Docker核心原理:namespace隔离
Namespace资源隔离#
| namespace | 系统调用参数 | 隔离内容 | 应用意义 |
|---|---|---|---|
| UTS | CLONE_NEWUTS | 主机与域名 | 每个容器在网络中可以被视作一个独立的节点,而非宿主机的一个进程 |
| IPC | CLONE_NEWIPC | 信号量、消息队列和共享内存 | 隔离容器间、容器与宿主机之间的进程间通信 |
| PID | CLONE_NEWPID | 进程编号 | 隔离容器间、容器与宿主机之间的进程PID |
| Network | CLONE_NEWNET | 网络设备、网络栈、端口等 | 避免产生容器间、容器与宿主机之间产生端口已占用的问题 |
| Mount | CLONE_NEWNS | 挂载点(文件系统) | 容器间、容器与宿主机之间的文件系统互不影响 |
| User | CLONE_NEWUSER | 用户和用户组 | 普通用户(组)在容器内部也可以成为超级用户(组),从而进行权限管理 |
进行Namespace API操作的方式#
clone()#
clone()可以在创建新进程(子进程)的同时创建namespace,是Docker使用namespace最基本的方法。
// child_func: 子进程运行的程序主函数
// child_stack: 子进程所使用的堆栈的位置,通常指向为子堆栈设置的内存空间的最高地址
// flags: 使用的CLONE_*标志位
// args: 传入子进程的参数
// 在父进程中返回创建的子进程pid
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg);
相比于调用fork()创建新进程,clone()更加灵活,因为它可以通过改变flags参数来控制其实现的功能,后续将详细介绍各种flags的用法。
setns()#
setns()可以加入一个已经存在的namespace,Docker中的exec命令便调用了该方法:
// fd: 加入的namespace的文件描述符
// nstype: 检查fd指向的namespace类型是否符合实际要求,为0表示不检查
int setns(int fd, int nstype);
参数fd表示要加入的namespace的文件描述符,它指向 /proc/[pid]/ns文件夹下中的软链接文件。而这些软连接文件又指向不同的namespace, 如'cgroup:[4026531835]'中的数字即为其指向的namespace号($$是shell中表示当前运行的进程PID)。
[root@koktlzz proc]# ls -l /proc/$$/ns
总用量 0
lrwxrwxrwx 1 root root 0 1月 29 10:57 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 root root 0 1月 29 10:57 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 root root 0 1月 29 10:57 mnt -> 'mnt:[4026531840]'
lrwxrwxrwx 1 root root 0 1月 29 10:57 net -> 'net:[4026531992]'
lrwxrwxrwx 1 root root 0 1月 29 10:57 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 1月 29 10:57 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 1月 29 10:57 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 1月 29 10:57 uts -> 'uts:[4026531838]'
参数fd是通过打开这些软链接文件得到的,其中参数O_RDONLY代表以只读的方式打开文件。
fd = open(link_file, O_RDONLY);
即使一个namespace下的所有进程全部结束,我们也可以通过指向该namespace的文件描述符fd定位并加入其中,这也是Docker实现加入已存在namespace的最基本方式。
unshare()#
相比于clone(),unshare()不会启动一个新进程,因此可以在原进程中进行一些需要隔离namespace的操作。目前Docker没有调用这个api,其原因在下文中将会介绍。
Namespace隔离的实现方法#
UTS(UNIX Time-sharing System)#
Docker中,每个镜像基本都以自身提供的服务来命名镜像的hostname,其不会对宿主机产生任何影响,其原理就是利用了UTS namespace:
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char child_stack[STACK_SIZE];
char *const child_args[] = {"/bin/bash", NULL};
// 子进程
int child_main(void *args)
{
printf("在子进程中\n");
// sethostname将主机名设置为参数1的值,参数2代表名字的字节数
sethostname("NewNamespace", 12);
// exec可以执行用户命令,常使用"/bin/bash"并接受参数,运行起一个shell
execv(child_args[0], child_args);
return 1;
}
// 父进程
int main()
{
printf("程序开始\n");
// 创建一个子进程及新的UTS namespace
// 若未指定SIGCHLD信号,则在子进程终止时不会通知父进程
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWUTS | SIGCHLD, NULL);
// waitpid阻塞父进程直到子进程结束
waitpid(child_pid, NULL, 0);
printf("已退出\n");
return 0;
}
编译运行后发现我们在进入子进程的同时,主机名也发生了改变,即进入了一个新创建的UTS namespace。当我们在子进程中的终端输入exit后,子进程便调用execv()方法结束进程。于是父进程中的waitpid()方法停止阻塞,父进程也随之退出。
[root@koktlzz home]# ./a.out
程序开始
在子进程中
[root@NewNamespace home]# exit
exit
已退出
[root@koktlzz home]#
IPC(Inter-Process Communication)#
两个不同IPC namespace下的进程互相不可见,因此也就实现了进程间通信的隔离。其实现方法只需要修改clone()方法中的flag:
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWIPC | SIGCHLD, NULL);
我们可以通过IPC资源之一的消息队列来验证IPC namespace的隔离,首先创建并查看在当前namespace下的所有消息队列:
[root@koktlzz home]# ipcmk -Q
消息队列 id:0
[root@koktlzz home]# ipcs -q
--------- 消息队列 -----------
键 msqid 拥有者 权限 已用字节数 消息
0x3ca3eb5d 0 root 644 0 0
然后我们编译运行修改后的程序,再次查看消息队列:
[root@koktlzz home]# ./a.out
程序开始
在子进程中
[root@koktlzz home]# ipcs -q
--------- 消息队列 -----------
键 msqid 拥有者 权限 已用字节数 消息
[root@koktlzz home]# exit
exit
已退出
此时可以发现该IPC namespace下没有刚刚创建的消息队列,因此也就实现了进程间通信的隔离。
PID#
PID namespace的隔离会将进程的pid重新分配,这样两个不同namespace下的进程的pid即使相同也不会崩溃。内核为所有的PID namespace维护了一个进程树,最顶端是系统默认创建的root namespace。每个被创建的新PID namespace成为这个进程树的子节点,而创建者namespace就是它的父节点。父节点可以看到子节点中的进程,并且可以通过信号等方式对子节点中的进程产生影响;反之,子节点却无法看到父节点PID namespace中的任何内容。其实现方法依然只需要修改clone()方法中的flag:
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWPID | SIGCHLD, NULL);
编译运行后即可看到PID namespace隔离的效果:
[root@koktlzz home]# ./a.out
程序开始
在子进程中
[root@koktlzz home]# echo $$
1
[root@koktlzz home]# exit
exit
已退出
[root@koktlzz home]# echo $$
2615550
值得注意的是,即使进入了新的PID namespace,使用ps -ef命令依然可以看到所有父进程的pid。这是因为我们还未实现文件系统挂载点的隔离,而该命令本质调用的是真实系统中的/proc文件内容,看到的自然是所有的进程。
另外,由于程序认为进程的pid是一个常量,因此调用unshare()和setns()方法的进程并不会进入新的PID namespace中。否则该进程就由原PID namespace进入到了新创建的PIDnamespace中,而PID的变化会导致一些程序(如调用getpid()方法)的崩溃。考虑到这一因素,Docker的exec命令不仅调用setns()加入已存在的namespace,但还是会调用clone()方法创建一个新的进程。
Mount#
进程在创建Mount namespace时,会把当前文件结构复制给新的namespace。新namespace中所有的mount操作都只影响自身的文件系统,对外界不会产生任何影响。而挂载传播则定义了挂载对象之间的关系,包括共享关系和从属关系:
- 共享关系:一个挂载对象中的挂载事件会传播到另一个挂载对象,反之亦然;
- 从属关系:一个挂载对象中的挂载事件会传播到另一个挂载对象,反之不行。
其实现方法依然只需要修改clone()方法中的flag,这里加入CLONE_NEWPID参数的目的是方便进行验证:
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWPID | CLONE_NEWNS | SIGCHLD, NULL);
编译并运行程序后,我们发现在重新挂载了/proc文件(mount -t proc proc /proc)后的namespace中使用ps -ef命令后就只能看到子进程的pid了,并且没有影响到父进程中的/proc文件挂载。
[root@koktlzz home]# ./a.out
程序开始
在子进程中
[root@koktlzz home]# mount -t proc proc /proc
[root@koktlzz home]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 12:39 pts/1 00:00:00 /bin/bash
root 17 1 0 12:40 pts/1 00:00:00 ps -ef
[root@koktlzz home]# exit
exit
已退出
Network#
Network namespace提供了网络资源的隔离,包括网络设备、IPv4和IPv6协议栈、IP路由表、防火墙、socket等。
修改clone()方法中的flag参数:
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWNET | SIGCHLD, NULL);
编译运行程序后我们发现:在新创建的Network namespace中,无法通过DNS解析域名,甚至连网卡eth0都没有了。这说明网络资源已经完全隔离。
[root@koktlzz home]# gcc hello.c && ./a.out
程序开始
在子进程中
[root@koktlzz home]# ping www.baidu.com
ping: www.baidu.com: 未知的名称或服务
[root@koktlzz home]# ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@koktlzz home]# exit
exit
已退出
[root@koktlzz home]# ping www.baidu.com
PING www.a.shifen.com (180.101.49.12) 56(84) bytes of data.
64 bytes from 180.101.49.12 (180.101.49.12): icmp_seq=1 ttl=49 time=9.96 ms
64 bytes from 180.101.49.12 (180.101.49.12): icmp_seq=2 ttl=49 time=9.93 ms
Docker采用CNM(Container Network Model)实现network namespace隔离,CNM主要由三个部分构成:
- 沙盒(sanbox):network namespace
- 端点(endpoint):veth-pair
- 网络(network):linux bridge或vlan
对于Docker来说,linux bridge便是docker0。veth相当于网桥上的端口,它工作在链路层不需要配置IP。而docker0自身的IP默认为172.17.0.1/16,即容器的默认网关地址。所有容器都会在docker0的子网范围内选取一个未占用的ip使用,并通过veth-pair连接到docker0。
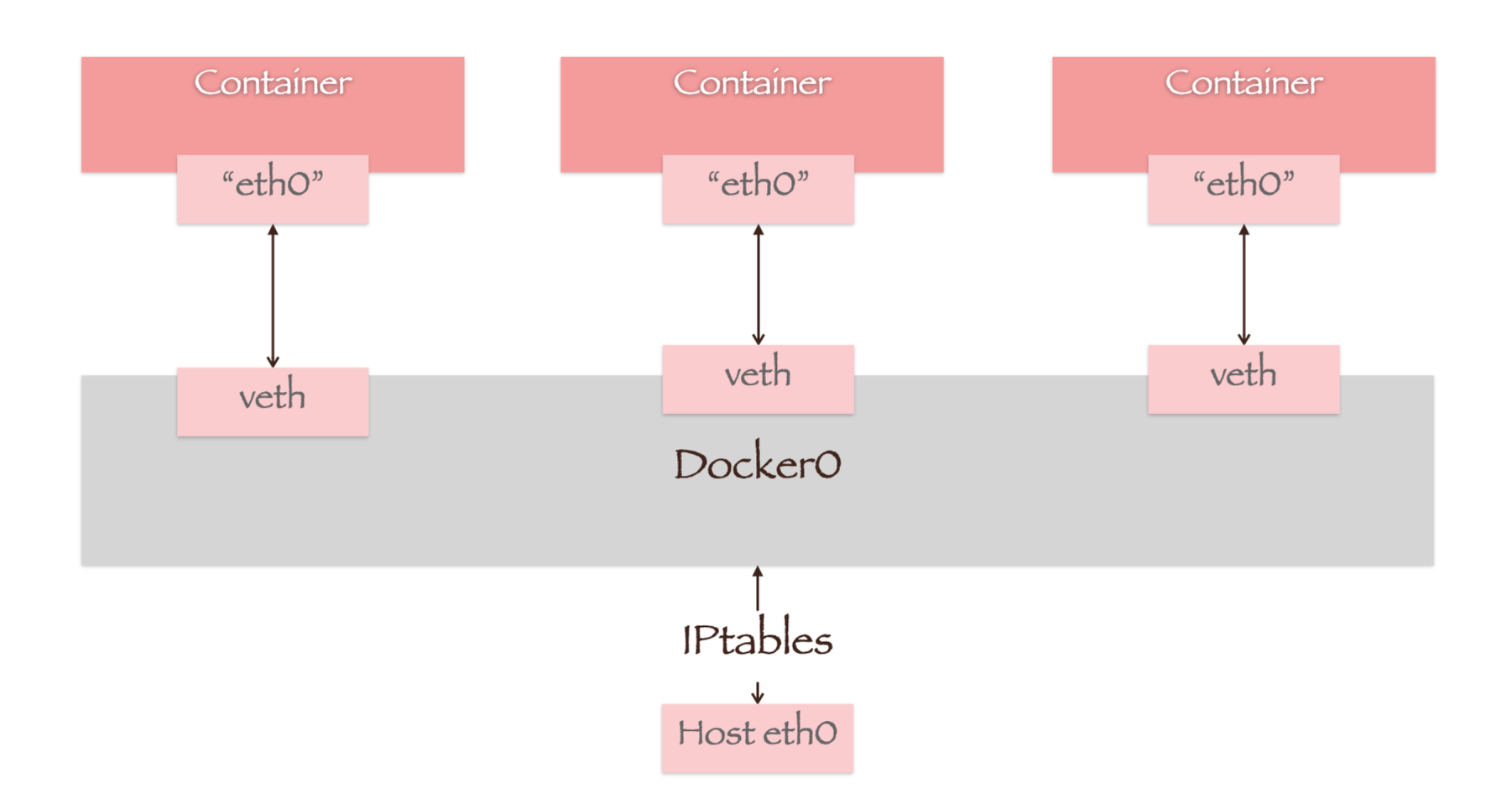
Docker daemon创建容器网络的过程如下:
- 首先由Docker daemon负责创建一个虚拟网络对veth-pair。一端绑定到docker0网桥上,另一端接入容器中。
- 容器内部的初始化进程(即init进程)在管道一端循环等待,直到Docker daemon从管道另一端向其传输关于veth-pair设备的信息,随后关闭管道。
- 最后,init进程结束等待,启动它的虚拟网卡"eth0"。
User#
一个普通用户的进程通过clone()方法创建的子进程可以在这个新的User namespace中拥有不同的用户和用户组,这意味着容器内部的root用户可能在宿主机上只是一个普通用户,从而为容器提高了极大的自由。User namespace与PID namespace类似,同样是一个层层嵌套的树状结构。
其实现方法依然是在flag参数中加入CLONE_NEWUSER创建一个新的User namespace():
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWUSER | SIGCHLD, NULL);
编译运行后我们可以发现,在创建的新User namespace中,user和group变成了nobody,uid和gid也随之改变。
[root@koktlzz home]# ./a.out
程序开始
在子进程中
[nobody@koktlzz home]$ id
uid=65534(nobody) gid=65534(nobody) 组=65534(nobody)
[nobody@koktlzz home]$ exit
exit
已退出
[root@koktlzz home]# id
uid=0(root) gid=0(root) 组=0(root)
除此之外,我们还要把子节点namespace中的初始user与其父节点namespace中的某个用户建立映射关系。这样子节点User namespace想要给父节点User namespace发送一个信号或操作某一个文件时,系统就会判断子节点中的用户在父节点中是否有对应的权限。这是通过在/proc/[pid]/uid_map和/proc/[pid]/gid_map文件中写入对应的映射信息实现的,以uid_map为例:
void set_uid_map(pid_t pid, int inside_id, int outside_id, int length)
{
char path[256];
sprintf(path, "/proc/%d/uid_map", getpid());
FILE *uid_map = fopen(path, "w");
// inside_id表示新建的User namespace中对应的uid/gid
// outside_id表示namespace外部映射的uid/gid
// length表示映射范围,通常为1,表示只映射一个
fprintf(uid_map, "%d %d %d", inside_id, outside_id, length);
fclose(uid_map);
}
作者:koktlzz
出处:https://www.cnblogs.com/koktlzz/p/14352476.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现