mysql基础
一.delete、drop、truncate区别
- truncate 和 delete只删除数据,不删除表结构 ,drop删除表结构,并且释放所占的空间。
- 删除数据的速度,drop> truncate > delete
- delete属于DML语言,需要事务管理,commit之后才能生效。drop和truncate属于DDL语言,操作立刻生效,不可回滚。
- 使用场合:
- 当你不再需要该表时, 用 drop;
- 当你仍要保留该表,但要删除所有记录时, 用 truncate;
- 当你要删除部分记录时(always with a where clause), 用 delete.
注意: 对于有主外键关系的表,不能使用truncate而应该使用不带where子句的delete语句,由于truncate不记录在日志中,不能够激活触发器
二.事务四大特性
- 原子性:不可分割的操作单元,事务中所有操作,要么全部成功;要么撤回到执行事务之前的状态
- 一致性:如果在执行事务之前数据库是一致的,那么在执行事务之后数据库也还是一致的;
- 隔离性:事务操作之间彼此独立和透明互不影响。事务独立运行。这通常使用锁来实现。一个事务处理后的结果,影响了其他事务,那么其他事务会撤回。事务的100%隔离,需要牺牲速度。
- 持久性:事务一旦提交,其结果就是永久的。即便发生系统故障,也能恢复。
三.MySQL的事务隔离级别
- 未提交读(Read Uncommitted):允许脏读,其他事务只要修改了数据,即使未提交,本事务也能看到修改后的数据值。也就是可能读取到其他会话中未提交事务修改的数据
- 提交读(Read Committed):只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读)。
- 可重复读(Repeated Read):可重复读。无论其他事务是否修改并提交了数据,在这个事务中看到的数据值始终不受其他事务影响。
- 串行读(Serializable):完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞 MySQL数据库(InnoDB引擎)默认使用可重复读( Repeatable read)
四.索引
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用 B_TREE。B_TREE 索引加速了数据访问,因为存储引擎不会再去扫描整张表得到需要的数据;相反,它从根节点开始,根节点保存了子节点的指针,存储引擎会根据指针快速寻找数据。
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址,即:MyISAM索引文件和数据文件是分离的,MyISAM的索引文件仅仅保存数据记录的地址。MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。MyISAM的索引方式也叫做“非聚集”的。
InnoDB引擎也使用B+Tree作为索引结构,但是InnoDB的数据文件本身就是索引文件,叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这种索引叫做“聚焦索引”。InnoDB的辅助索引的data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。InnoDB的索引实现后,不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。在Innodb中也不建议使用非单调的字段作为主键,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,建议使用自增字段作为主键。
MySQL数据库的四类索引:
- index ---- 普通索引,数据可以重复,没有任何限制。
- unique ---- 唯一索引,要求索引列的值必须唯一,但允许有空值;如果是组合索引,那么列值的组合必须唯一。
- primary key ---- 主键索引,是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值,一般是在创建表的同时创建主键索引。
- 组合索引 ---- 在多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。
- fulltext ---- 全文索引,是对于大表的文本域:char,varchar,text列才能创建全文索引,主要用于查找文本中的关键字,并不是直接与索引中的值进行比较。fulltext更像是一个搜索引擎,配合match against操作使用,而不是一般的where语句加like。 注:全文索引目前只有MyISAM存储引擎支持全文索引,InnoDB引擎5.6以下版本还不支持全文索引
所有存储引擎对每个表至少支持16个索引,总索引长度至少为256字节,索引有两种存储类型,包括B型树索引和哈希索引。
索引可以提高查询的速度,但是创建和维护索引需要耗费时间,同时也会影响插入的速度,如果需要插入大量的数据时,最好是先删除索引,插入数据后再建立索引。
五.哪些场景会造成索引生效?
5.1、应尽量避免在 where 子句中使用 != 或 <> 操作符
否则引擎将放弃使用索引而进行全表扫描;
5.2、尽量避免在 where 子句中使用 or 来连接条件
否则将导致引擎放弃使用索引而进行全表扫描,即使其中有条件带索引也不会使用,这也是为什么尽量少用 or 的原因;
5.3、对于多列索引,不是使用的第一部分,则不会使用索引;
MySql一次查询只能使用一个索引,如果针对多列条件查询,请建复合索引。
MySql一张表最多有16个索引,一个复合索引最多有16列,索引长度最大为256个字节。
5.4、如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不会使用索引;
5.5、like的模糊查询以 % 开头,索引失效;
select * from user where name like '%xuliu';
5.6、应尽量避免在 where 子句中对字段进行表达式操作
这将导致引擎放弃使用索引而进行全表扫描;
如: select id from t where num/2 = 100
应改为: select id from t where num = 100*2;
5.7、应尽量避免在 where 子句中对字段进行函数操作
例如:select id from t where substring(name,1,3) = 'abc';
以abc开头的,应改成:select id from t where name like ‘abc%’ ;
5.8、不要在 where 子句中的 “=” 左边进行函数、算术运算或其他表达式运算
否则系统将可能无法正确使用索引;
5.9、如果MySQL估计使用全表扫描要比使用索引快,则不使用索引;
6.0、不适合键值较少的列(重复数据较多的列)
假如索引列TYPE有5个键值,如果有1万条数据,那么 WHERE TYPE = 1将访问表中的2000个数据块。再加上访问索引块,一共要访问大于200个的数据块。如果全表扫描,假设10条数据一个数据块,那么只需访问1000个数据块,既然全表扫描访问的数据块少一些,肯定就不会利用索引了。
六.检测索引的效果:
show status like '%handler_read%'越大越好
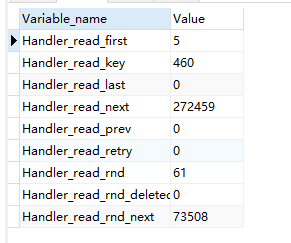
Handler_read_first:
The number of times the first entry was read from an index. If this value is high, it suggests that the server is doing a lot of full index scans; for example, SELECT col1 FROM foo, assuming that col1 is indexed.
此选项表明SQL是在做一个全索引扫描,注意是全部,而不是部分,所以说如果存在WHERE语句,这个选项是不会变的。如果这个选项的数值很大,既是好事 也是坏事。说它好是因为毕竟查询是在索引里完成的,而不是数据文件里,说它坏是因为大数据量时,简便是索引文件,做一次完整的扫描也是很费时的。
Handler_read_key:
The number of requests to read a row based on a key. If this value is high, it is a good indication that your tables are properly indexed for your queries.
此选项数值如果很高,那么恭喜你,你的系统高效的使用了索引,一切运转良好。
Handler_read_next:
The number of requests to read the next row in key order. This value is incremented if you are querying an index column with a range constraint or if you are doing an index scan.
此选项表明在进行索引扫描时,按照索引从数据文件里取数据的次数。
Handler_read_prev:
The number of requests to read the previous row in key order. This read method is mainly used to optimize ORDER BY … DESC.
此选项表明在进行索引扫描时,按照索引倒序从数据文件里取数据的次数,一般就是ORDER BY … DESC。
Handler_read_rnd:
The number of requests to read a row based on a fixed position. This value is high if you are doing a lot of queries that require sorting of the result. You probably have a lot of queries that require MySQL to scan entire tables or you have joins that don’t use keys properly.
简单的说,就是查询直接操作了数据文件,很多时候表现为没有使用索引或者文件排序。
Handler_read_rnd_next
The number of requests to read the next row in the data file. This value is high if you are doing a lot of table scans. Generally this suggests that your tables are not properly indexed or that your queries are not written to take advantage of the indexes you have.
此选项表明在进行数据文件扫描时,从数据文件里取数据的次数。
七.sql语句分类:
- DDL:数据定义语言(create drop)
- DML:数据操作语句(insert update delete)
- DQL:数据查询语句(select )
- DCL:数据控制语句,进行授权和权限回收(grant revoke)
- TPL:数据事务语句(commit collback savapoint)
八.数据库三范式:
-
第一范式:1NF是对属性的原子性约束,要求数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项;(只要是关系型数据库都满足1NF)
-
第二范式:2NF是在满足第一范式的前提下,属性完全依赖于主键。要求数据库表中的每个实例或行必须可以被惟一的区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主键
- 第三范式:3NF是在满足第二范式的前提下,非主键字段不能出现传递依赖,比如某个字段a依赖于主键,而一些字段依赖字段a,这就是传递依赖。解决:将一个实体信息的数据放在一个表内实现。
九.CHAR和VARCHAR的区别:
- CHAR和VARCHAR类型在存储和检索方面有所不同
- CHAR列长度固定为创建表时声明的长度,长度值范围是1到255
- 当CHAR值被存储时,它们被用空格填充到特定长度,检索CHAR值时需删除尾随空格。
十.Mysql中有哪几种锁?
- MyISAM支持表锁,InnoDB支持表锁和行锁,默认为行锁
- 表级锁:开销小,加锁快,不会出现死锁。锁定粒度大,发生锁冲突的概率最高,并发量最低
- 行级锁:开销大,加锁慢,会出现死锁。锁力度小,发生锁冲突的概率小,并发度最高

 浙公网安备 33010602011771号
浙公网安备 33010602011771号