批量插入或更新操作之ON DUPLICATE KEY UPDATE用法
实际的开发过程中,可能会遇到这样的需求,先判断某一记录是否存在,如果不存在,添加记录,如果存在,则修改数据。在INSERT语句末尾指定ON DUPLICATE KEY UPDATE可以解决这类问题。
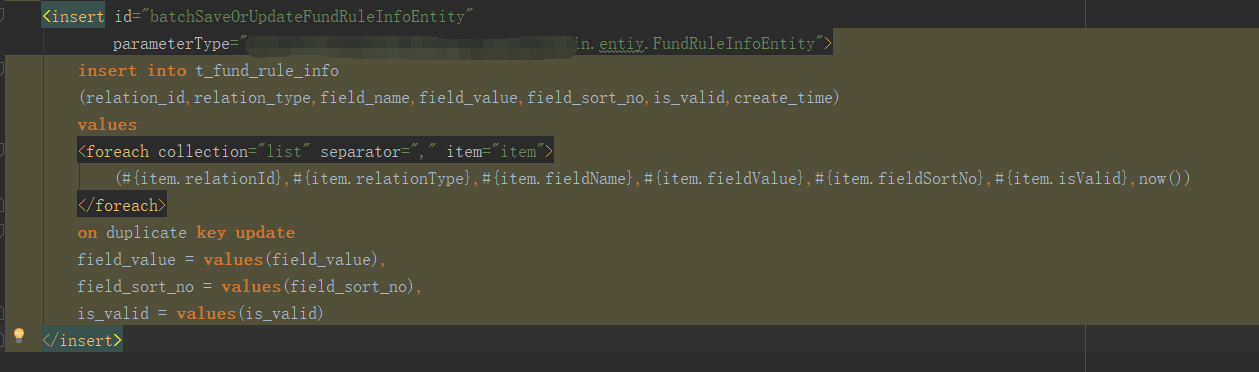
其用法如下:如果在INSERT语句末尾指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则在出现重复值的行执行UPDATE操作,如果不会导致唯一值重复的问题,则执行INSERT操作。
如下sql:数据库表中需建立唯一索引
UNIQUE KEY `uniq_relation_id_field_name` (`relation_id`,`field_name`,`relation_type`) USING BTREE

 浙公网安备 33010602011771号
浙公网安备 33010602011771号