TensorRT int8 量化部署 yolov5s 5.0 模型
TensorRT int8 量化部署 yolov5s 5.0 模型
一.yolov5简介
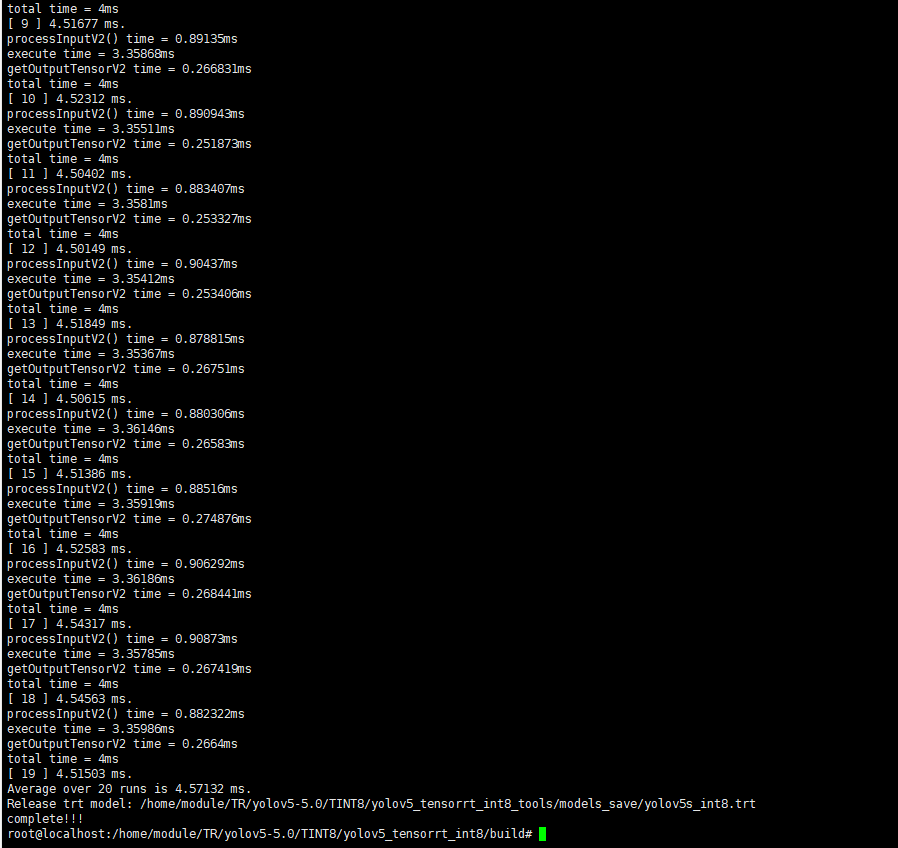
如果说在目标检测领域落地最广的算法,yolo系列当之无愧,从yolov1到现在的"yolov5",虽然yolov5这个名字饱受争议,但是阻止不了算法部署工程师对他的喜爱,因为他确实又快又好,从kaggle全球小麦检测竞赛霸榜,到star数短短不到一年突破8k,无疑,用硬实力证明了自己。总而言之,用他,用他,用他!(在我的3080显卡上测试640*640的图片,yolov5s 5.0 的模型 tensorrt int8 量化后,inference做到了4.6ms一帧!)
二.环境
ubuntu:18.04
cuda:11.1
cudnn:8.0
tensorrt:7.2.2.3
OpenCV:4.5.0
做INT8模型转换之前,我建议你至少要有搭建Tensorrt的经验,如yolov5的yolov5s.pt转yolov5s.engine模型,并且且测试通过的。
此处对环境的安装就省略了,如果不知道怎么搭建环境,可以参考我之前的记录:https://www.cnblogs.com/KdeS/p/14928201.html
如有疑问,邮箱联系
三.yolov5s模型转换onnx
3.1安装需要用到的库
pip install onnx
pip install onnx-simplifier
3.2 转换onnx
git clone https://github.com/ultralytics/yolov5.git
cd yolov5/models
vim common.py
把BottleneckCSP类下的激活函数替换为relu,tensorrt对leakyRelu int8量化不稳定(这是一个深坑,大家记得避开)即修改为self.act = nn.ReLU(inplace=True)
训练得到模型后
cd yolov5
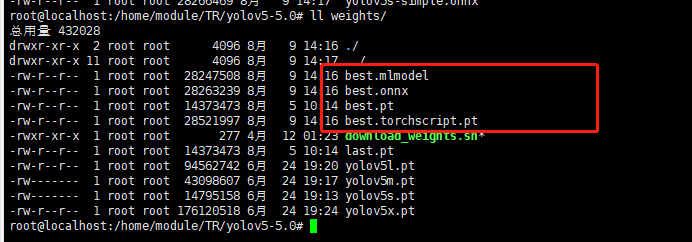
python models/export.py --weights 训练得到的模型权重路径 --img-size 训练图片输入尺寸
就会产生如下几个文件
python3 -m onnxsim onnx模型名称 yolov5s-simple.onnx 得到最终简化后的onnx模型

如果你的Tensorrt中有models/export.py ,那么上面的项目就不用出伏拉取了,可以直接用export.py 转onnx模型,操作步骤不变
四.onnx模型转换为 int8 tensorrt引擎
git clone https://github.com/Wulingtian/yolov5_tensorrt_int8_tools.git(求star)
cd yolov5_tensorrt_int8_tools
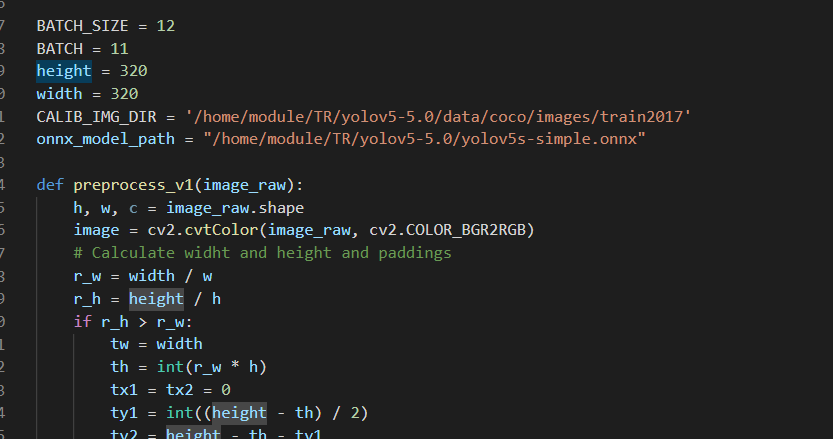
vim convert_trt_quant.py 修改如下参数
BATCH_SIZE 模型量化一次输入多少张图片
BATCH 模型量化次数
height width 输入图片宽和高
CALIB_IMG_DIR 训练图片路径,用于量化
onnx_model_path onnx模型路径
python3 convert_trt_quant.py 量化后的模型存到models_save目录下
成功后会产生两个文件:
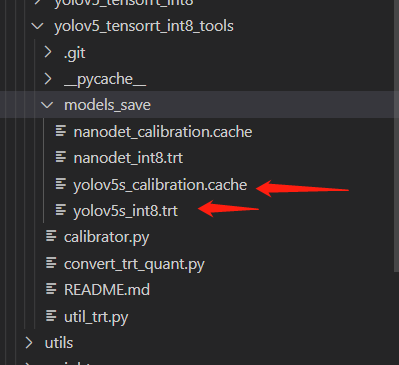
注意:
此处有两点注意事项
1.BATCH_SIZE*BATCH要小于或等于训练图片数量,否则会报错
2.测试前models_save目录不能有其他文件,如果models_save目录没有则需要自己创建,否则会报错
五.tensorrt模型推理
git clone https://github.com/Wulingtian/yolov5_tensorrt_int8.git(求star)
cd yolov5_tensorrt_int8
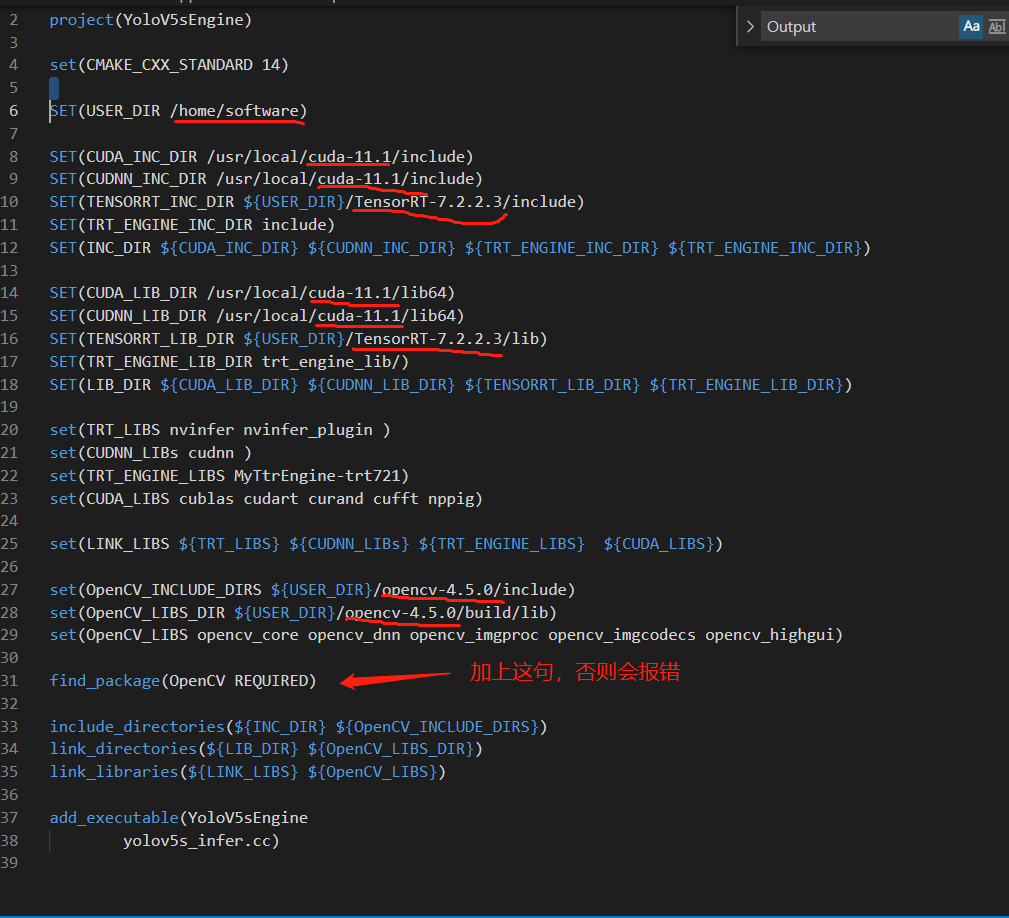
5.1 修改 vim CMakeLists.txt
修改USER_DIR参数为自己的用户根目录,图中划线的位置都需要根据自己的环境做修改
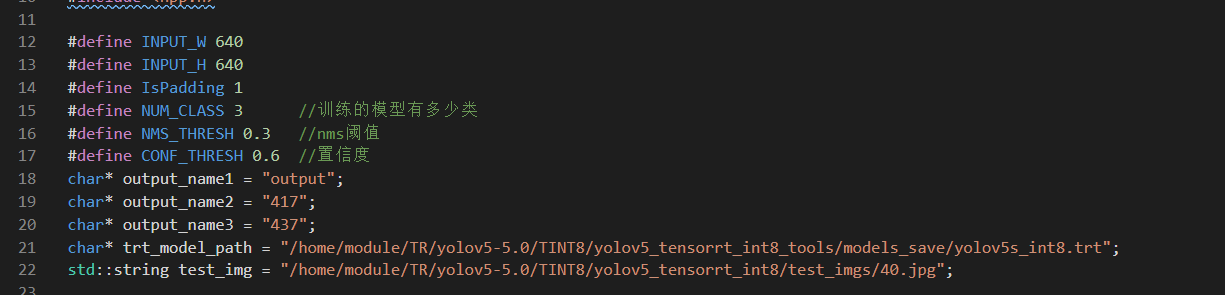
5.2修改 vim http://yolov5s_infer.cc 修改如下参数
output_name1 output_name2 output_name3 yolov5模型有3个输出(这里目录可按照下图填上去,不能随便填)
trt_model_path 量化的的tensorrt推理引擎(models_save目录下trt后缀的文件)
test_img 测试图片路径
INPUT_W INPUT_H 输入图片宽高
NUM_CLASS 训练的模型有多少类
NMS_THRESH nms阈值
CONF_THRESH 置信度
5.3 安装netron
我们可以通过netron查看模型输出名
pip install netron 安装netron
vim netron_yolov5s.py 把如下内容粘贴
import netron
netron.start('此处填充简化后的onnx模型路径', port=3344)

python3 netron_yolov5s.py 即可查看 模型输出名
参数配置完毕 !
5.4 编译
mkdir build
cd build
cmake ..
make
./RepVGGsEngine 输出平均推理时间,实测平均推理时间小于1ms一帧,不得不说,RepVGG真的很香!至此,部署完成!由于我训练的是猫狗识别下面放一张猫狗同框的图片结尾。
参考文献:
https://zhuanlan.zhihu.com/p/348110519
https://my.oschina.net/u/4580321/blog/4951406

 浙公网安备 33010602011771号
浙公网安备 33010602011771号