Kafka基础
架构#
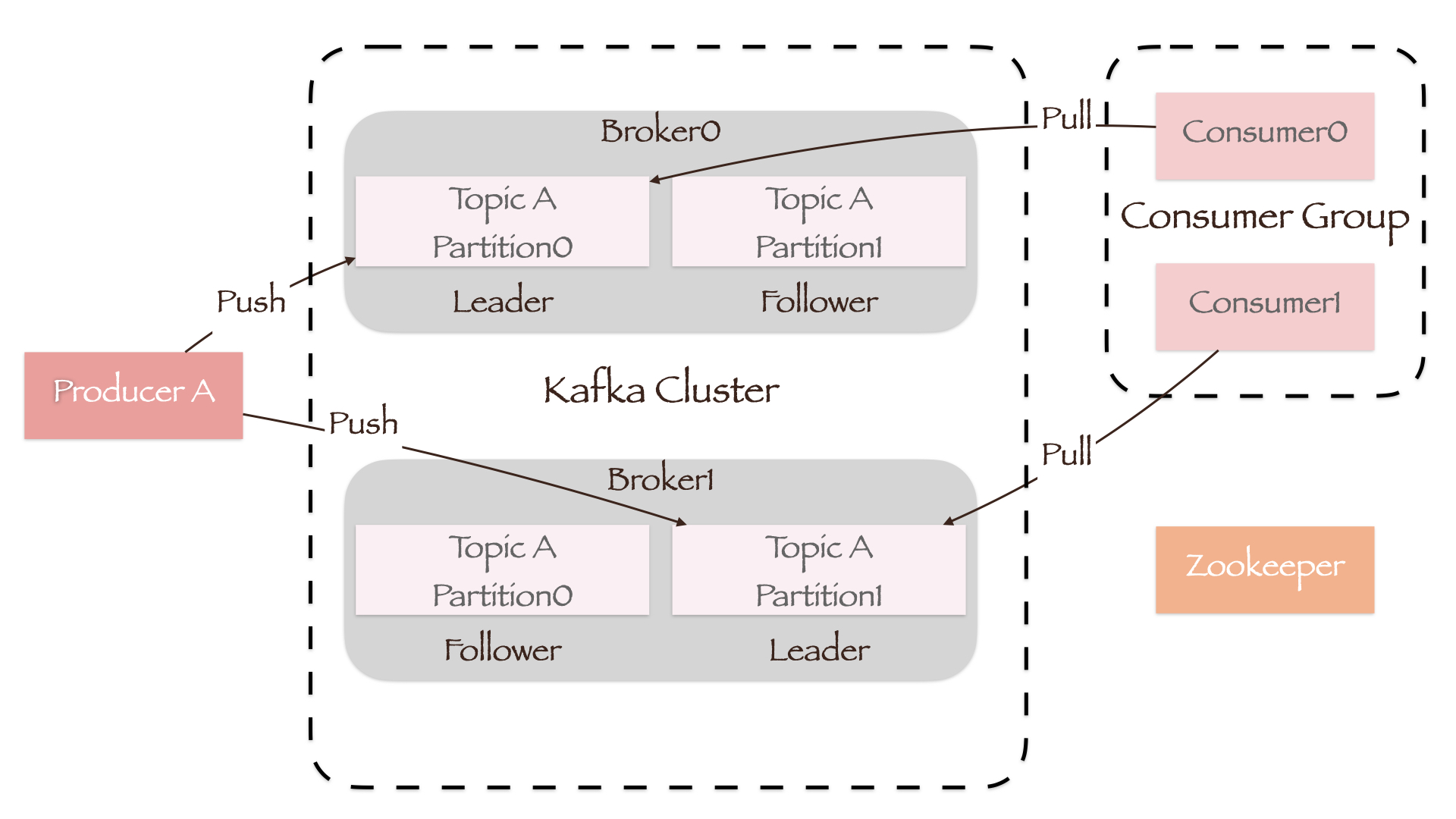
概念#
- Broker:Kafka集群中的一台或多台服务器;
- Topic:逻辑概念。根据消息的类型,将其分为各种主题(Topic),以此区分不同的业务数据;
- Partition:物理概念。每个Topic可分为多个分区(Partition),而每个Partition都是有序且顺序不变的消息队列;
- Offset:每条消息都会被分配一个连续的、在其Partition内唯一的标识来记录顺序,即偏移量(Offset);
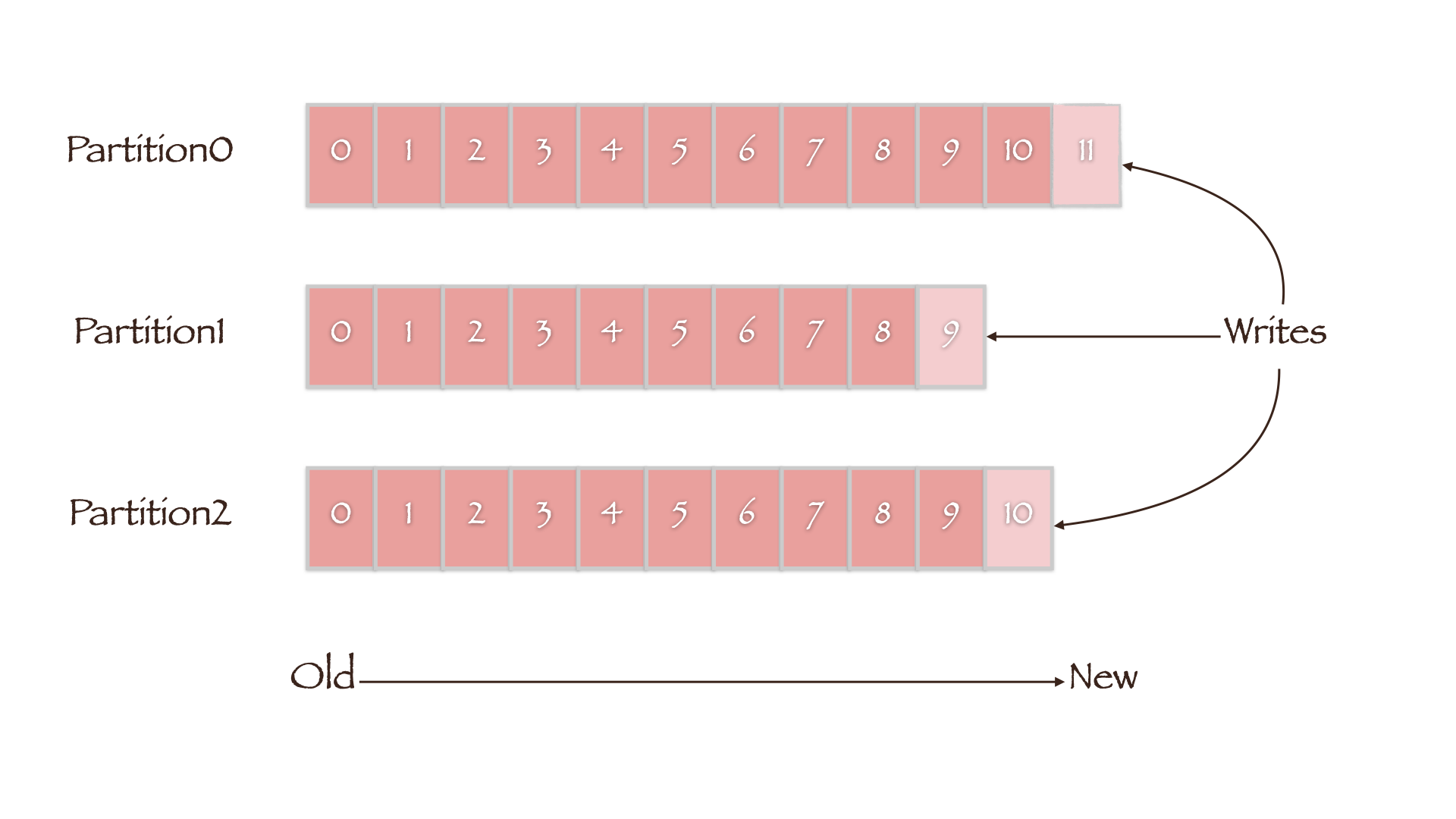
- Replica:可以为每个Partition创建副本(Replica)来实现高可用;
- Leader/Follwer:一个Leader副本处理读写请求,多个Follower副本同步数据。每台Broker上都维护着某些Partition的Leader副本和某些Partition的Follower副本,因此集群的负载是均衡的;
- Producer:消息的生产者,将数据主动发送到指定的Topic;
- Consumer:消息的消费者,从订阅的Topic中主动拉取数据;
- Consumer Group:将多个Consumer划分为组,组内的Consumer可以并行地消费Topic中的数据;
- Zookeeper:Kafka集群中的一个Broker会被选举为Controller,负责管理集群中其他Broker的上下线、Partition副本的分配和ISR成员变化、Leader的选举等工作。而Controller的管理工作依赖于Zookeeper,Broker必须能通过Zookeeper的心跳机制维持其与Zookeeper的会话。
基本配置#
[root@test-ece-kafka2 kafka_2.11-1.1.1]# ls config/
connect-console-sink.properties connect-file-sink.properties connect-standalone.properties producer.properties zookeeper.properties
connect-console-source.properties connect-file-source.properties consumer.properties server.properties
connect-distributed.properties connect-log4j.properties log4j.properties tools-log4j.properties
Kafka的基本配置在安装目录中config下的server.properties文件中:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
# A comma separated list of directories under which to store log files
log.dirs=/data/kafka/logs
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=72
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
# zookeeper cluster
zookeeper.connect=test-ece-zk1:2181,test-ece-zk2:2181,test-ece-zk3:2181
常用命令#
启动
bin/kafka-server-start.sh config/server.properties
创建Topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
查看Topic
bin/kafka-topics.sh --list --zookeeper localhost:2181
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
消费消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
Producer#
消息的生产者,将数据主动发送到指定的Topic。
- 由于只有Leader副本处理读写请求,因此Producer会将消息发送到Leader所在的Broker上。为了实现这一功能,所有Broker都能响应其请求:哪些Broker存活(alive)和Partition中的Leader在哪台Broker上。
- 为了提升性能,Producer会尝试在内存中汇总数据,并用一次请求批量发送消息。这种处理方式不仅可以指定批量发送的消息数量,也可以指定等待的延迟时间(如10ms),这将允许汇总更多的数据后再发送,从而减少在Broker端的IO操作。
Partition#
Kafka中的每个Topic可分为多个分区(Partition),这样做的目的是:
- 水平扩展:每个单独的Partition受限于其所在Broker的文件限制,因此可以通过增加Partition数量来增大数据量;
- 负载均衡:Partition由多台Broker维护,并发处理请求从而分担读写压力。
Producer只关心消息发往哪个Topic,至于消息具体发送到哪一个Partition是由分配策略决定的:
- 当指定Partition的情况下,直接分配到对应的Partition;
- 没有指定Partition但指定了消息的键值key,将使用key的hash值与Topic的Partition数进行取余得到Partition值,即
hash(key) % numPartitions。因此我们可以指定用户id作为key,那么跟用户有关的所有数据都将发送到同一Partition中。; - 若两者都没有指定,第一次分配消息时会随机生成一个整数(之后再次分配会自增),将此值Partition数进行取余得到Partition值(即Round-Robin算法)。
Partition中的数据是直接写入磁盘的,其过程是将消息一直追加到文件末端,这样便可以省去大量磁头寻址的过程。
相比于维护尽可能多的 in-memory cache,并且在空间不足的时候匆忙将数据 flush 到文件系统,我们把这个过程倒过来。所有数据一开始就被写入到文件系统的持久化日志中,而不用在 cache 空间不足的时候 flush 到磁盘。实际上,这表明数据被转移到了内核的 pagecache 中。
Partition在底层被拆分成了一个个segment,而每个segment则由一个.log文件和一个.index文件组成:
[root@test-ece-kafka2 ~]# ls /data/kafka/logs/<topic-partition_number>
00000000000000083456.index 00000000000000083456.snapshot 00000000000000126371.index 00000000000000126371.snapshot leaderer-epoch-checkpoint
00000000000000083456.log 00000000000000083456.timeindex 00000000000000126371.log 00000000000000126371.timeindex
- 当起始.log文件大小超过Kafka配置文件中
log.segment.bytes参数指定的值,就会创建新的.log文件,即新的segment; - .index和.log文件以当前segment的第一条消息的Offset命名;
- .index文件中保存了每条消息的Offset值、在.log文件中存储的物理偏移地址和大小,因此Consumer在消费时可以很快的根据.index文件找到指定消息在.log文件中的位置。具体过程如下:Consumer将当前消费消息的Offset值与.index文件名中的数字对比,找到该消息所在的.index文件。随后在.index文件中找到该消息在.log文件中的起始地址,并根据消息大小确定其在.log文件中的终止地址,从而拿到完整的目标消息。
- leaderer-epoch-checkpoint文件保存了Partition的Leader Epoch信息,详见Leader Epoch。
Consumer#
Consumer采用主动拉取(Pull)的方式从Broker中读取数据,因此可以根据Consumer的消费能力以适当的速率消费数据。这种方式与Broker主动向Consumer推送(Push)消息相比,可以防止Consumer因不堪重负而出现拒绝服务、网路堵塞等问题。但如果Topic中已经没有数据,Consumer依然会向Broker不断发起Pull请求。为此Kafka引入了一个时长参数timeout,即如果当前没有数据可供消费,Consumer会等待一段时间之后再重新开始拉取数据。
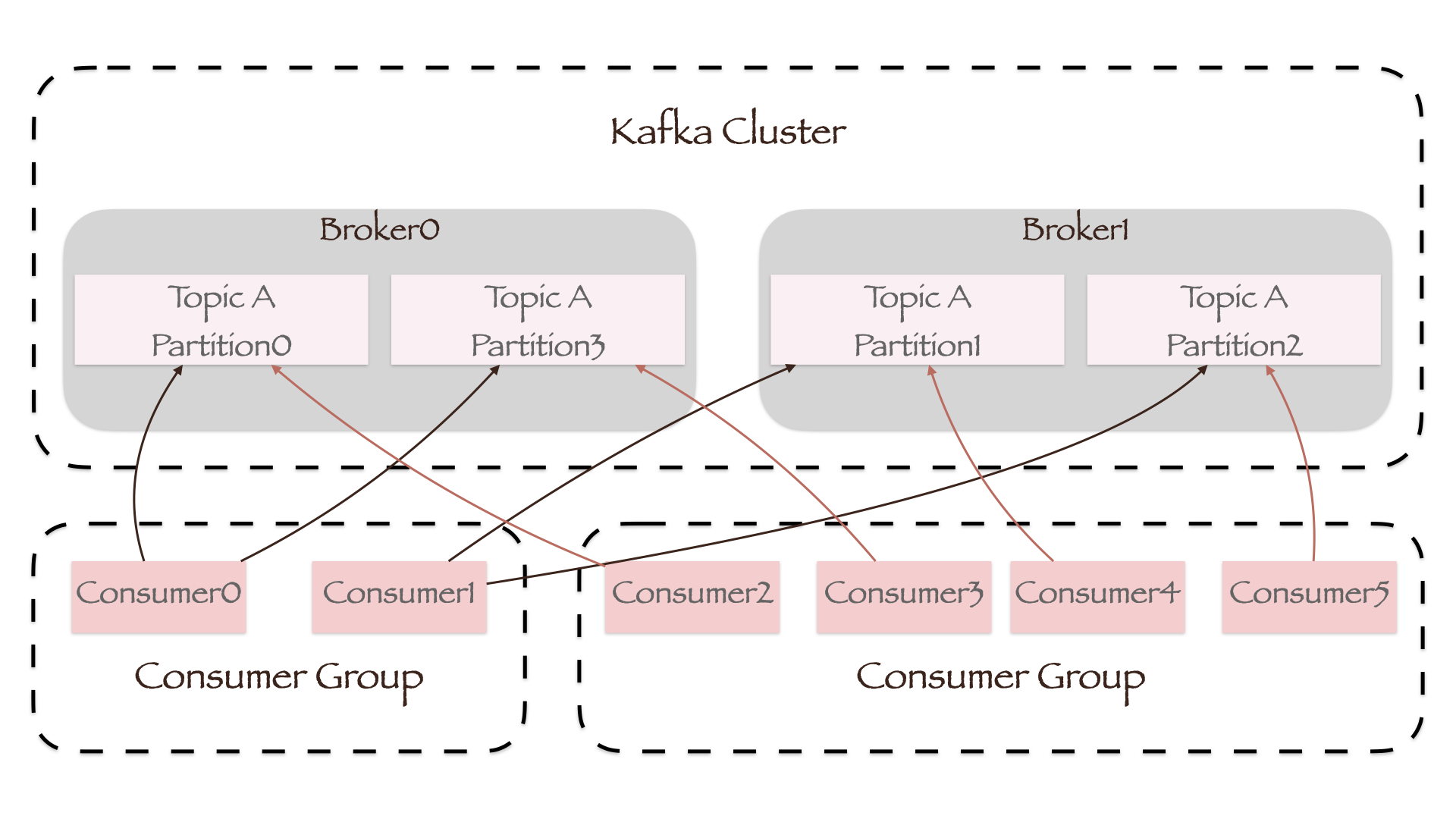
每个Topic中的一个Partition只能被一个Consumer Group中的一个Consumer消费,而Consumer到底消费哪一个Partition是由Consumer客户端的partition.assignment.strategy参数,即Partition的分配策略所决定的。Kafka目前支持三种分配策略:
- Range:参数值为
org.apache.kafka.clients.consumer.RangeAssignor。对于每一个Topic,RangeAssignor将Consumer Group内所有订阅该Topic的Consumer名称按照字典顺序排序,然后为每个Consumer平均分配n个Partition(n=Partition数/Consumer数)。m个多余的Partition(m=Partition数%Consumer数)将会按序分配给字典顺序靠前的Consumer; - RoundRobin:参数值为
org.apache.kafka.clients.consumer.RoundRobinAssignor。RoundRobinAssignor将Consumer Group内所有Consumer以及Consumer订阅的所有Topic中的Partition按照字典顺序排序,然后通过轮询Consumer方式逐个将Partition分配给每个Consumer; - Sticky:参数值为
org.apache.kafka.clients.consumer.StickyAssignor。StickyAssignor除了要保证Partition均匀分配之外,还会尽可能保证集群变动前后多次Partition分配的结果相同。
详见:Kafka Range、RoundRobin、Sticky 三种分区分配策略区别
由于Consumer在消费过程中可能会出现断电宕机等故障,当其恢复后需要从故障前的位置的继续消费,因此Consumer需要实时记录当前消费的Offset。而Offset保存在Kafka的内置Topic中,即_consumer_offsets。
在每一个消费者中唯一保存的元数据是offset(偏移量)即消费在log中的位置.偏移量由消费者所控制:通常在读取记录后,消费者会以线性的方式增加偏移量,但是实际上,由于这个位置由消费者控制,所以消费者可以采用任何顺序来消费记录。例如,一个消费者可以重置到一个旧的偏移量,从而重新处理过去的数据;也可以跳过最近的记录,从"现在"开始消费。
数据可靠性#
Kafka通过以下机制来保证Producer向Partition发送数据的可靠性:
- 每个Partition在接收到Producer发送的消息后,都要通过其所在的Broker返回一个ACK(Acknowledge)数据包。Producer收到该数据包后才会继续发送消息,否则重新发送消息;
- Leader中维护了一个动态的ISR(in-sync replica set),即与Leader保持同步的Follower集合。当ISR中的Follower完成数据同步后,也会给Leader发送Ack数据包。若在参数
replica.lag.time.max.ms规定的时间内未返回Ack数据包,该Follower将被踢出ISR; min.insync.replicas参数指定了ISR中的最小副本数,默认值为1。
Kafka的吞吐量和可靠性是不可兼得的,我们可以通过调整ACK参数来对其进行权衡。对于某些不太重要的数据,其可靠性要求不是很高,能够容忍数据的少量丢失,因此没必要等ISR中的Follower全部同步完成。
- ACK=0:即使数据还未在某个Partition的Leader上落盘,Producer也会认为消息发送成功,不再等待Broker返回的ACK数据包。若Leader所在的Broker发生故障,则有可能丢失数据;
- ACK=1(默认值):只要Leader接收到Producer发送的消息就返回ACK数据包,Producer认为消息发送成功。如果在Follower同步数据前,Leader所在的Broker发生故障,则有可能丢失数据。如果Follower同步数据成功,但返回的ACK数据包发送失败,Producer会再次发送相同的消息,从而造成数据重复。
- ACK=-1(all):只有ISR中的所有副本均同步完成,Leader才会返回ACK数据包,Producer认为消息发送成功。若
min.insync.replicas值为1且ISR中只有Leader副本,那么即使设置ACK=-1,也和ACK=1的情况相同。
幂等性#
我们已经可以通过调整ACK参数来保证数据不丢失At Least Once(ACK=-1)或者不重复At Most Once(ACK=0)。但对于一些重要信息,如交易数据,Consumer要求数据既不丢失也不能重复。Kafka引入幂等性的特性来保证无论Producer发送多少条重复数据到Partition中,Consumer都只会消费一条有效信息,即Exactly-Once。要启用幂等性,只需将Producer参数中enable.idompotence参数设置为true即可。为了实现幂等性,Kafka在底层设计架构中引入了ProducerID和SequenceNumber两个概念:
- ProducerID:在每个新的Producer初始化时,会被分配一个唯一的ProducerID,这个ProducerID对客户端使用者是不可见的;
- SequenceNumber:对于每个ProducerID,Producer发往同一Partition的不同数据都分别对应了一个从0开始单调递增的SequenceNumber值。
当Producer发送消息(x2,y2)给Broker时,Broker接收到消息并将其追加到消息流中。此时,Broker返回ACK信号给Producer时,发生异常导致Producer接收ACK信号失败。对于Producer来说,会触发重试机制,将消息(x2,y2)再次发送,但是,由于引入了幂等性,在每条消息中附带了PID(ProducerID)和SequenceNumber。相同的PID和SequenceNumber发送给Broker,而之前Broker缓存过之前发送的相同的消息,那么在消息流中的消息就只有一条(x2,y2),不会出现重复发送的情况。
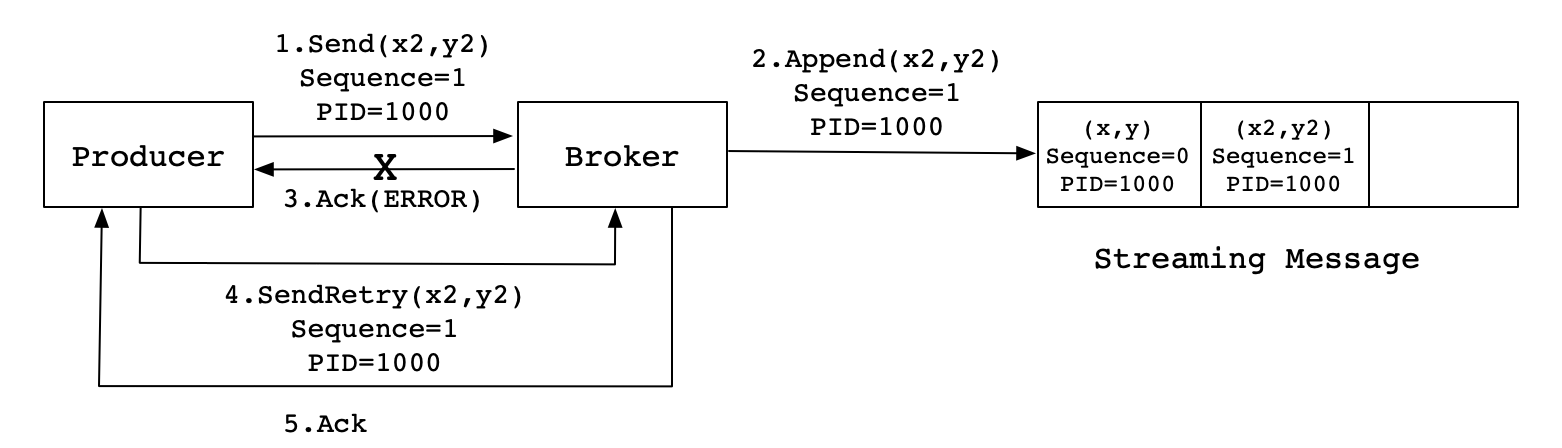 由于Producer重启后ProducerID会发生改变,而不同的Partition也会有不同的SequenceNumber,因此Kafka无法保证跨会话或跨Partition的幂等性。
由于Producer重启后ProducerID会发生改变,而不同的Partition也会有不同的SequenceNumber,因此Kafka无法保证跨会话或跨Partition的幂等性。
参考文献#
KIP-101 - Alter Replication Protocol to use Leader Epoch rather than High Watermark for Truncation
作者:koktlzz
出处:https://www.cnblogs.com/koktlzz/p/14580107.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现