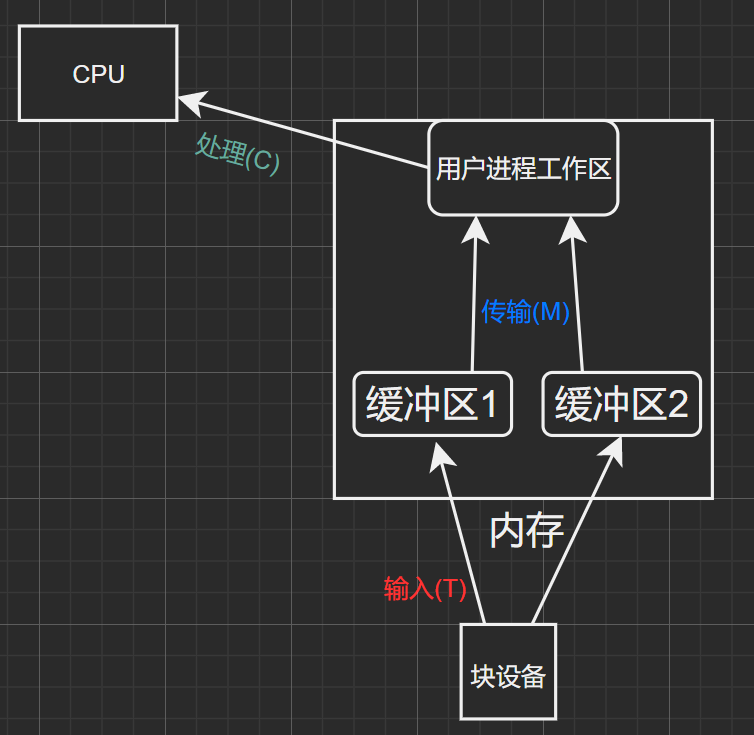 图2.1
图2.1
其中数据流之间的关系为: 图2.2
图2.2
注意这里的T2、T1的速度相同,M1、M2的速度相同
处理时间(C)+传送时间(M) < 处理时间(C)的情况:
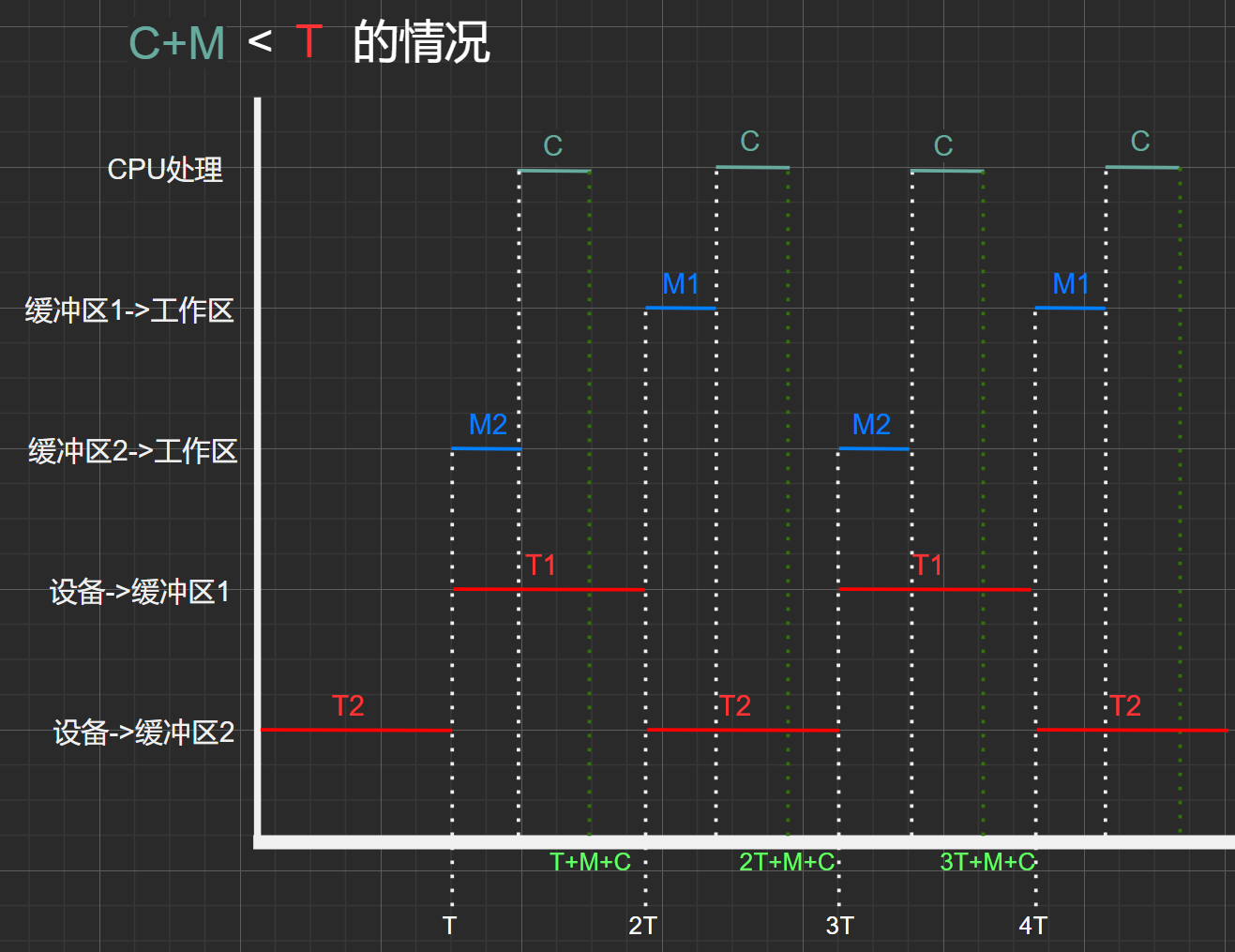 图2.3
图2.3
初始状态:0时刻中工作区,缓冲区1、缓冲区2均为空
这里的分析情况与单缓冲类似。
- \(T时间点:\) 工作区为空、缓冲区2为满、缓冲区1为空
- \(2T时间点:\) 工作区为空、缓冲区2为空、缓冲区1为满
- \(3T时间点:\)工作区为空、缓冲区2为满、缓冲区1为空,达到了\(T时间点\)的相同状态,因此
- 可得,时间\(3T-T=2T\)为一个周期,其中处理了两个数据块(C)
- 因此,在处理时间(C)+传送时间(M) < 处理时间(C)的情况下,平均处理一个数据块所需时间为:\(2T/2=T\)
其实,这两个缓冲区的处理速度一样,可以将其等效,即将\(T、2T、3T\)时间点看成相同的状态:工作区为空,一个缓冲区为满、一个缓冲区为空。
也就是说,\(2T\) ~ \(T\)可看作一个周期
处理时间(C)+传送时间(M) > 处理时间(C)的情况:
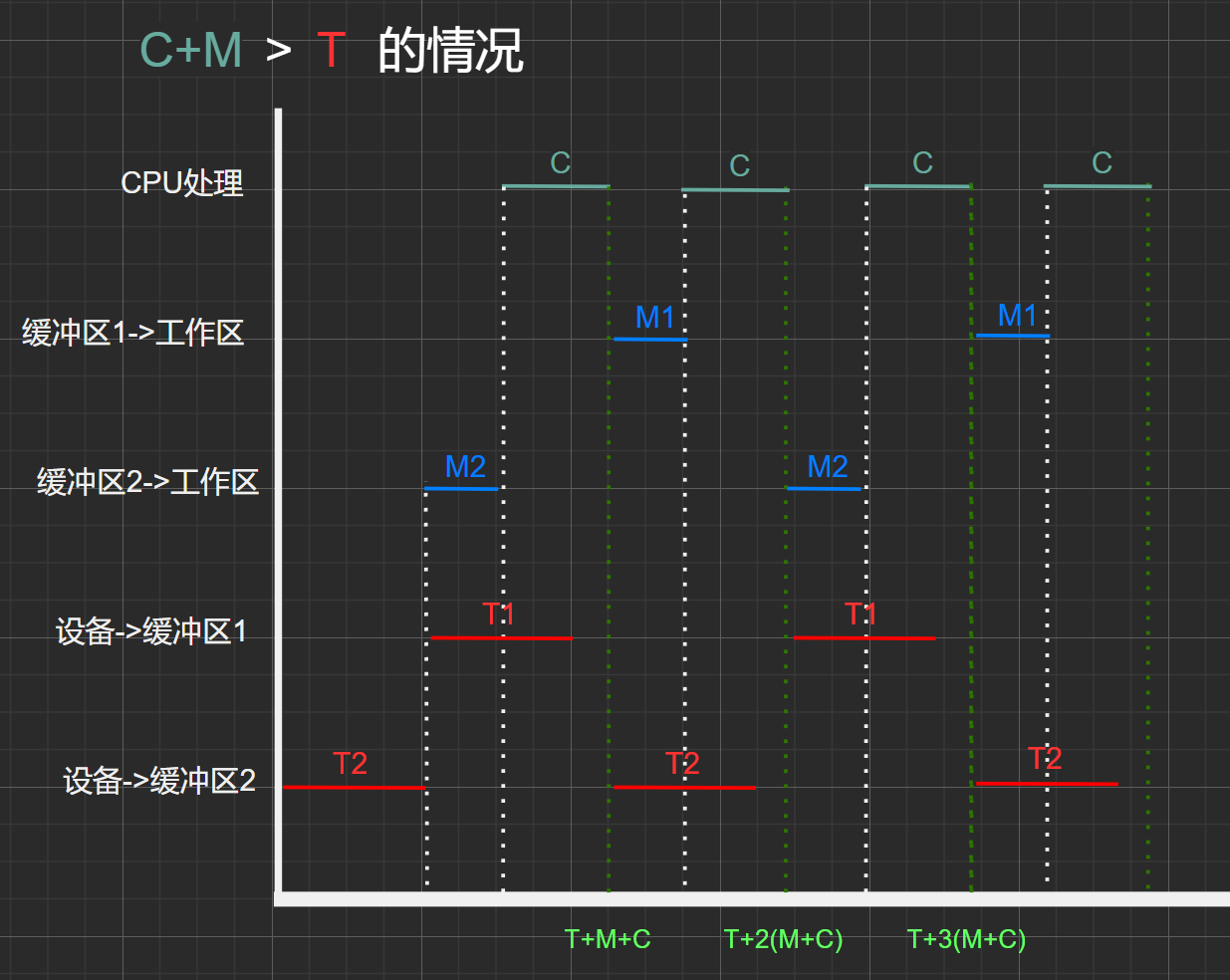 图2.4
图2.4
初始状态:0时刻中工作区,缓冲区1、缓冲区2均为空
- \(T时刻\):工作区为空、缓冲区2为满、缓冲区1为空
- \(T+M+C时刻:\) 工作区为空、缓冲区2为空、缓冲区1为满
- \(T+2(M+C)时刻:\)工作区为空、缓冲区2为满、缓冲区1为空,达到了\(T时刻\)相同的状态,因此
- 可得,时间\([T+2(M+C)]-T = 2(M+C)\)为一周期,其中处理了两个数据块(C)
- 因此,在处理时间(C)+传送时间(M) > 处理时间(C)的情况下,平均处理一个数据块所需时间为:\(2(M+C)/2=M+C\)
同理,可将\(T、2T、3T\)时间点看成相同的状态:工作区为空,一个缓冲区为满、一个缓冲区为空。
也就是说,\(2T\) ~ \(T\)可看作一个周期
找规律:
仔细观察,会发现,这双缓冲区与单缓冲区类似,每个周期内,区间总时间内有一部分是重叠,且时间取最大值:\(MAX(C+M,T)\) ,而取这最大值的区域刚好为一个周期范围,同时包括了三种操作。因此可得一个周期的时间为该最大值,且在这时间内刚好处理了一块数据块。
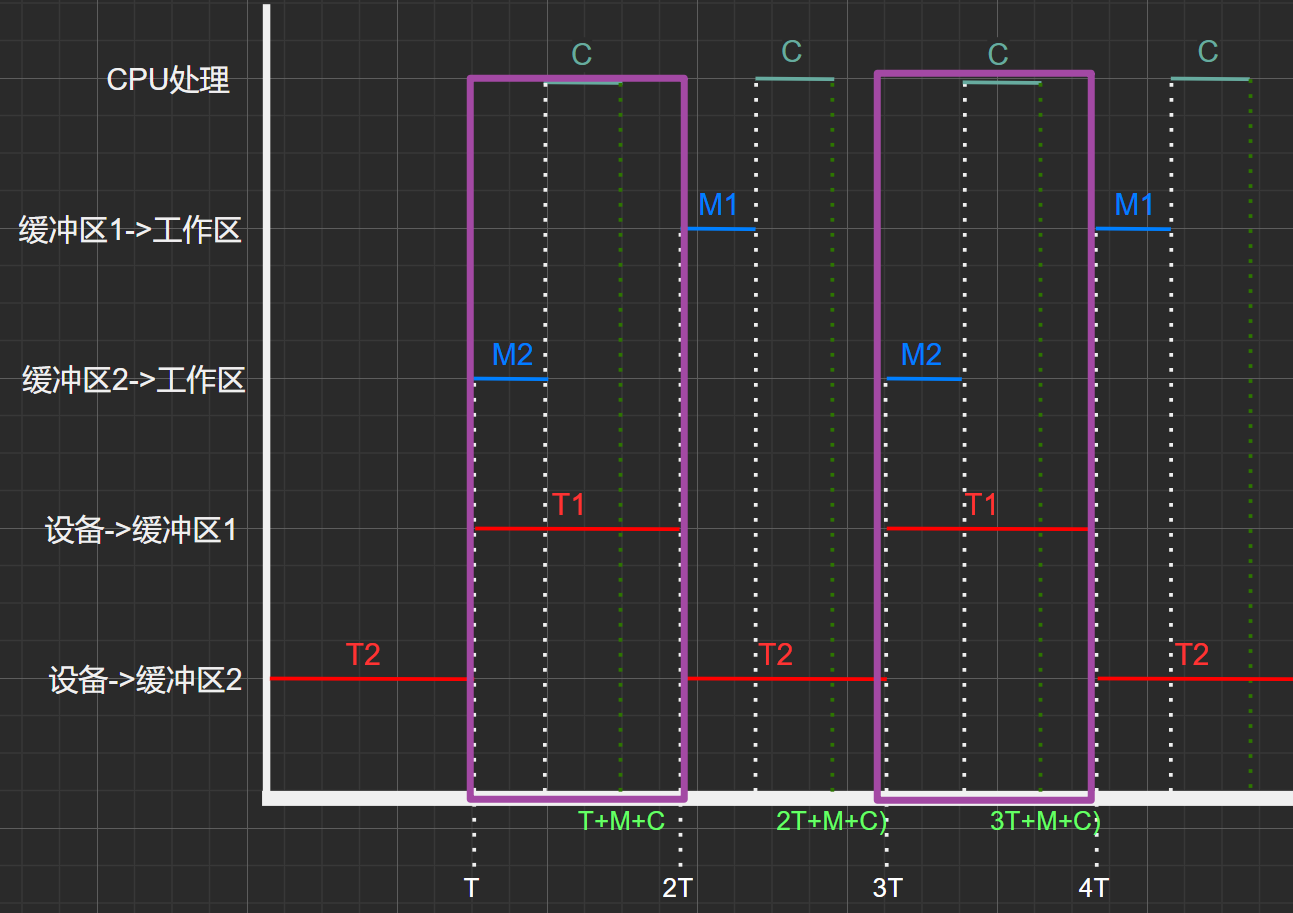 图2.5
图2.5
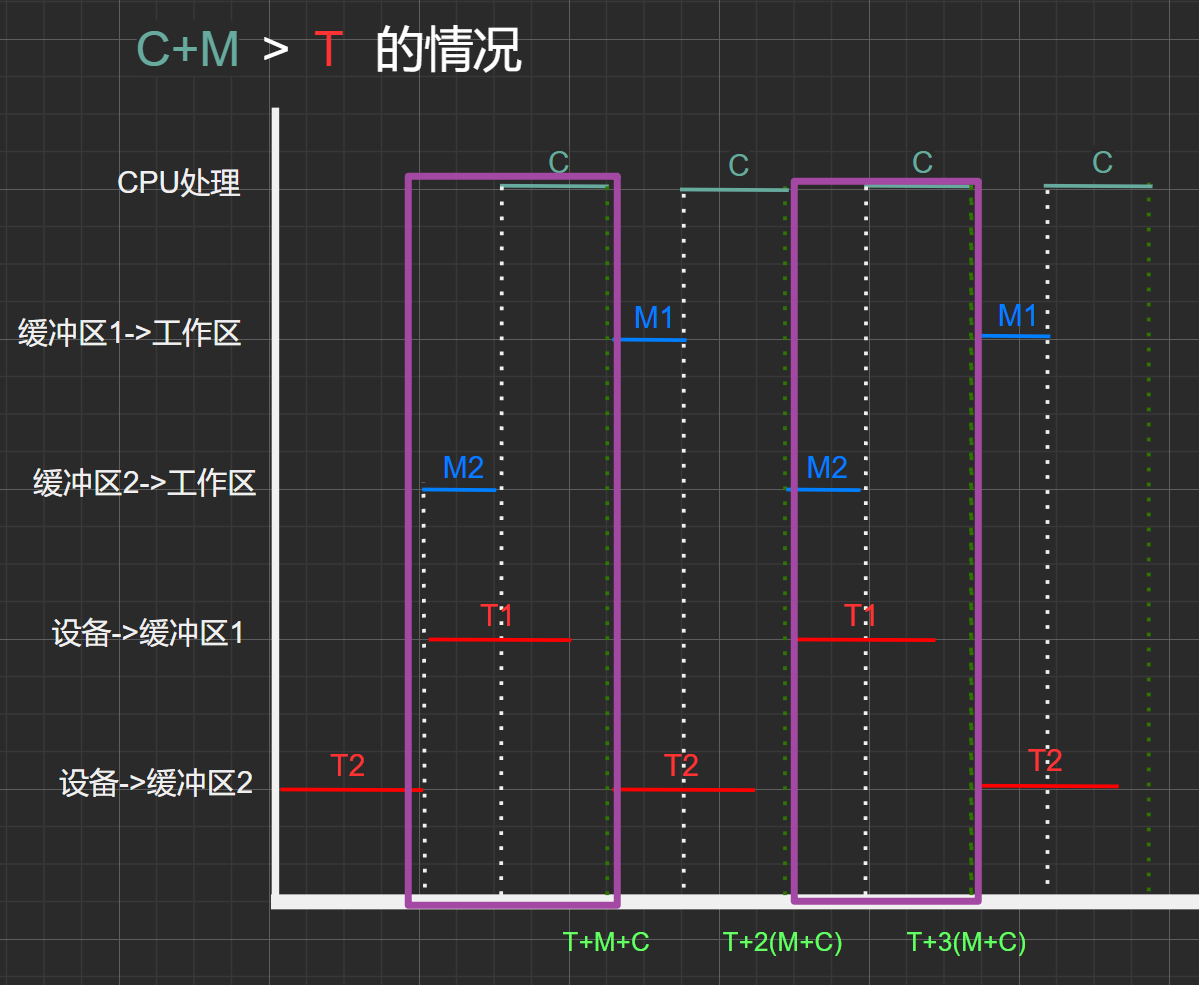 图2.6
图2.6
**因此,不论是 (C+M)>T 还是 (C+M)<T ,缓冲区平均处理一个数据块的时间为:\(MAX(C+M,T)\) **
类似于单缓冲区中的问题,让我们来看一下\(N\)块数据块的从设备->缓冲区->工作区->cup处理的时间要多少。
从图中可以很明显的看出所需时间为:\(T+M+C\) 并不是 \(MAX(C+M,T)\)
我们所求时间为:\(设备->缓冲区->工作区->CPU处理\)
与我们求公式时选定的周期时间:\(MAX(缓冲区->工作区->CPU处理,设备->缓冲区)\)
不一致。
接下来让我们找一找内在联系
这里还是以CPU处理结束的结束作为一个数据块处理完毕的标志。
-
考虑 (C+M) <T 的情况:
由上图2.5可知,在时间段\(0\)~\(3T+M+C\)中共处理了三个数据块
\(T_{总}=\) \(T+MAX(M+C,T)+MAX(M+C,T)+M+C\)
\(= T+2*MAX(M+C,T)+M+C\)
-
考虑 (C+M) >T 的情况:
由上图2.6可知,在时间段\(0\)~\(T+3(M+C)\)中共处理了三个数据块
\(T_{总}=\) \(T+MAX(M+C,T)+MAX(M+C,T)+M+C\)
\(= T+2*MAX(M+C,T)+M+C\)
因此,不论是 (C+M)>T 还是 (C+M)<T ,\(N\)块数据块从设备->缓冲区->工作区->cup处理耗时为:\(T+(N-1)*MAX(M+C,T)+M+C\)
\(=T+(N-1)*缓冲区平均处理一块数据块的时间+M+C\)
例题
某文件占10个磁盘块,现要把该文件的磁盘块逐个读入主存缓冲区,并送入用户去进行分析,假设一个缓冲区与一个磁盘块大小相同,把一个磁盘块读入缓冲区的时间为100μs,将缓冲区的数据传送到用户区的时间是50μs,CPU对一块数据进行分析的时间为50μs。在双缓冲区的结构下,读入并分析该文件的时间是多少?
甘特图:
初始状态为:工作区、缓冲区1、缓冲区2均为空。
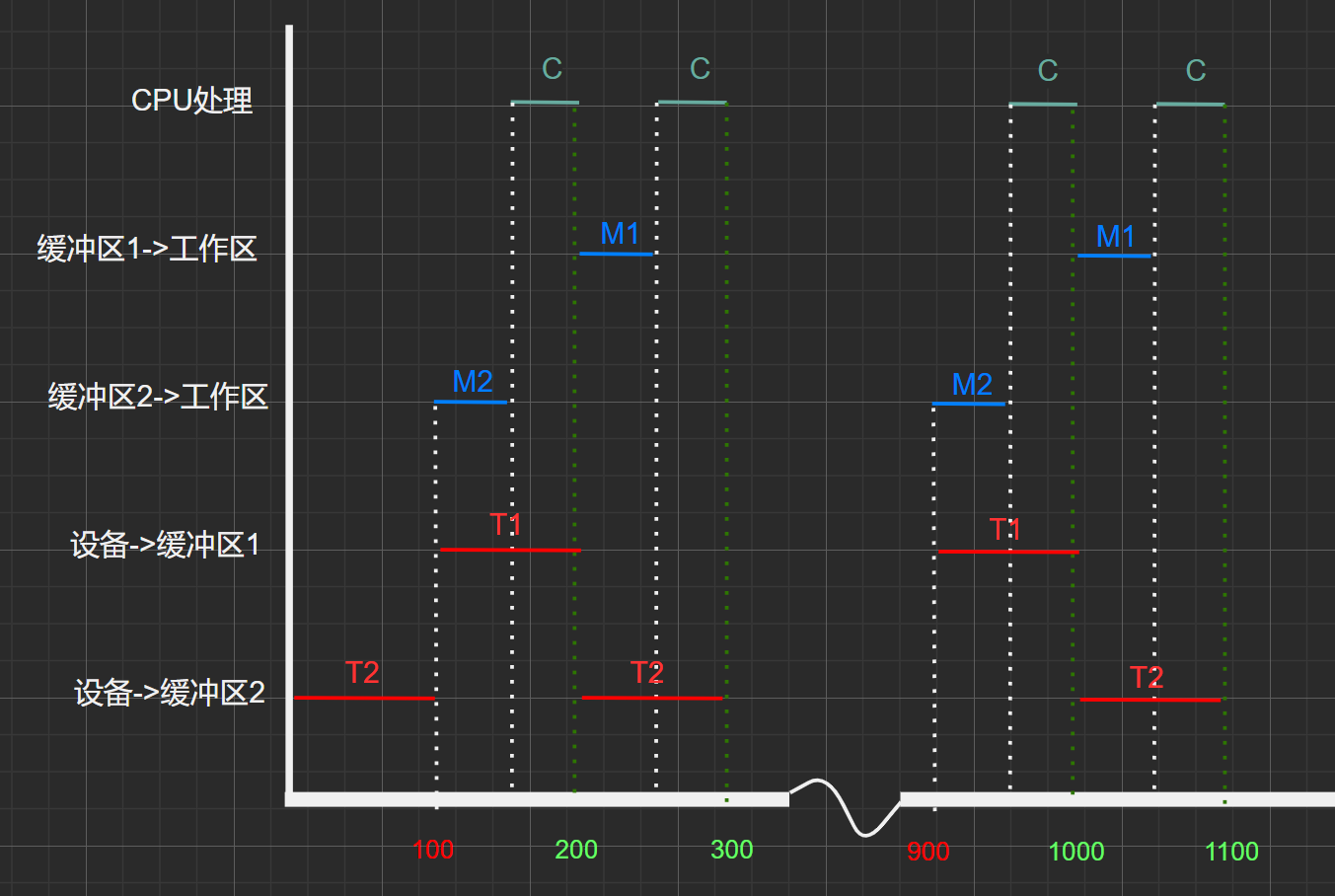
套用公式:
\(T+(N-1)*MAX(M+C,T)+M+C\)
\(=T+(N-1)*缓冲区平均处理一块数据块的时间+M+C\)
\(=100μs+(10-1)*MAX[(50+50)μs,100μs]+50+50=1100μs\)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了