使用Pandas和NumPy实现数据获取
以某城市地铁数据为例,通过提取每个站三个月15分钟粒度的上下客量数据,展示Pandas和Numpy的案例应用。
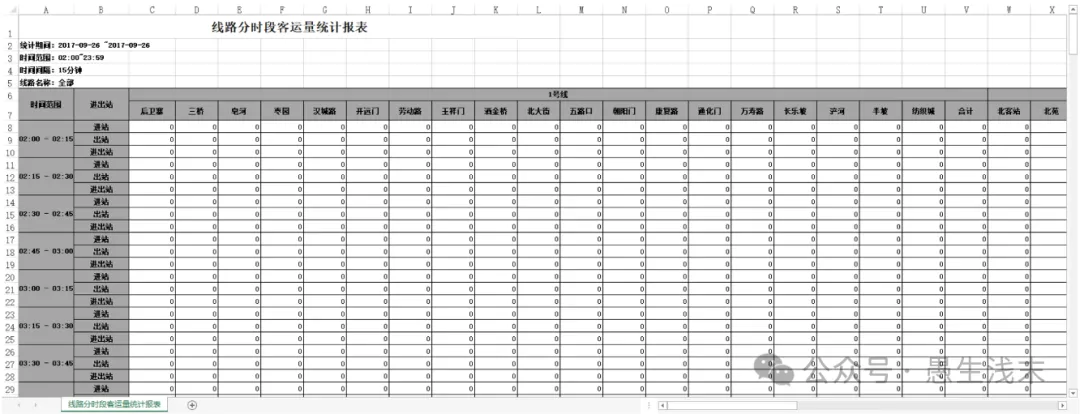
初步发现数据有三个特点::1、地铁数据的前五行是无效的,第七行给出了每个站点的名字;2、每个车站是按照15分钟粒度统计客流,给出了进站、出战、进出站客流;3、运营时间是从2:00-23:59,与地铁实际运营时间5:30-23:00不同,需要调整。
# 导入模块
import os
from pathlib import Path
import pandas as pd
import numpy as np
导入成功后,先获取目标文件夹下(data)的文件名,存入filenames变量中。
# 获取文件名
path = "./data"
filenames = os.listdir(path)
filenames
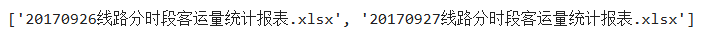
获取每个车站所对应的列号,确定pdd.read_excel(usecols)中usecols的参数
# 筛选掉 “合计”无用项,并设置target_col存储目标项
name = filenames[0]
f = "./data/" + name
# 前五行是无用数据
file = pd.read_excel(f, skiprows = 5, skipfooter = 3)
tarr = file.values
print(tarr[3])
test = tarr[0]
target_col = []
for i in range(len(test)):
tmp = test[i]
if tmp != '合计':
target_col.append(i)
print(target_col)

获取车站名和车站编号:
# 获取车站名和车站编号
nfile = pd.read_excel(f, skiprows = 5, skipfooter = 3, usecols = target_col)
arrt = nfile.values
stations_name = []
stations_index = []
for i in range(2,len(arrt[0])):
stations_index.append(i)
stations_name.append(arrt[0][i])
print(stations_name)
print(stations_index)

接下来定义两个函数,我们希望把所有的数据都写入两个文件夹,一个是”in.csv”存储每个站的进站数据,一个是”out.csv”存储每个站的出站数据。如果目标文件不存在,代码如下:
def process_not_exists(f):
# 前五行是无用数据
file = pd.read_excel(f, skiprows = 5, skipfooter = 3, usecols = target_col)
arr = file.values
# 构造一个字典先存储数据
d_in = {}
d_out = {}
for i in stations_index:
# 存储第i个车站的上下客流数据
d_in[i] = []
d_out[i] = []
# 5:30 之后的数据是从excel的50行开始,处理后的数据应从43行开始
for i in range(43,len(arr)):
l = arr[i] # 获取第i行的数据
# 通过条件直接筛选掉“进出站”
if l[1] == '进站':
# 进站处理
for j in range(2,len(l)):
d_in[j].append(l[j])
if l[1] == '出站':
# 出站处理
for j in range(2,len(l)):
d_out[j].append(l[j])
in_list = [] # 存储进站数据
out_list = [] # 存储出站数据
for key in d_in:
# d_in 与 d_out 的key均为车站的index
in_list.append(d_in[key])
out_list.append(d_out[key])
df_in = pd.DataFrame(in_list)
df_in.to_csv("./data/in.csv", header = True, index = None)
df_out = pd.DataFrame(out_list)
df_out.to_csv("./data/out.csv", header = True, index = None)
如果目标文件存在,读取部分与目标文件不存在时相同,在处理输出时要进行修改,代码如下:
# 目标文件存在时
def process_exists(f,target_file_in,target_file_out):
infile = pd.read_csv(target_file_in)
outfile = pd.read_csv(target_file_out)
in_arr = infile.values.tolist()
out_arr = outfile.values.tolist()
# 前五行是无用数据
file = pd.read_excel(f, skiprows = 5, skipfooter = 3, usecols = target_col)
arr = file.values
# 构造一个字典先存储数据
d_in = {}
d_out = {}
for i in stations_index:
# 存储第i个车站的上下客流数据
d_in[i] = []
d_out[i] = []
# 5:30 之后的数据是从excel的50行开始,处理后的数据应从43行开始
for i in range(43,len(arr)):
l = arr[i] # 获取第i行的数据
# 通过条件直接筛选掉“进出站”
if l[1] == '进站':
# 进站处理
for j in range(2,len(l)):
d_in[j].append(l[j])
if l[1] == '出站':
# 出站处理
for j in range(2,len(l)):
d_out[j].append(l[j])
in_list = [] # 存储进站数据
out_list = [] # 存储出站数据
for key in d_in:
# d_in 与 d_out 的key均为车站的index
in_list.append(d_in[key])
out_list.append(d_out[key])
#合并原有数据
for i in range(len(in_arr)):
in_arr[i] += in_list[i]
out_arr[i] += out_list[i]
# in_file
df_in = pd.DataFrame(in_arr)
df_in.to_csv("./data/in_test.csv",mode = 'r+', header = True, index = None)
# out_file
df_out = pd.DataFrame(out_arr)
df_out.to_csv("./data/out_test.csv",mode = 'r+', header = True, index = None)
对于DataFrame中的数据获取方法有两种:第一种为通过file.iloc[i,j]的方式定位第i行第j列的数据;第二种为通过file.values将file转换为ndarray的数据格式,由于可以事先知道数据每一列的具体含义,直接通过整数下标的方式访问数据。
代码中使用的是第二种方式,这是由于DataFrame的iloc[]函数访问效率低,当数据体量很大时,遍历整个表格的速度会非常慢,而将DataFrame转换为ndarray后,遍历整个表格的数据效率会有显著提升。
下面是主函数,即可完成所有数据的提取。
for name in filenames:
f = "./data/" + name
target_file_in = "./data/in_test.csv"
target_file_out = "./data/out_test.csv"
# 若文件已存在
if Path(target_file_in).exists() and Path(target_file_out).exists():
print("exist")
process_exists(f,target_file_in,target_file_out)
#break
else:
print("not exist")
process_not_exists(f)
print("done")


 浙公网安备 33010602011771号
浙公网安备 33010602011771号