MongoDB初级篇
目录 一、什么是MongoDB 二、什么是NoSQL 三、mongodb的使用场景 四.windows下安装mongoDB(zip版) 3.1 下载mongoDB的zip包 3.2 解压名称改为mongodb 3.3 解压后的来个两种启动方式: 1.1 命令参数方式启动服务(开发调试使用) 2 .1 配置文件的方式启动服务(一般部署使用 ) 3.4 配置环境变量 五.连接mongoDB 六.MongoDB 创建/查看数据库 七.MongoDB 删除数据库 八.MongoDB集合操作(类似于关系型数据库中的表) 九.文档的CRUD 9.1 单个文档插入 9.2 批量文档插入 9.3 文档的基本查询 9.4 投影查询 9.5 文档的更新操作 9.5.1 覆盖修改 9.5.2 局部修改 9.5.3 批量修改 9.6 删除文档 9.7 统计查询 9.8 文档的分页查询 9.9 排序查询 十 .复杂查询 10.1 正则表达式查询(模糊查询) 10.2 比较查询 10.3 包含查询 10.4 条件连接查询
一、什么是MongoDB
-
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统,,文件型数据库。
-
在高负载的情况下,添加更多的节点,可以保证服务器性能。
-
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
-
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
-
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
-
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
二、什么是NoSQL
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL 数据库的发展却能很好的处理这些大的数据。
NoSQL的优点/缺点优点:
-
高可扩展性
-
分布式计算
-
低成本
-
架构的灵活性,半结构化数据
-
没有复杂的关系缺点:
-
没有标准化
-
有限的查询功能(到目前为止)
-
最终一致是不直观的程序
三、mongodb的使用场景
高可用
高扩展性
高并发
丰富的查询支持
无模式,数据结构松散灵活
使用场景1
用在应用服务器的日志记录,查找起来比文本灵活,导出也很方便。也是给应用练手,从外围系统开始使用MongoDB。
用在一些第三方信息的获取或者抓取,因为MongoDB的schema-less,所有格式灵活,不用为了各种格式不一样的信息专门设计统一的格式,极大得减少开发的工作。
使用场景2
mongodb之前有用过,主要用来存储一些监控数据,No schema 对开发人员来说,真的很方便,增加字段不用改表结构,而且学习成本极低。
使用场景3
使用MongoDB做了O2O快递应用,·将送快递骑手、快递商家的信息(包含位置信息)存储在 MongoDB,然后通过 MongoDB 的地理位置查询,这样很方便的实现了查找附近的商家、骑手等功能,使得快递骑手能就近接单,目前在使用MongoDB 上没遇到啥大的问题,官网的文档比较详细,很给力。
经常跟一些同学讨论 MongoDB 业务场景时,会听到类似『你这个场景 mysql 也能解决,没必要一定用 MongoDB』的声音,的确,并没有某个业务场景必须要使用 MongoDB才能解决,但使用 MongoDB 通常能让你以更低的成本解决问题(包括学习、开发、运维等成本),下面是 MongoDB 的主要特性,大家可以对照自己的业务需求看看,匹配的越多,用 MongoDB 就越合适。
这些应用场景中,数据操作方面的共同点是:
1.数据量大
2.读写操作频繁
3.价值较低的数据,对事物要求性不高
四.windows下安装mongoDB(zip版)
下面说明如何在win10下用zip包安装好mongoDB数据库 ,
3.1 首先要先从网上下载mongoDB的zip包 http://dl.mongodb.org/dl/win32/x86_64 或https://www.mongodb.com/download-center/community
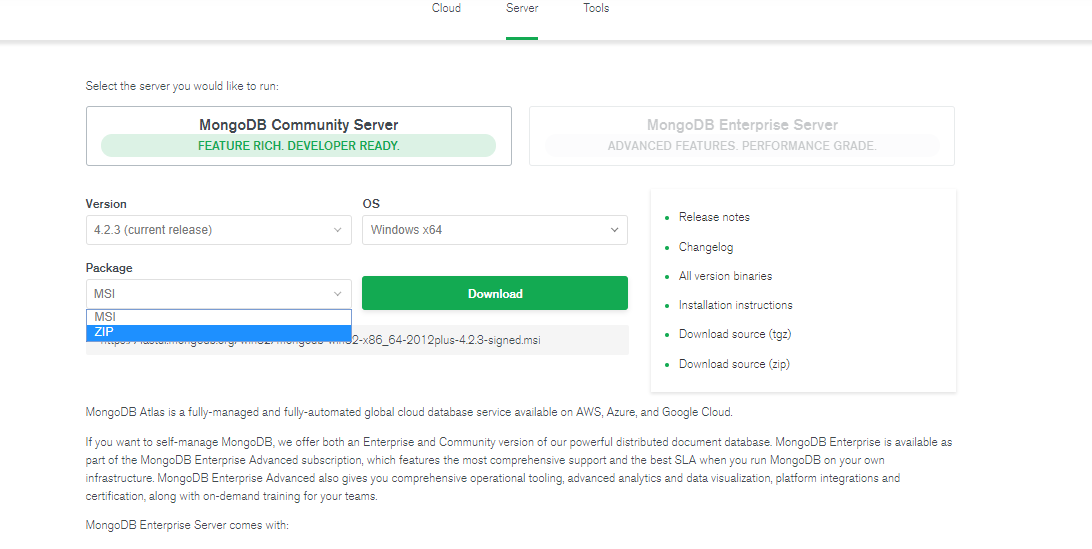
根据是上图所提示下载zip包:
提示:版本的选择
-
MongoDB的版本命名规范如:x.y.z
y为奇数时表示当前版本为开发版,如:1.5.2, 4.1.13;
y为偶数时表示当前版本为稳定版,如:1.6.3, 4.0.10;
z是修正版本号,数字越大越好。
3.2.把刚才下载的zip包解压到 D:\Software\,把名称改为mongodb
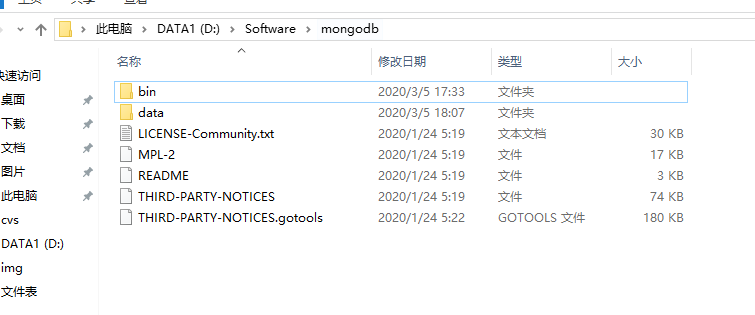
3.3解压后的两种启动方式:
1.1 命令参数方式启动服务(开发调试使用)
在bin目录的同级创建data目录,在data目录中在创建子文件夹db目录作为数据库文件的存放位置

启动mongodb
进入到bin目录下打开cmd命令开启服务。 输入mongod --dbpath=..\data\db 回车 这里设置的是数据存放的位置,即刚才所建立的文件夹
mongod --dbpath=..\data\db

默认端口:27017
如图所示表示启动成功

2 .1 配置文件的方式启动服务(一般部署使用 )
-
在bin目录的同级创建conf文件夹存放mongodb的配置文件,在conf目录中在创建mongod.conf文件存放配置文件内容
systemLog:
destination: file
path: D:\Software\mongodb\data\log\mongod.log #日志存放位置
storage:
dbPath: D:\Software\mongodb\data\db #数据库存放位置
windows环境配置是采用的YAML格式 :
# mongod.conf
# for documentation of all options, see:
# http://docs.mongodb.org/manual/reference/configuration-options/
# Where and how to store data.
storage:
dbPath: D:\Program Files\MongoDB\Server\3.7\data
journal:
enabled: true
# engine:
# mmapv1:
# wiredTiger:
# where to write logging data.
systemLog:
destination: file
logAppend: true
path: D:\Program Files\MongoDB\Server\3.7\log\mongod.log
# network interfaces
net:
port: 27017
bindIp: 0.0.0.0
#processManagement:
#security:
#operationProfiling:
#replication:
#sharding:
## Enterprise-Only Options:
#auditLog:
#snmp:
linux环境一般配置内容有如下properties格式:
#数据库数据存放目录
dbpath=/usr/local/mongodb304/data
#数据库日志存放目录
logpath=/usr/local/mongodb304/logs/mongodb.log
#以追加的方式记录日志
logappend = true
#端口号 默认为27017
port=27017
#以后台方式运行进程
fork=true
#开启用户认证
auth=true
#关闭http接口,默认关闭http端口访问
nohttpinterface=true
#mongodb所绑定的ip地址,局域网ip地址
bind_ip = 127.0.0.1
#启用日志文件,默认启用
journal=true
#这个选项可以过滤掉一些无用的日志信息,若需要调试使用请设置为false
quiet=true
启动mongodb
mongod -f ../conf/mongod.conf 或者 mongod -config ../conf/mongod.conf #配置文件路径

3.4 接着设置环境变量(虽然理论上可以不设,但是为了方便,还是设置了吧) D:\Software\mongodb\bin 将该路径添加到环境变量path里
接着在cmd里输入以下语句: mongod -help 如果输出一大堆的帮助文档信息,证明设置成功

五.连接mongoDB
4.1 shell连接(mongo命令)
mongo(本机) 或者 mongo --host=127.0.0.1 --port=27017

4.2 Compass-图形化界面客服端
到MongoDB官网下载MongoDB Compass
地址:https://www.mongodb.com/download-center/compass
如果是下载安装板,则按照步骤安装;如果是下载压缩版,直接解压,执行里面的MongoDBCompassCommunity.exe
或者 MongoDBCompass.exe文件即可。
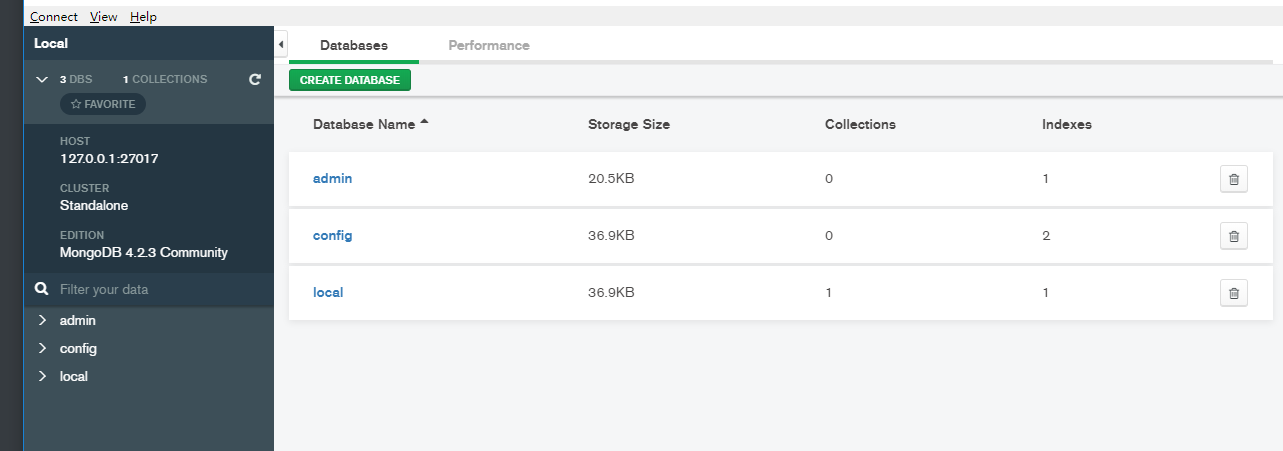
在打开的界面中输入主机地址,端口等相关信息,点击连接
六.MongoDB 创建/查看数据库
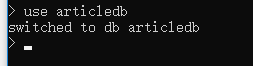
5.1 创建数据库的语法格式如下:
use 数据库名称;
如果数据库不存在,则创建数据库,否则切换到指定数据库。
列:
此外:
数据库名可以是满足以下条件的任UTF8字符串·
-
不能是空字符串("")。
-
不得含有' '(空格),.$、/,\和\0(空字符)。
-
应全部小写
-
最多64字节
有一些数据据库名是保留的,可以接访问这些有特殊作用的数据库。
-
admin:从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭团服务
-
loca:这个数据永远不会被复制,可以用来存储限于本地单台级务器的任意集合
-
config:当 Mongol用于分片设置时, config数据库在内部使用,用于保存分片的相关信息
5.2 如果你想查看所有数据库,可以使用 show dbs 或者 show databases 命令:
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
> show databases
admin 0.000GB
config 0.000GB
local 0.000GB
>
这里查看时目前查看不到ariticledb的原因是因为mongodb的存贮机制是分为两块,一块是内存,另一块是磁盘,当数据库中没有集合时,数据库是存放在内存中,有集合之后就会存入磁盘中存入磁盘之后通过show dbs 就可以查看到ariticledb数据库。
5.3查看当前正在使用的数据库,命令:db
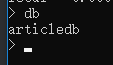
mongodb的默认数据库为test,如果你没有选择数据库,集合将存放与test数据库中。
七.MongoDB 删除数据库
MongoDB 删除数据库的语法格式如下:
db.dropDatabase();

删除当前数据库,默认为 test,你可以使用 db 命令查看当前数据库名。
提示:主要用来删除已经持久化的数据库
八.MongoDB集合操作(类似于关系型数据库中的表)
集合操作类似于关系型数据库中的表操作,可以显式的创建,也可以隐式的创建
提示:通常我们使用隐式创建文档即可。
8.1 集合的隐式创建
隐式创建的含义:当向一个集合插入一个文档的时候,如果集合不存在,则会自动创建集合。
8.2 集合的显式创建
语法格式:db.createCollection(集合名称)
db.createCollection(name)
参数说明:
-
name: 要创建的集合名称

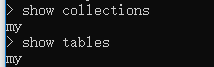
8.3 查询集合
show collections 或 show tables
8.4 集合的删除
语法格式:
db.collection.drop() 或者 db.集合.drop()

如果成功删除选定集合,则 drop() 方法返回 true,否则返回 false。
九.文档的CRUD
-
本节中将向大家介绍如何将数据插入到 MongoDB 的集合中。
-
文档的数据结构和 JSON 基本一样。
-
所有存储在集合中的数据都是 BSON 格式。
-
BSON 是一种类似 JSON 的二进制形式的存储格式,是 Binary JSON 的简称。
9.1 单个文档插入
使用 insert() 或 save() 方法向集合中插入文档,语法如下:
db.COLLECTION_NAME.insert(document) 或者 db.COLLECTION_NAME.save(document) //COLLECTION_NAME:集合名称 //document 文档
db.COLLECTION_NAME.insert(document) 和 db.COLLECTION_NAME.save(document) 的区别。如果不指定 _id 字段 save() 方法类似于 insert() 方法。如果指定 _id 字段,则会更新该 _id 的数据。
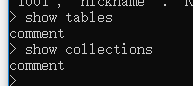
//列 db.comment.insert({ "articleid": "10000", "content": "今天天气真好,阳光明媚", "userid": "1001", "nickname": "Rose", "createdatetime":new Date(), "likenum": NumberInt(10), "state":null })
以上实例中 comment是我们的集合名,如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档。
在这里本来是没有comment这个集合的,但在插入文档的同时他就创建了comment集合,这就是隐式创建
9.2 批量文档插入
语法格式如下:
-
db.collection.insertOne():向指定集合中插入一条文档数据
-
db.collection.insertMany():向指定集合中插入多条文档数据
//指定id db.comment.insertOne({ "_id":"4", "articleid": "10000", "content": "不见当时翠辇女,今朝陌上又花开。", "userid": "1001", "nickname": "路飞", "createdatetime":new Date(), "likenum": NumberInt(10), "state":null })
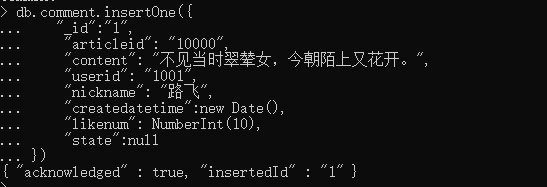
//列 db.comment.insertMany([{ "articleid": "10000", "content": "今天天气真好,阳光明媚", "userid": "1001", "nickname": "Rose", "createdatetime":new Date(), "likenum": NumberInt(10), "state":null }, { "articleid": "10000", "content": "陌上花开,可缓缓归矣。", "userid": "1001", "nickname": "宝儿", "createdatetime":new Date(), "likenum": NumberInt(10), "state":null }, { "articleid": "10000", "content": "陌上花开蝴蝶飞,江山犹似昔人非。", "userid": "1001", "nickname": "百里登风", "createdatetime":new Date(), "likenum": NumberInt(10), "state":null } ])

提示:
插入是指定了_id,则主键就是该值。
如果某条数据插入失败,将会终止插入,但是已经成功的数据不会回滚掉。
因为批量查插入由于数据较多容易出现失败,因此,可以使用try catch进行异常捕捉处理,测试的时候可以不处理,如(了解):
try{ db.comment.insertMany([{ "_id":"2", "articleid": "10000", "content": "今天天气真好,阳光明媚", "userid": "1001", "nickname": "Rose", "createdatetime":new Date(), "likenum": NumberInt(10), "state":null }, { "_id":"1", "articleid": "10000", "content": "陌上花开,可缓缓归矣。", "userid": "1001", "nickname": "宝儿", "createdatetime":new Date(), "likenum": NumberInt(10), "state":null }, { "_id":"3", "articleid": "10000", "content": "陌上花开蝴蝶飞,江山犹似昔人非。", "userid": "1001", "nickname": "百里登风", "createdatetime":new Date(), "likenum": NumberInt(10), "state":null } ]); }catch(e){ print(e); }
异常捕捉现象如:

这里的第一条数据插入会成功,第二条之后就会插入失败,因为第二条的数据id是1,而集合中已经有了id为1的文档,所以会导致后面的操作都会失败。
9.3 文档的基本查询
-
批量查询语法如下:
db.comment.find() //comment 集合名称

条件查询语法如下:
db.comment.find(
{
属性名称:属性值
}
)
db.comment.findOne(
{
属性名称:属性值
}
)
列1:如果我想按一定的条件来查询,比如我想查询nickname为路飞的记录,怎么办?答案是很简单!只要在find()中添加参数即可,参数也是json格式如下
db.comment.find({nickname:"路飞"})

列2:如果我只需要返回符合条件的第一条数据,我们可以使用findOne()命令来实现,语法和find一样。同样查询nickname为路飞的记录,但只返回符合条件的第一条记录,语法如下:
db.comment.findOne({nickname:"路飞"})
列3:如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
db.comment.find().pretty()

9.4 投影查询
如果要查询结果返回部分字段,则需要使用投影查询(不显示所有的字段,只显示指定的字段)
列1:查询结果只显示_id,userid,nickname ,语法如下:
db.comment.find({nickname:"路飞"},{userid:1,nickname:1})

默认_id会显示
列2:查询结果只显示userid,nickname,不显示_id,语法如下:
db.comment.find({nickname:"路飞"},{userid:1,nickname:1,_id:0})

列3:查询所有数据,但结果只显示 userid,nickname,不显示_id,语法如下:
db.comment.find({},{userid:1,nickname:1,_id:0})
9.5 文档的更新操作
MongoDB 使用 update() 和 save() 方法来更新集合中的文档。接下来让我们详细来看下两个函数的应用及其区别。
update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update( <query>, <update>, { upsert: <boolean>, multi: <boolean>, writeConcern: <document> } ) //或者 db.collection.update(query,update,options)
参数说明:
-
query : update的查询条件,类似sql update查询内where后面的。
-
update : update的对象和一些更新的操作符(如inc...)等,也可以理解为sql update查询内set后面的
-
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
-
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
-
writeConcern :可选,抛出异常的级别。
9.5.1 覆盖修改
如果我们想修改_id为1的记录,点赞量为100,输入以下语句:
db.comment.update({_id:"1"},{likenum:NumberInt(100)})

再次查看: db.comment.find({_id:"1"})

执行后,我们会发现,这条文档除了likenum字段其他字段都不见了,
9.5.2 局部修改
为了解决以上的覆盖修改问题,我们需要使用修改器$set来实现,命令如下:
我们想修改_id为2的记录,点赞量为999,输入以下语句:
db.comment.update({_id:"2"},{$set:{likenum:NumberInt(999)}})

再次查看: db.comment.find({_id:"2"})

这样就ok啦
9.5.3 批量修改
(1)更新所有用户为1001的用户昵称为亚历山大大
//默认只修改第一条数据 db.comment.update({userid:"1001"},{$set:{nickname:"亚历山大"}})
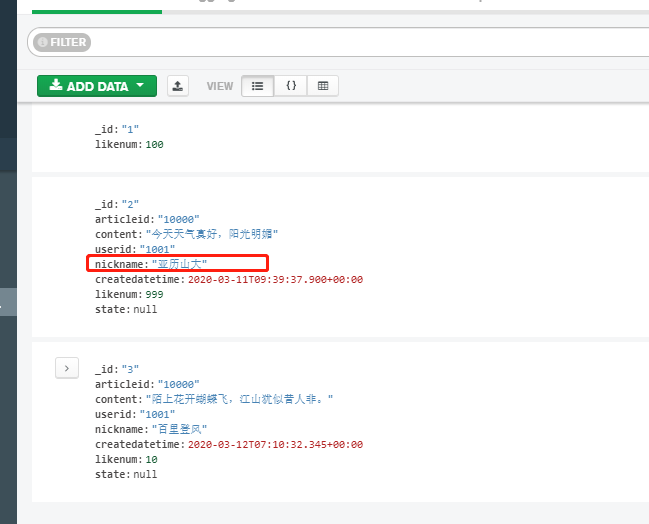
(2)更新所有用户为1001的用户昵称为百里玄策
//修改所有符合条件的数据 db.comment.update({userid:"1001"},{$set:{nickname:"百里玄策"}},{multi:true})

提示:如果不加后面的参数,则只更新符合条件的第一条记录
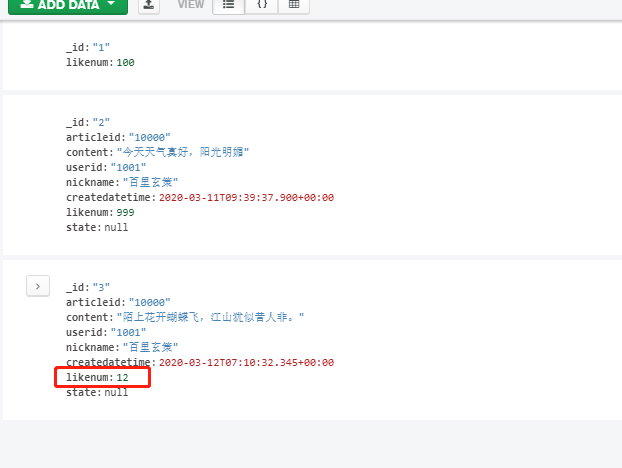
(3)列值增长的修改
如果我们想实现某个列值在原有值得基础上进行增加或减少,可以使用$inc运算符来实现。
需求:对_id为3的点赞数在原有的基础上,每次增加1
db.comment.update({_id:"3"},{$inc:{likenum:NumberInt(1)}})
9.6 删除文档
删除文档的语法结构:
db.语法.remove(条件)
以下语句可以将数据全部删除,请慎用
db.comment.remove({})

如果删除_id=1的记录,语句如下:
db.comment.remove({_id:"1"})

9.7 统计查询
统计查询使用count()方法,语法如下:
db.collection.count(query,options)
参数:
| Parameter | Type | Descreption |
|---|---|---|
| query | document | 查询选择条件 |
| options | document | 可选,用于修改计数的额外选项。 |
(1) 统计comment所有记录数:
db.collection.count() 或db.collection.count({})
(2)按条件统计记录数:
例如:统计userid=1001的记录条数
db.comment.count({userid:"1001"})
提示:默认情况下count()方法返回所有符合条件的全部记录条数。
9.8 文档的分页查询
可以使用limit()方法来读指定数量的数据,使用skip()方法来跳过指定数量的数据
基本语法如下所示:
db,collection_name.find().limit(number).skip(number)
如果你想返回指定条数的记录,可以使用find()方法后调用limit()来返回结果的条数,默认20。
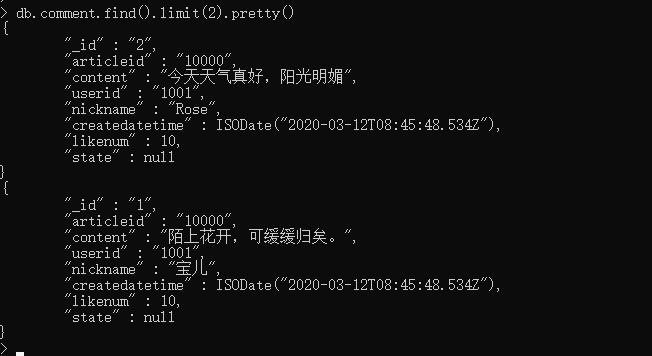
列如:
db.comment.find().limit(2).pretty()
skip()方法同样接受一个数字参数作为跳过记录的条数。(前N个不要),默认值是0.
语法:
db.comment.find().skip(10)
列如:每页两条,第二页开始跳过前两条数据,接着显式3和4条数据
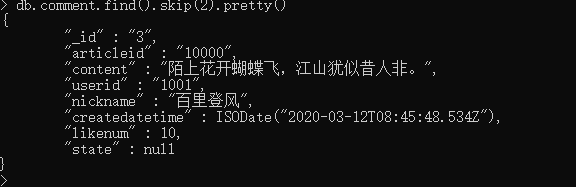
//第一页 db.comment.find().skip(0).limit(2).pretty() //第二页 db.comment.find().skip(2).limit(2).pretty()
9.9 排序查询
在 MongoDB 中使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
语法:
db.COLLECTION_NAME.find().sort({KEY:1})或 db.集合名称.find().sort(排序方式)
例如:对userid降序排序,并对访问量进行升级排序
db.commnent.find().sort({userid:-1,likenum:1})
提示:skip(),limit(),sort()三个放在一起执行的时候,执行的顺序是先sort(),然后skip(),然后是显示limit(),和命令编写顺序无关。
十 .复杂查询
10.1 正则表达式查询(模糊查询)
MongoDB的模糊查询是通过正则表达式的方式实现的,格式为:
db.commnent.find({field:/正则表达式/}) 或者 db.集合.find({字段:/正则表达式/})
提示:正则表达式是js的语法,直接量的写法。
例1,我要查询评论内容包含"江山"的所有文档,代码如下:
db.comment.find({content:/江山/}).pretty()
例2,我要查询评论内容中以"陌上花开"开始的所有文档,代码如下:
db.comment.find({content:/^陌上花开/}).pretty()

10.2 比较查询
<,<=,>,>= 这个操作符也是很常用的,格式如下:
db.comment.find({"field":{$gt:value}}) //大于: field>value
db.comment.find({"field":{$lt:value}}) //小于: field<value
db.comment.find({"field":{$gte:value}}) //大于等于: field>=value
db.comment.find({"field":{$lte:value}}) //小于等于: field<=value
db.comment.find({"field":{$ne:value}}) //不等于: field !=value
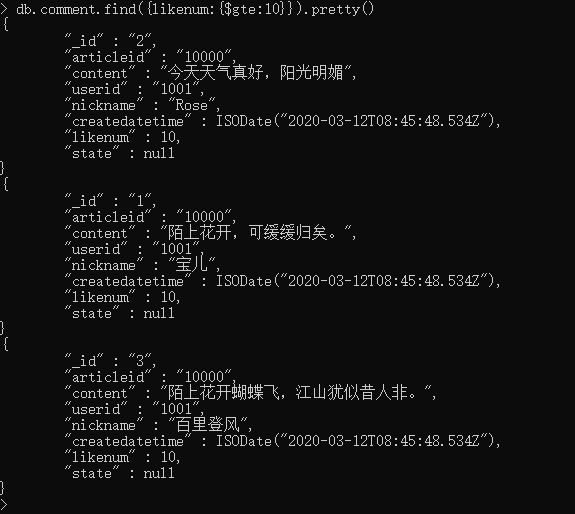
列如:查询评论点赞数likenum大于等于10的记录
db.comment.find({likenum:{$gte:NumberInt(10)}}).pretty()
或者 db.comment.find({likenum:{$gte:10}}).pretty()
10.3 包含查询
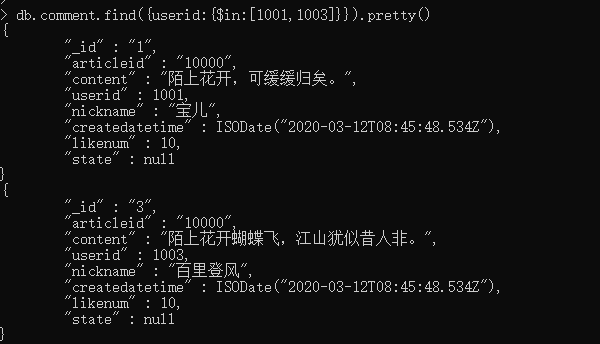
包含查询使用$in操作符。
列: 查询评论的集合中userid字段包含1001和1003的文档
db.comment.find({userid:{$in:[1001,1003]}}).pretty()
不包含使用$nin操作符。
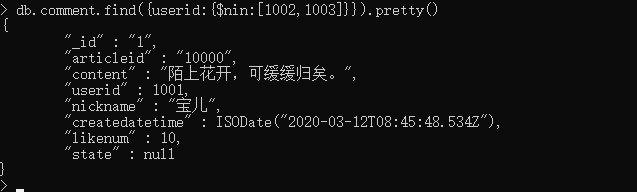
列: 查询评论的集合中userid字段不包含1002和1003的文档
db.comment.find({userid:{$nin:[1002,1003]}}).pretty()
10.4 条件连接查询
我们如果要查询同时满足两个以上条件,需要使用$and操作符将条件进行关联。(相当于sql的and)。
语法格式为:
$and:[{},{},{}]
列:查询评论集合中likenum大于等于200并且小于300的文档:
db.comment.find({$and:[{likenum:{$gte:200}},{likenum:{$lt:300}}]}).pretty()

如果两个以上的条件之间关系是"或者"的关系,我们使用$or操作符进行关联,与前面and的使用方式类似。
格式为:
$or:[{},{},{}]
列:查询评论集合中userid为1003或者点赞数likenum小于100的文档记录
db.comment.find({$or:[{userid:1003},{likenum:{$lt:100}}]}).pretty()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号