flume1.8的安装及环境配置
简介FLume
A1.flume 作为 cloudera 开发的分布式、可靠、高可用的海量实时日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据的简单处理,并写到各种数据接收方的能力。
A2.它具有可靠的可靠性机制和许多故障转移和恢复机制,具有强大的容错能力
A3.它使用简单的可扩展数据模型,允许在线分析应用程序。Flume可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase等。
B1.Flume 支持多种来源,如:
-
“tail”(从本地文件,该文件的管道数据和通过Flume写入 HDFS,类似于Unix命令“tail”)
-
系统日志
-
Apache log4j (允许Java应用程序通过Flume事件写入到HDFS文件)。
C1.工作结构图:

D1.Flume-ng 核心三大组建
(官网:http://flume.apache.org/)
Flume-ng只有一个角色的节点:agent的角色,agent由source、channel、sink组成。
Source:Source用于采集数据,Source是产生数据流的地方,同时Source会将产生的数据流传输到Channel
Channel:连接 sources 和 sinks ,这个有点像一个队列。
Sink:从Channel收集数据,将数据写到目标源,可以是下一个Source也可以是HDFS或者HBase。
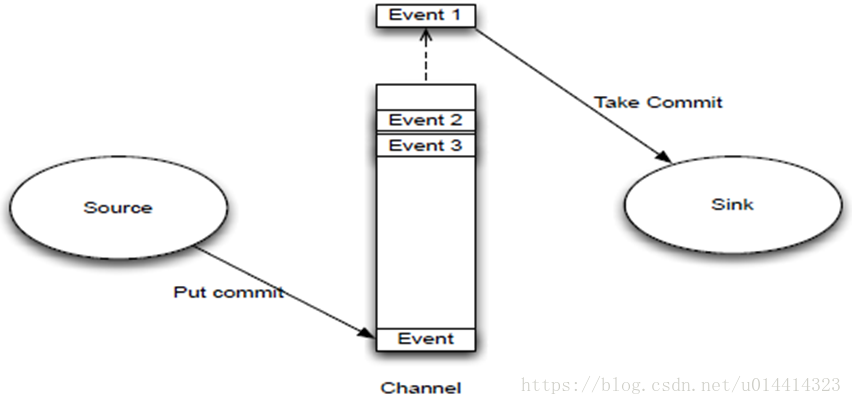
Event是Flume数据传输的基本单元
source监控某个文件,将数据拿到,封装在一个event当中,并put/commit到channel当中,channel是一个队列,队列的优点是先进先出,放好后尾部一个个event出来,sink主动去从channel当中去拉数据,sink再把数据写到某个地方,比如HDFS上面去。
学习方向:

一 .安装FLume
1.1 对Flume有了解的都知道,Flume是依赖JDK的,如果没有安装JDK的请看我的另一篇随笔:https://www.cnblogs.com/KdeS/p/11526907.html ,简单易懂,
1.2 切换root权限,装备下载Flume,这里我下载的是1.8的版本的,详细如下:
1 wget http://apache.fayea.com/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz
1.3 解压
1 tar zxvf apache-flume-1.8.0-bin.tar.gz
1.4 为了方便管理,我们在opt目录下新建一个文件文件名字就叫flume,把解压后的Flume放到放到flume目录下,为了方便记录把解压后的'-bin'这一部分去掉,如下:
1 mv apache-flume-1.8.0-bin /opt/flume/apache-flume-1.8.0
二.环境配置
2.1 为了运行方便,我们把bin目录加到Path中,如下:
1 vim /etc/profile
1 export FLUME_HOME=/opt/flume/apache-flume-1.8.0 2 export PATH=$PATH:$FLUME_HOME/bin
2.2 source /etc/profile
2.3 . /etc/profile(点的后面有个空格)
2.4 测试一下是否安装成功:(bin/flume-ng.sh 查看flume的flume-ng命令相关命令)

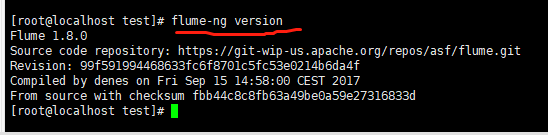
三.根据官网上的配置运行官网上的一个配置案例:从指定网络端口采集数据输出到控制台

图片中的红框中的内容相当于配置一个Agent(代理)
3.1 创建flume-test.properties
1 cd /opt/flume/apache-flume-1.8.0/conf 2 3 touch flume-test.properties 4 5 vi flume-test.properties
复制官网上的案例进行更改

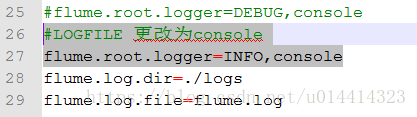
3.2 进入同级目录下的log4j.properties文件,更改log4j的日志级别,
flume.root.logger=INFO,LOGFILE 更改为flume.root.logger=INFO,console(在控制台输出)
四.安装telnet
1、检查是否安装telnet:
[root@localhost ~]# rpm -qa | grep telnet
若无输出内容,则表示没有安装。
2、进行telnet安装,客户端和服务器端:
yum -y install telnet
yum -y install telnet-server
3、查看是否安装xinetd (若安装则不安装):
rpm -qa | grep xinetd
![]()
4、安装xinetd服务:
yum -y install xinetd
5、telnet服务之后,默认是不开启服务,修改文件/etc/xinetd.d/telnet来开启服务:
注:如有则修改,第一次修改,此文件若不存在,可自己vim创建修改:
修改 disable = yes 为 disable = no
修改后的telnet文件为:
# default: yes # description: The telnet server servestelnet sessions; it uses \ # unencrypted username/password pairs for authentication. service telnet { flags = REUSE socket_type = stream wait = no user = root server =/usr/sbin/in.telnetd log_on_failure += USERID disable = no }
6、安装后检查:
rpm -qa | grep telnet
rpm -qa | grep xinetd
7、启动telnet和依赖的xinetd服务:
在centos7之前:$ service xinetd restart 或 $ /etc/rc.d/init.d/xinetd restart
在centos7中(无xinetd的service启动项):service xinetd restart -----> systemctl restart xinetd.service 或 /bin/systemctl restart xinetd.service
8、查看xinetd服务启动:
ps -ef | grep xinetd

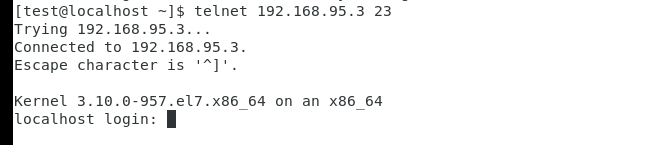
10、测试telent,
在测试前在防火墙中开启对应的端口或者直接选择关闭防火墙,如下远程连接,
五.测试运行flume-test.properties
bin/flume-ng agent --conf conf --name a1 --conf-file conf/flume-test.properties
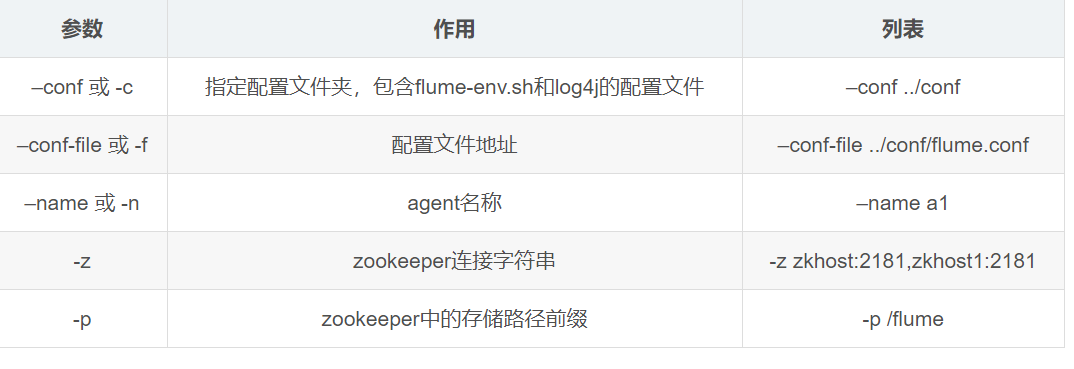
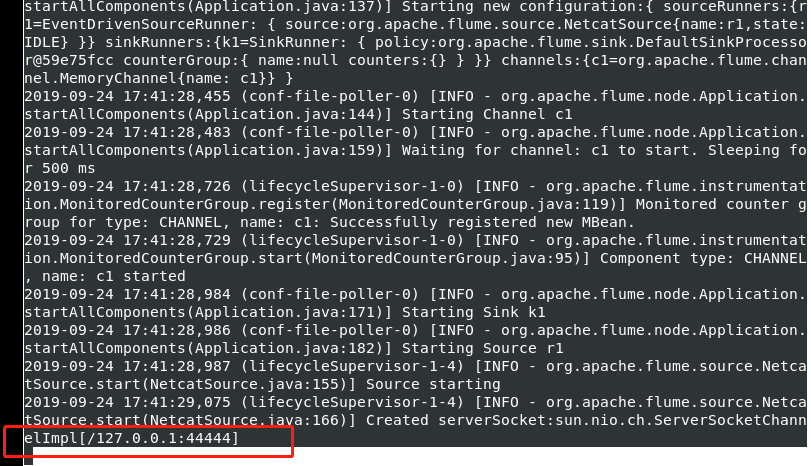
如上完成之后使用telnet链接或者使用netcat链接,连接成功后输入信息
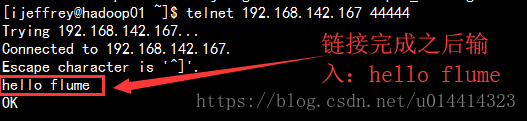
telnet 192.168.142.167 44444

退出telnet:输入ctrl + ] 然后输入quit

六.根据官网上的配置运行官网上的一个配置案例:监控一个文件实时采集新增的数据输出到控制台
6.1 创建 flume-apache-file.properties
#为agent的各个组件命名 #本例中,agent的名称为"a1" a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 描述/配置源 a1.sources.r1.type =exec a1.sources.r1.command = tail -f /var/log/httpd/access_log # type为logger意将数据输出至日志中(也就是打印在屏幕上) a1.sinks.k1.type = logger #channel配置信息 #type为memory意将数据存储至内存中 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 #将源和汇绑定到通道 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
# 与第一个案列不同之处变动在于这两点
a1.sources.r1.type =exec
#tail -f filename 会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容
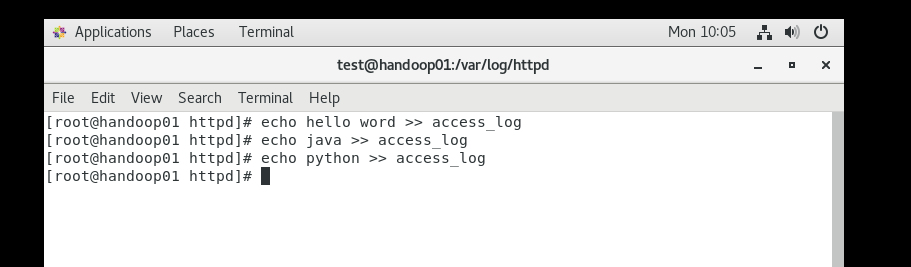
a1.sources.r1.command = tail -f /var/log/httpd/access_log
6.2 如上的配置有一个缺点,flume每次重启后都会重新从头消费,实际项目中我搭建的flume>>kafka>>elasticseach>>kibana,
数据都是百万级的,flume不小心挂了重启的话,重新消费后会在es中有两份重复的数据,所以推荐一下的另一种配置方式
p1_agent.sources = exec-source p1_agent.channels = memoryChannel p1_agent.sinks = kafka-sink # sources define p1_agent.sources.exec-source.type = TAILDIR p1_agent.sources.exec-source.positionFile = /var/log/flume/taildir_position.json p1_agent.sources.exec-source.filegroups = f1 p1_agent.sources.exec-source.filegroups.f1 = /opt/p1upgradebackstage/access_logs/localhost_access_log.* p1_agent.sources.exec-source.headers.f1.logType = access_log p1_agent.sources.exec-source.headers.f1.headerKey1 = value1 p1_agent.sources.exec-source.fileHeader = true p1_agent.sources.exec-source.maxBatchCount = 1000 # sinks define #p1_agent.sinks.kafka-sink.type = logger p1_agent.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink p1_agent.sinks.kafka-sink.brokerList = master59:9092,slave145:9092,slave113:9092 p1_agent.sinks.kafka-sink.topic = pd_p1upgradebackstage p1_agent.sinks.kafka-sink.batchSize = 5 p1_agent.sinks.kafka-sink.requiredAcks = 1 # channels define p1_agent.channels.memoryChannel.type = memory p1_agent.channels.memoryChannel.capacity = 100 # bind sources to channels and sinks to channels p1_agent.sources.exec-source.channels = memoryChannel p1_agent.sinks.kafka-sink.channel = memoryChannel
6.3 启动
bin/flume-ng agent --name a1 --conf conf --conf-file flume-apache-file.properties
//后台启动 正式环境一般都是后台启动
nohup bin/flume-ng agent --name a1 --conf conf --conf-file flume-apache-file.properties &


 浙公网安备 33010602011771号
浙公网安备 33010602011771号