Kafka:副本同步机制(HW&Leader Epoch)
通常,Kafka中的每个Partiotion中有多个副本(Replica)用于实现高可用,使用相关命令可以查看某一Topic中的Partition数量、Leader、Follower以及ISR的情况:
[root@test-ece-kafka2 kafka]# ./bin/kafka-topics.sh --describe --zookeeper test-ece-zk1:2181 --topic uat-log
Topic:uat-log PartitionCount:5 ReplicationFactor:2 Configs:
Topic: uat-log Partition: 0 Leader: 1 Replicas: 1,3 Isr: 3,1
Topic: uat-log Partition: 1 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: uat-log Partition: 2 Leader: 3 Replicas: 3,2 Isr: 2,3
Topic: uat-log Partition: 3 Leader: 1 Replicas: 1,2 Isr: 2,1
Topic: uat-log Partition: 4 Leader: 2 Replicas: 2,3 Isr: 2,3
想象一个场景,Consumer正在消费Leader中Offset=10的数据,而此时Follower中只同步到Offset=8。那么当Leader所在的Broker宕机后,当前Follower经选举成为新的Leader,Consumer再次消费时便会报错。因此,Kafka引入了High Watermark(高水位)来保证副本数据的可靠性和一致性。
High Watermark(HW)#
HW定义了消息的可见性,即标识Partition中的哪些消息是可以被Consumer消费的,只有小于HW值的消息才被认为是已备份或已提交的(committed)。而LEO(Log End Offset)则表示副本写入下一条消息的Offset,因此同一副本的HW值永远不会大于其LEO值。
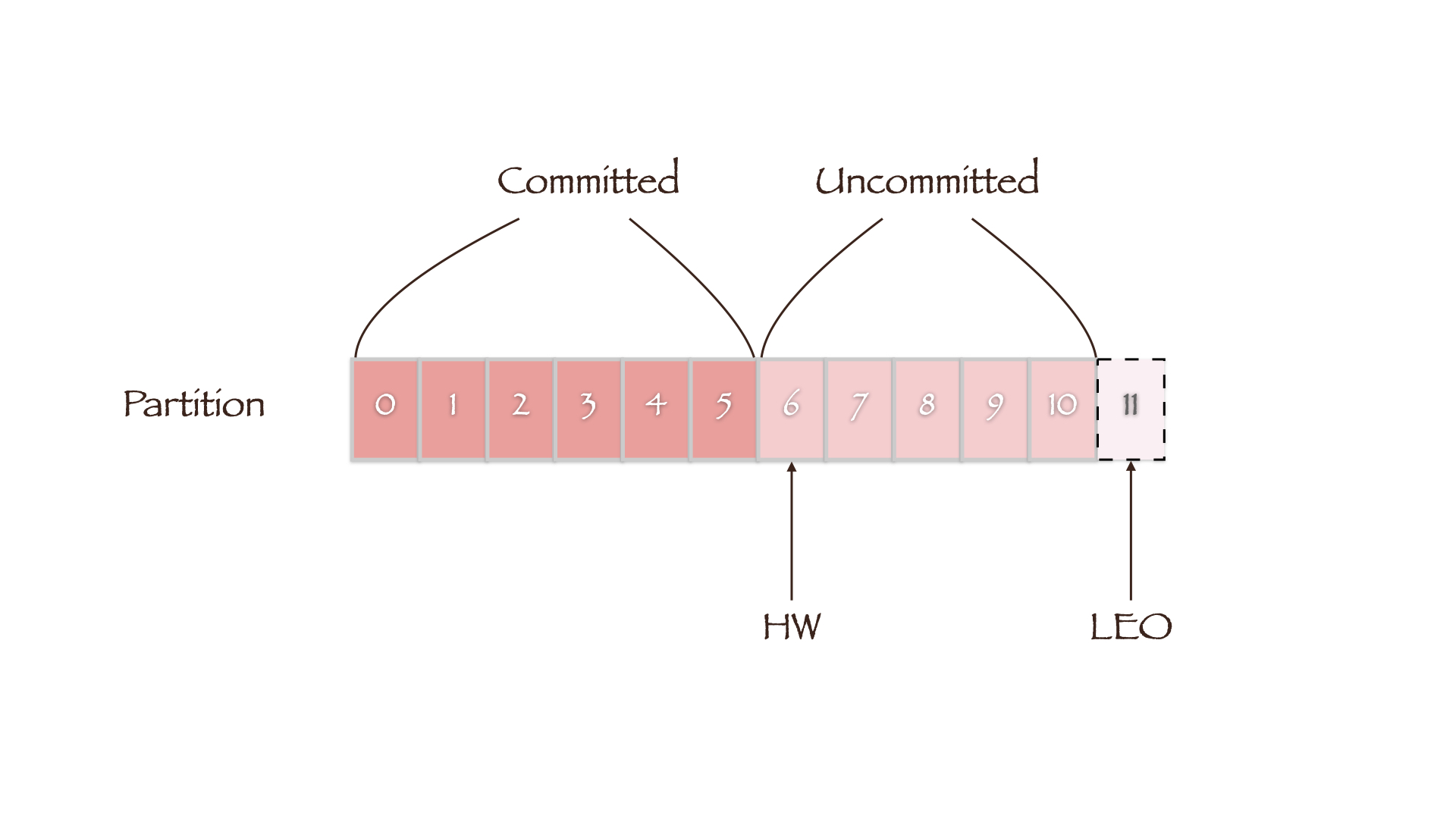
当集群中副本所在的Broker发生故障而后恢复时,副本先将数据截断(Truncation)到其HW处(LEO等于HW),然后再开始向Leader同步数据。
HW的更新机制#
每一个副本都保存了其HW值和LEO值,即Leader HW(实际上也是Partition HW)、Leader LEO和Follower HW、Follower LEO。而Leader所在的Broker上还保存了其他Follower的LEO值,称为Remote LEO。上述几个值的更新流程如下:
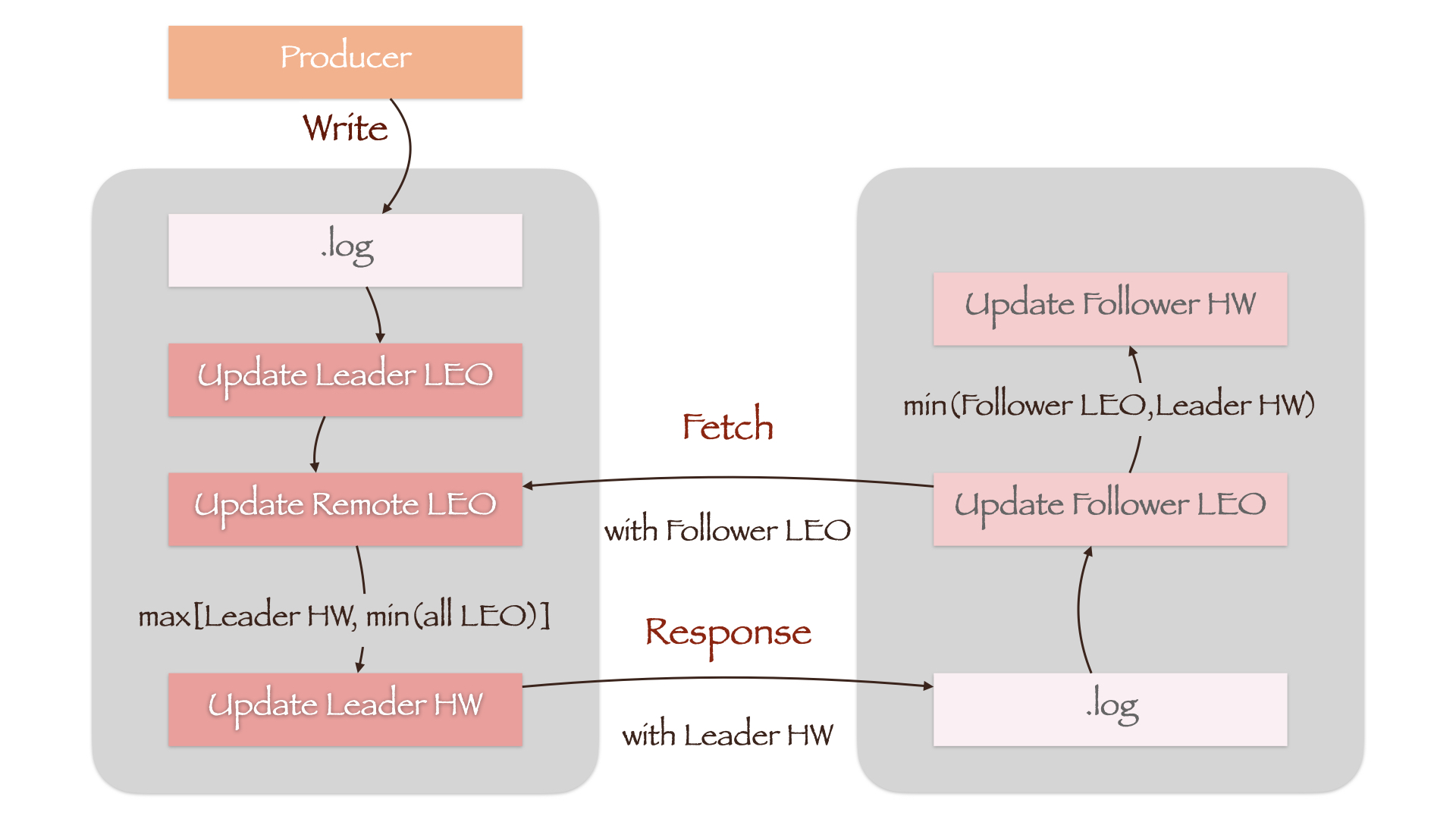
如图所示,当Producer向.log文件写入数据时,Leader LEO首先被更新。而Remote LEO要等到Follower向Leader发送同步请求(Fetch)时,才会根据请求携带的当前Follower LEO值更新。随后,Leader计算所有副本LEO的最小值,将其作为新的Leader HW。考虑到Leader HW只能单调递增,因此还增加了一个LEO最小值与当前Leader HW的比较,防止Leader HW值降低(max[Leader HW, min(All LEO)])。
Follower在接收到Leader的响应(Response)后,首先将消息写入.log文件中,随后更新Follower LEO。由于Response中携带了新的Leader HW,Follower将其与刚刚更新过的Follower LEO相比较,取最小值作为Follower HW(min(Follower LEO, Leader HW))。
举例来说,如果一开始Leader和Follower中没有任何数据,即所有值均为0。那么当Prouder向Leader写入第一条消息,上述几个值的变化顺序如下:
| Leader LEO | Remote LEO | Leader HW | Follower LEO | Follower HW | |
|---|---|---|---|---|---|
| Producer Write | 1 | 0 | 0 | 0 | 0 |
| Follower Fetch | 1 | 0 | 0 | 0 | 0 |
| Leader Update HW | 1 | 0 | 0 | 0 | 0 |
| Leader Response | 1 | 0 | 0 | 1 | 0 |
| Follower Update HW | 1 | 0 | 0 | 1 | 0 |
| Follower Fetch | 1 | 1 | 0 | 1 | 0 |
| Leader Update HW | 1 | 1 | 1 | 1 | 0 |
| Leader Response | 1 | 1 | 1 | 1 | 0 |
| Follower Update HW | 1 | 1 | 1 | 1 | 1 |
HW的隐患#
通过上面的表格我们发现,Follower往往需要进行两次Fetch请求才能成功更新HW。Follower HW在某一阶段内总是落后于Leader HW,因此副本在根据HW值截取数据时将有可能发生数据的丢失或不一致。
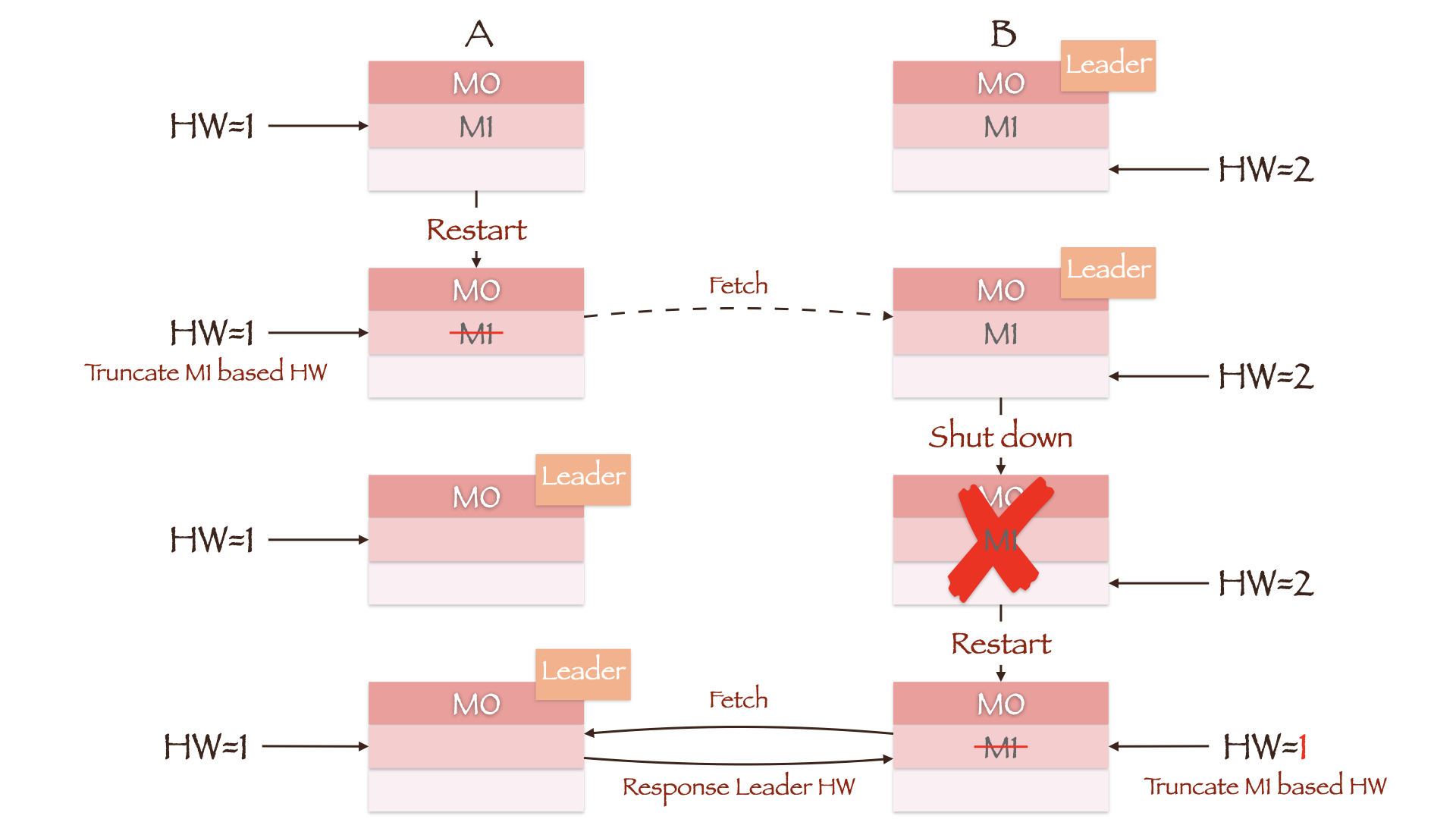
图中两副本的LEO均为2,但Leader副本B上的HW为2,Follower副本A上的HW为1。正常情况下,副本A将在接收Leader Response后根据Leader HW更新其Follower HW为2。但假如此时副本A所在的Broker重启,它会把Follower LEO修改为重启前自身的HW值1,因此数据M1(Offset=1)被截断。当副本A重新向副本B发送同步请求时,如果副本B所在的Broker发生宕机,副本A将被选举成为新的Leader。即使副本B所在的Broker能够成功重启且其LEO值依然为2,但只要它向当前Leader(副本A)发起同步请求后就会更新其HW为1(计算min(Follower LEO, Leader HW)),数据M1(Offset=1)随即被截断。如果min.insync.replicas参数为1,那么Producer不会因副本A没有同步成功而重新发送消息,M1也就永远丢失了。
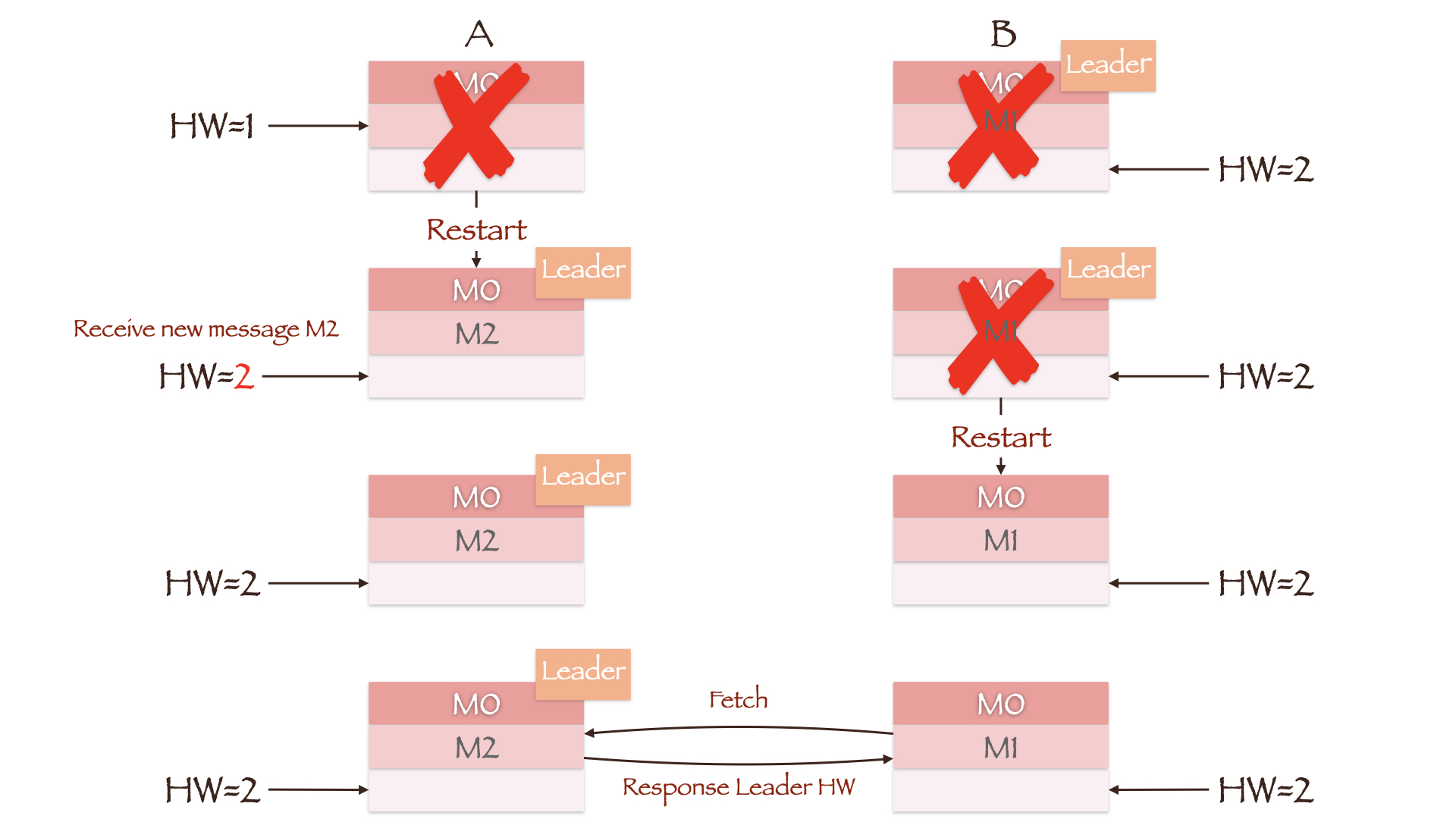
图中Leader副本B写入了两条数据M0和M1,Follower副本A只写入了一条数据M0。此时Leader HW为2,Follower HW为1。如果在Follower同步第二条数据前,两副本所在的Broker均发生重启且副本B所在的Broker先重启成功,那么副本A将成为新的Leader。这时Producer向其写入数据M2,副本A作为集群中的唯一副本,更新其HW为2。当副本B所在的Broker重启后,它将向当前的Leader副本A同步数据。由于两者的HW均为2,因此副本B不需要进行任何截断操作。在这种情况下,副本B中的数据为重启前的M0和M1,副本A中的数据却是M0和M2,副本间的数据出现了不一致。
Leader Epoch#
Kakfa引入Leader Epoch后,Follower就不再参考HW,而是根据Leader Epoch信息来截断Leader中不存在的消息。这种机制可以弥补基于HW的副本同步机制的不足,Leader Epoch由两部分组成:
- Epoch:一个单调增加的版本号。每当Leader副本发生变更时,都会增加该版本号。Epoch值较小的Leader被认为是过期Leader,不能再行使Leader的权力;
- 起始位移(Start Offset):Leader副本在该Epoch值上写入首条消息的Offset。
举例来说,某个Partition有两个Leader Epoch,分别为(0, 0)和(1, 100)。这意味该Partion历经一次Leader副本变更,版本号为0的Leader从Offset=0处开始写入消息,共写入了100条。而版本号为1的Leader则从Offset=100处开始写入消息。
每个副本的Leader Epoch信息既缓存在内存中,也会定期写入消息目录下的leaderer-epoch-checkpoint文件中。当一个Follower副本从故障中恢复重新加入ISR中,它将:
- 向Leader发送LeaderEpochRequest,请求中包含了Follower的Epoch信息;
- Leader将返回其Follower所在Epoch的Last Offset;
- 如果Leader与Follower处于同一Epoch,那么Last Offset显然等于Leader LEO;
- 如果Follower的Epoch落后于Leader,则Last Offset等于Follower Epoch + 1所对应的Start Offset。这可能有点难以理解,我们还是以(0, 0)和(1, 100)为例进行说明:Offset=100的消息既是Epoch=1的Start Offset,也是Epoch=0的Last Offset;
- Follower接收响应后根据返回的Last Offset截断数据;
- 在数据同步期间,只要Follower发现Leader返回的Epoch信息与自身不一致,便会随之更新Leader Epoch并写入磁盘。
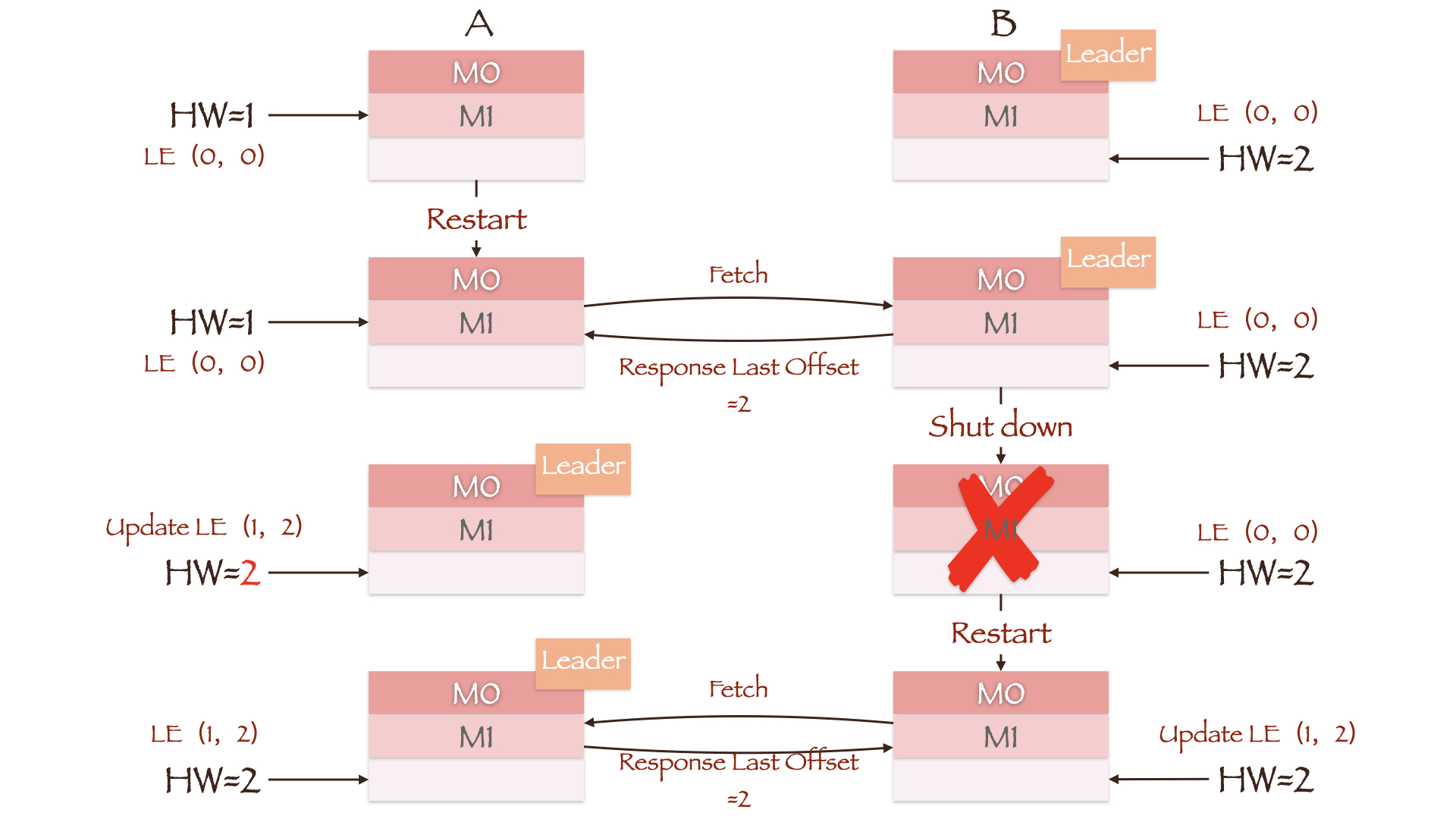
在刚刚介绍的数据丢失场景中,副本A所在的Broker重启后根据自身的HW将数据M1截断。而现在,副本A重启后会先向副本B发送一个请求(LeaderEpochRequest)。由于两副本的Epoch均为0,副本B返回的Last Offset为Leader LEO值2。而副本A上并没有Offset大于等2的消息,因此无需进行数据截断,同时其HW也会更新为2。之后副本B所在的Broker宕机,副本A成为新的Leader,Leader Epoch随即更新为(1, 2)。当副本B重启回来并向当前Leader副本A发送LeaderEpochRequest,得到的Last Offset为Epoch=1对应的Start Offset值2。同样,副本B中消息的最大Offset值只有1,因此也无需进行数据截断,消息M1成功保留了下来。
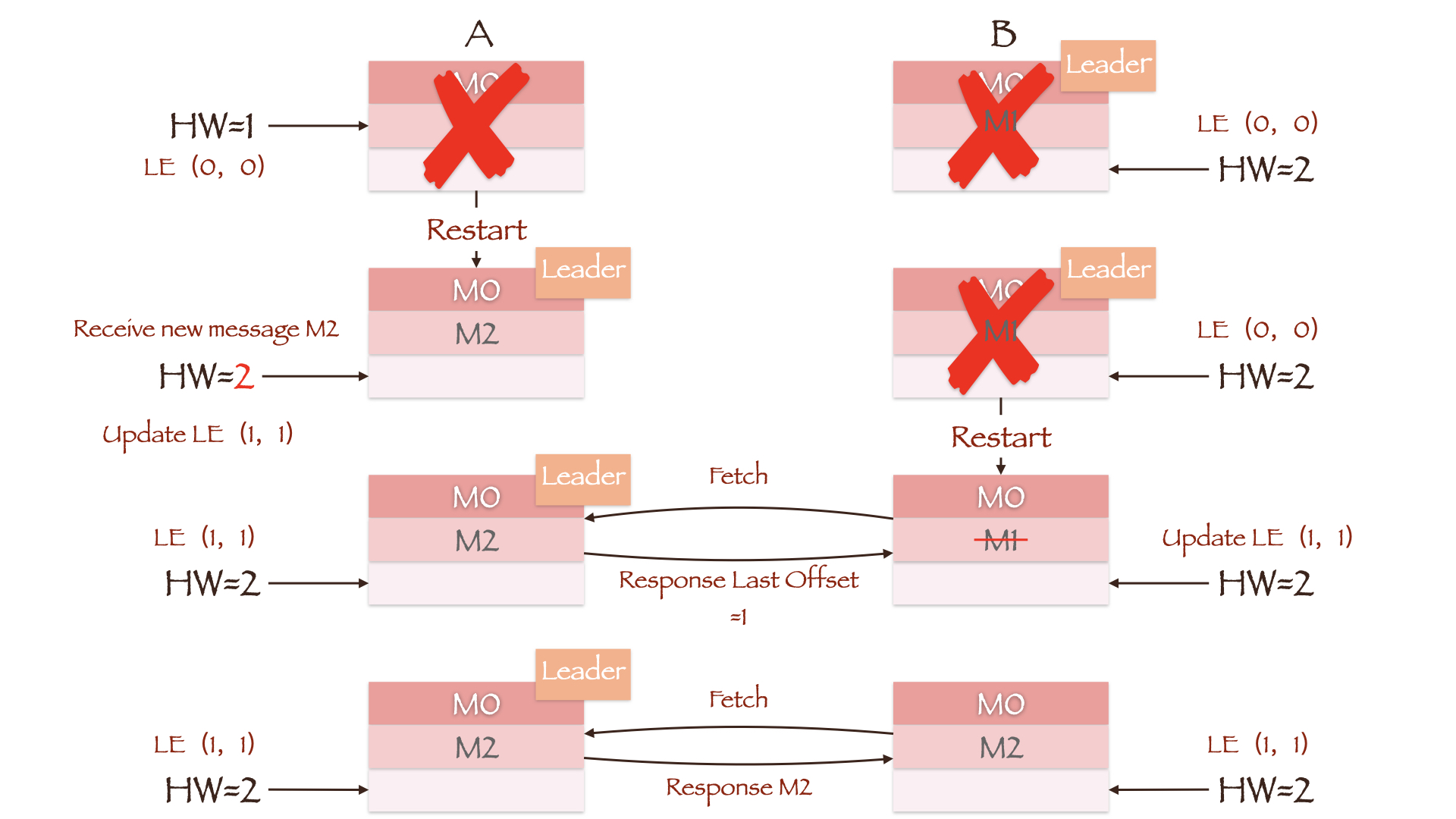
在刚刚介绍的数据不一致场景中,由于最后两副本HW值相等,因此没有将不一致的数据截断。而现在,副本A重启后并便会更新Leader Epoch为(1, 1),同时也会更新其HW值为2。副本B重启后向当前Leader副本A发送LeaderEpochRequest,得到的Last Offset为Epoch=1对应的Start Offset值1,因此截断Offset=1的消息M1。这样只要副本B再次发起请求同步消息M2,两副本的数据便可以保持一致。
值得一提的是,Leader Epoch机制在min.insync.replicas参数为1且unclean.leader.election.enabled参数为true时依然无法保证数据的可靠性。这里不再赘述,可参考KIP-101 - Alter Replication Protocol to use Leader Epoch rather than High Watermark for Truncation文中的附录部分。
作者:koktlzz
出处:https://www.cnblogs.com/koktlzz/p/14580109.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!