Elasticsearch:Snapshot
我们可以对整个Elasticsearch集群或集群中的部分索引/数据流拍摄快照,从而实现数据的备份。
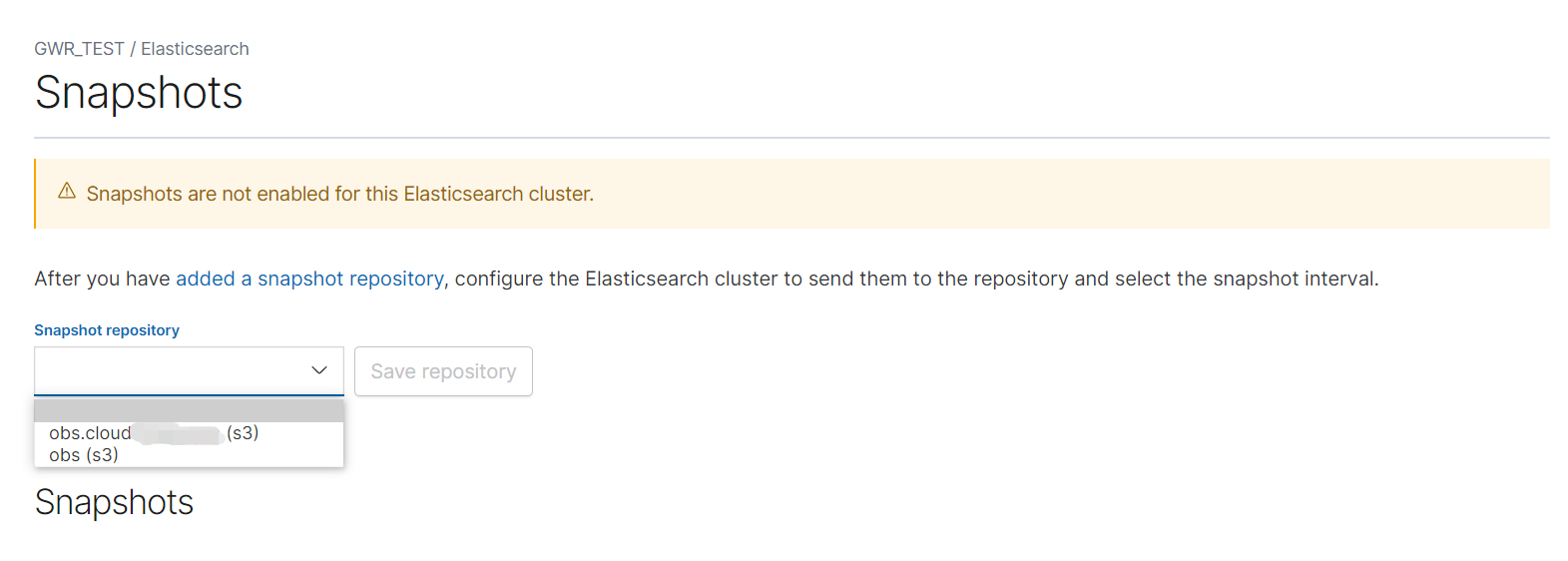
快照仓库(snapshot repository)#
在创建快照前,我们必须注册一个可以存放快照的仓库snapshot repository。snapshot repository既可以是本地仓库,也可以是云服务商通过对象存储技术(Object-based Storage)提供的远程仓库,如Amazon S3, HDFS, Microsoft Azure,和Google Cloud Storage等。如果在多个集群中注册同一快照存储库,则应当只有一个集群具有对该仓库的读写权限,仓库对其他集群应设置为只读。
我们可以通过Snapshot and restore APIs创建、查看或删除快照仓库,也可以在Elastic Cloud的管理界面直接手动操作。
快照生命周期管理(SLM)#
当我们创建了一个快照仓库后,便可以通过Snapshot and restore APIs手动为集群中的索引或数据流创建快照了。但在实际应用中,我们往往需要Elasticsearch能够每隔一段时间便自动拍摄快照,这便是快照生命周期管理SLM(Snapshot Lifecycle Management)策略的作用。
PUT /_slm/policy/nightly-snapshots
{
"schedule": "0 30 1 * * ?", // 每天的1:30分拍摄快照(UTC时间)
"name": "<nightly-snap-{now/d}>", // 快照名称以nightly-snap-开头,以拍摄日期结尾
"repository": "my_repository", // 快照存放于名为my_repository的快照仓库中
"config": {
"indices": ["*"] // 对所有索引/数据流拍摄快照
},
"retention": { // 快照的保留策略与上方快照创建任务的执行无关,但仅对SLM创建的快照有效,不会作用于手动创建的快照上
"expire_after": "30d", // 每个快照保留30天
"min_count": 5, // 快照最少保留5个(若不足5个,则即使超过30天也不会删除)
"max_count": 50 // 快照最多保留50个(若超过50个,则即使不足30天也会删除)
}
}
在Elastic Cloud创建SLM策略则更加方便:
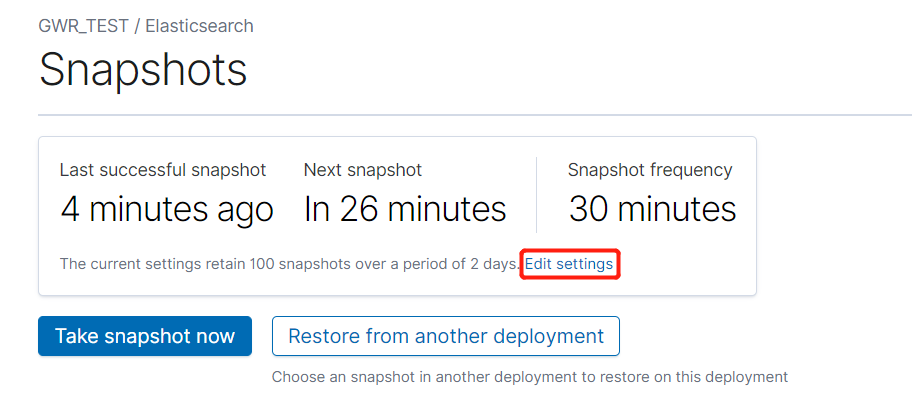
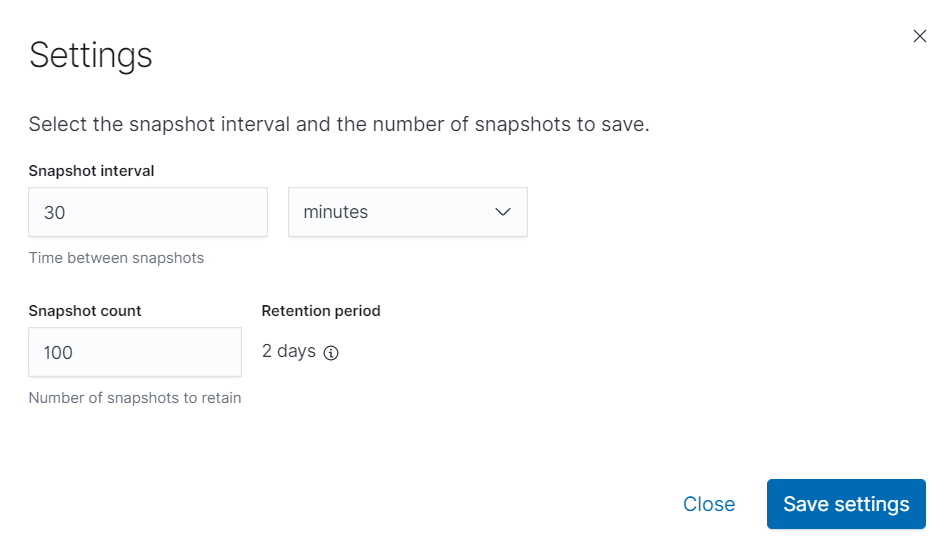
当集群中索引的写入量很大时,SLM通常与ILM搭配使用。想象一个场景:需要保留索引中近三年的数据,但大多数情况下只需查询近两个月的数据。针对这种情况,我们可以将索引ILM策略中的Delete动作设置为每隔60天执行一次,同时SLM策略为每隔55天(小于60即可)拍摄一次快照,保留快照的最大数量为365*3/55,即20个。这样的话,近60天内的索引都将保存在集群中可供搜索。而一旦我们需要查询更久远的数据,只需恢复对应时间的快照即可。
同样,我们可以使用API查看SLM策略的执行情况:
GET /_slm/stats
// 返回
{
"retention_runs": 13, // 快照保留策略执行的次数
"retention_failed": 0,
"retention_timed_out": 0,
"retention_deletion_time": "1.4s", // 执行快照保留策略时删除快照的总用时
"retention_deletion_time_millis": 1404,
"policy_stats": [
{
"policy": "daily-snapshots",
"snapshots_taken": 1, // daily-snapshots策略下创建的快照数
"snapshots_failed": 1,
"snapshots_deleted": 0,
"snapshot_deletion_failures": 0
}
],
"total_snapshots_taken": 1, // 所有策略创建的总快照数
"total_snapshots_failed": 1,
"total_snapshots_deleted": 0,
"total_snapshot_deletion_failures": 0
}
可搜索快照(Searchable snapshot)#
创建#
为不经常被搜索的索引创建可搜索快照,可以节省维护分片副本所消耗的资源,同时也能确保搜索性能不会太差。可以通过Mount snapshot API创建一个与可搜索快照相关联(mount)的索引,例如:
POST /_snapshot/<repository>/<snapshot>/_mount
{
"index": "my_docs", // 快照中被关联的索引
"renamed_index": "docs", // 新创建的集群中的索引
"index_settings": {
"index.number_of_replicas": 0 // 对新索引的设置
}
}
当新索引创建成功后,其分片所在节点会开始从快照仓库中同步数据。当数据同步完毕后,节点无需再次访问快照仓库而是使用本地的数据来响应搜索请求,因此索引的搜索性能并不会降低太多。默认情况下,与可搜索快照关联的索引副本数为0。如果为了提高搜索性能,可以修改索引设置中的index.number_of_replicas参数来增加副本数。
恢复#
当存放与可搜索快照关联的索引的节点故障后,索引将被Elasticsearch重新分配到其他健康节点上。与创建索引时相同,节点可以直接从存储快照的仓库中恢复数据,这便是该类索引不需要副本也能保持高可用的原因。
使用#
通常,可搜索快照的应用场景有以下两种:
- 手动使用Mount snapshot API创建一个新索引,从而让快照中被关联的索引可搜索;
- 对于已存在的索引,配置ILM策略使其进入Cold阶段时,自动执行Searchable Snapshot动作。该动作将为该索引创建一个可搜索快照,并与之相关联。
如果可搜索快照中包含了多个索引,那么在将快照与索引关联前,最好先clone一个只包含需要搜索的索引的快照,然后再进行关联操作。这样做的好处是每个索引都关联了一份独立的快照,方便分别对其进行生命周期管理。否则,只要快照被删除,那么所有与之关联的索引都会失去高可用性。
另外,建议在关联操作前,将索引每个分片都强制合并(force-merge)为一个segment,这样节点同步快照中的数据时会减少许多资源消耗。
作者:koktlzz
出处:https://www.cnblogs.com/koktlzz/p/14521583.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现