随笔分类 - 大数据
摘要:Flink CDC (Change Data Capture) SQL 用于实现数据库的数据变更捕获,并通过 SQL 接口进行处理。以下是一个基本的示例,全量+增量数据mysql同步到clickhouse,展示如何使用 Flink CDC SQL 进行数据同步。 首先,确保你有 Flink 和 Fl
阅读全文
摘要:一 ,错误: spark报:too many open files 打开文件过多的意思 ulimit -a 查看打开的连接限制 ulimit -n 4096 扩大最大允许打开的文件数量设置为4096(临时的,重启后会还原) 修改系统配置文件(重启生效):vim /etc/security//li
阅读全文
摘要:package com.lg.blgdata.utils import redis.clients.jedis.{Jedis, JedisPool, JedisPoolConfig} import scala.collection.mutable.HashSet //jedis连接池 object
阅读全文
摘要:package com.lg.blgdata.utils import java.util.Properties import com.alibaba.druid.pool.DruidDataSourceFactory import javax.sql.DataSource import java.
阅读全文
摘要:问题: 解决办法: 1)启动Hadoop 2)输入指令:hadoop dfsadmin -safemode leave 出现该问题的原因是:hadoop处在安全模式下。所以hbase的操作会出现异常。 造成此问题的故障是:在没有退出旧版Hbase的情况下,擅自将其删除,然后按照了新版本的Hbase,
阅读全文
摘要:NameNode故障后,可以采用如下两种方法恢复数据。 方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录; 1. kill -9 NameNode进程 2. 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/df
阅读全文
摘要:一.scp(secure copy)安全拷贝 (1)scp定义: scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2) (2)基本语法 scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname 命令 递归 要拷贝的
阅读全文
摘要:一.HBase 链接:https://pan.baidu.com/s/1LH8DqHczMoalIUQyBjeiAw 提取码:easy 二维码: 二.Zookeeper 链接:https://pan.baidu.com/s/1Xln9hQ56xGgo66bCY7anbg 提取码:easy 二维码:
阅读全文
摘要:大数据Hadoop生态圈-组件介绍 Hadoop是目前应用最为广泛的分布式大数据处理框架,其具备可靠、高效、可伸缩等特点。 Hadoop的核心是YARN,HDFS和Mapreduce。随着处理任务不同,各种组件相继出现,丰富Hadoop生态圈,目前生态圈结构大致如图所示: 根据服务对象和层次分为:数
阅读全文
摘要:这是基于 logback=>kafka=>elasticsearch=>kibana的一套完整的日志采集系统,这里做java配置部分的记录 一.pom.xml <!--kafka依赖 --> <dependency> <groupId>org.springframework.kafka</group
阅读全文
摘要:对于低版本的Kibana,我们可以在浏览器中输入如下地址来查看Elasticsearch的索引列表。 http://{Elasticsearch IP}:9200/_cat/indices?v
阅读全文
摘要:MongoDB 索引 一.概述 索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。 这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。 索引是特殊的数据
阅读全文
摘要:选择切换数据库: use articledb 插入数据: db.comment.insert({bson处据}) 查询所有数据: db.comment.find() 条件查询数据: db.comtent.find({条件}) 查询符合条件的第一条记录: db.comment.findOne({条件}
阅读全文
摘要:目录 一、什么是MongoDB 二、什么是NoSQL 三、mongodb的使用场景 四.windows下安装mongoDB(zip版) 3.1 下载mongoDB的zip包 3.2 解压名称改为mongodb 3.3 解压后的来个两种启动方式: 1.1 命令参数方式启动服务(开发调试使用) 2 .1
阅读全文
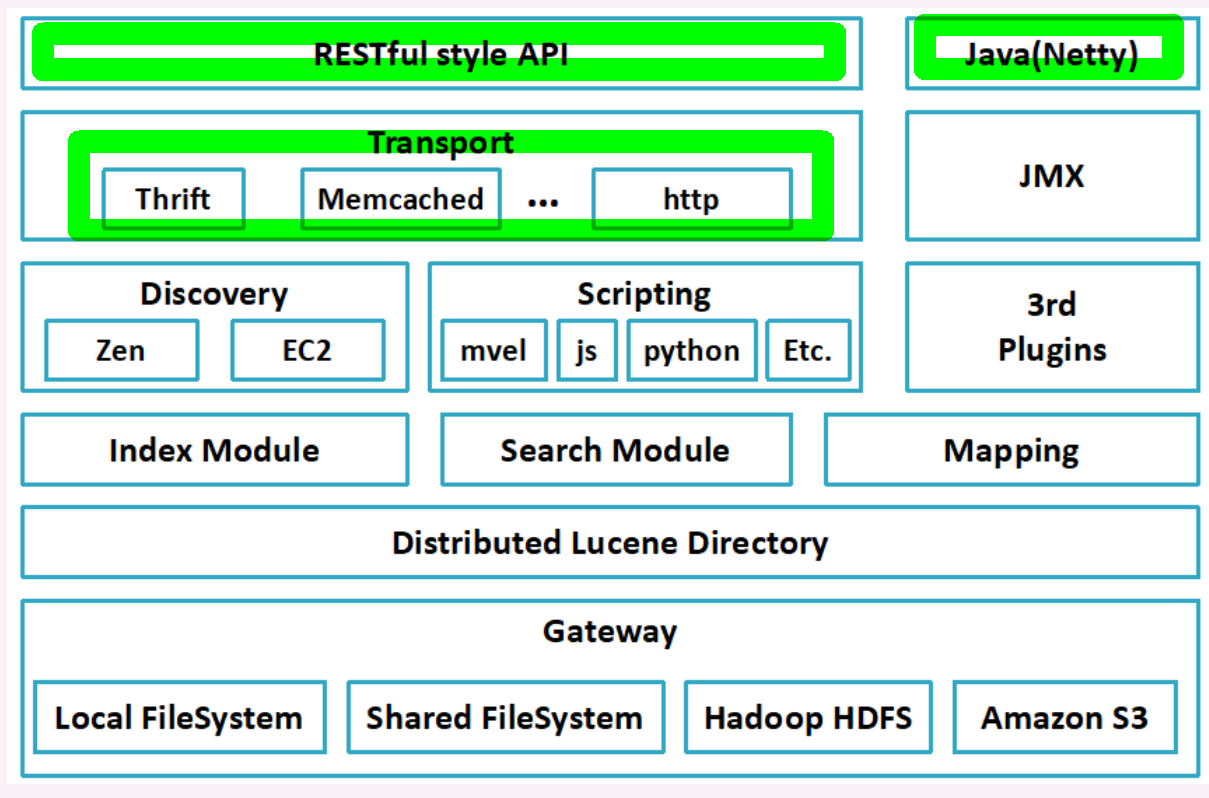
摘要:一 .版本控制 Elasticsearch采用了乐观锁来保证数据的一致性,即当用户对document(文档,即关系数据库中表里的一条数据)进行操作时,并不需要对该document做加锁、解锁的操作,只需要指定要操作的版本即可。当版本号一致时,Elasticsearch会允许该操作顺利进行,而当版本号
阅读全文
摘要:结论与下文相同,kafka不同topic的consumer如果用的groupid名字一样的情况下,其中任意一个topic的consumer重新上下线都会造成剩余所有的consumer产生reblance行为, 即使大家不是同一个topic,这主要是由于kafka官方支持一个consumer同时消费多
阅读全文
摘要:一.JDK和zookeeper的安装 首先我们要知道:kafka依赖于zookeeper而zookeeper又依赖于jdk 1.1.jdk的安装参考这里安装:https://www.cnblogs.com/KdeS/p/11526907.html 1.2.zookeeper 的安装 1.2.1.下载
阅读全文
摘要:官网地址:https://www.elastic.co 1.kibana的作用认识 Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看存放在Elasticsearch中的数据。Kibana与Elasticsearch的交互方式
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号