第八节 模型评估
二分类模型评估,多分类转换成二分类
# 最常用的是准确率,即预测结果正确的百分比
# 混淆矩阵:在分类任务下,预测结果与正确标记之间存在四种不同的组合,构成混淆矩阵(适用于多分类),真正例TP,伪正例FP,伪反例FN,真反例TN
# 混淆矩阵中的召回率:真实为正例的样本中预测结果为正例的比例(查的全,对正样本的区分能力,宁杀错不放过的思想)=TP/(TP+FN)
# 混淆矩阵中的精确率:预测结果为正例样本中真实为正例的比例TP/(TP+FP),一般不考虑
# F1-score:反映模型的稳健性F1=2TP/(2TP+FN+FP)
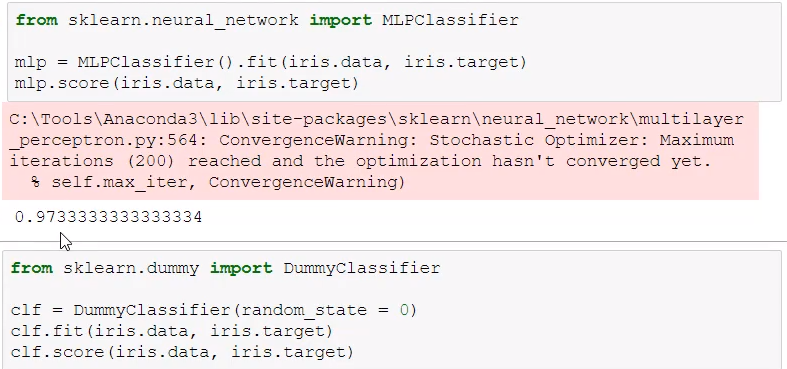
from sklearn.metrics import classification_report # 分类模型评估API
# y_true真实目标值,y_pred估计器预测目标值,target_names目标类别名称,返回每个类别精确率和召回率
cr = classification_report(y_true="", y_pred='', target_names='')
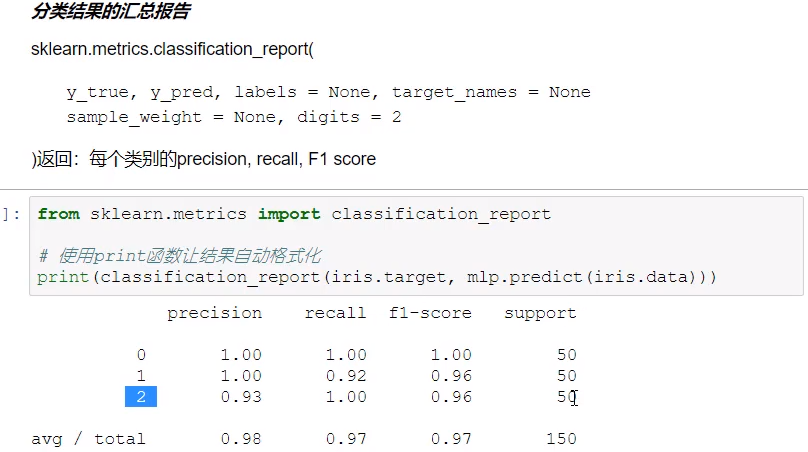
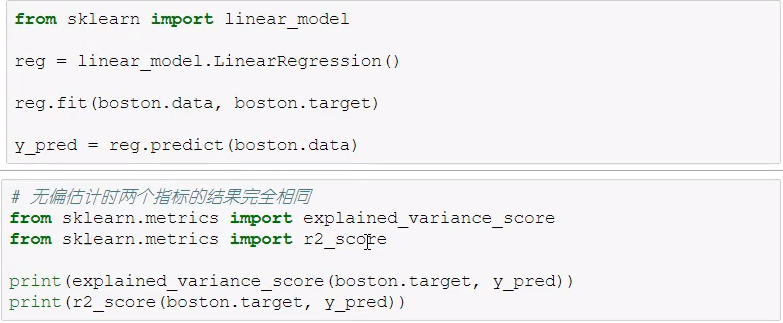
回归类模型的评估

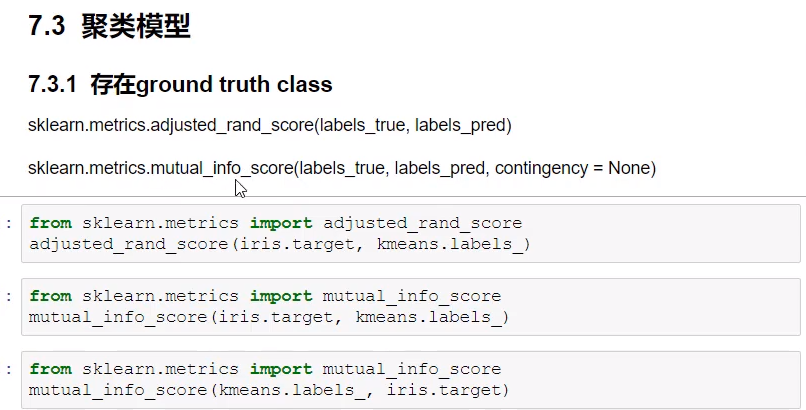
聚类模型评价



当模型评分很低或者决定系数很小的时候,需要对模型是否存在价值进行评估,让其与随机预测结果进行比较,当模型评分大于随机评分的1.25倍时认为模型是有价值的,最有价值的参数在于constant的设置