20200401 听觉感知
听觉感知
口语速率最高达每秒12个因素。人类能理解的口语速度最多不能超过每分钟50-60个语音。言语知觉存在2个困难问题:一是线性问题。正常口语中,音素会出现重叠现象,同时存在一种协同发音现象,即一个语音片段的产生会影响到后一个片段的产生。二是非恒定性问题。任何给定语音成分的声音模式并不是恒定不变的,而是受到前后一个或多个声音的影响。这对辅音来说更是如此,因为它们的声音模式常常依赖于紧随其后的元音而定。
听觉通路
从耳蜗到听觉皮质的听觉系统是所有感觉系统通路中最复杂的一种。听觉系统每个水平上发生的信息过程和每一水平的活动都影响较高水平和较低水平的活动。在听觉通路中,从脑的一边到另一边有广泛的交叉。
进入耳蜗神经核后,第八对脑神经听觉分枝纤维终止于耳蜗核的背侧和腹侧。从两个耳蜗核分别发出纤维系统,从背侧耳蜗发出的纤维越过中线,然后经过外侧丘系上升至皮质。外侧丘系最后终止于中脑的下丘,从腹侧耳蜗核发出的纤维,首先与同侧和对侧的上橄榄体复合体以突触联系,上橄榄体是听觉通路中的第一站,在这里发生两耳的相互作用。
上橄榄复合体由几个核组成,其中最大的是内侧上橄榄体和外侧上橄榄体。内侧上橄榄体和关联到眼球运动的声音定位有关,凡具有高度发展的视觉系统以及能注视声音的方向而作出反应的动物,内侧上橄榄核有显著的外形。外侧上橄榄体则与独立于视觉系统以外的声音定位有关,具有敏锐的听觉但视觉能力有限的动物,都有显著的外侧上橄榄体。
从上橄榄复合体发出的纤维上升经过外侧丘系达到下丘。从下丘系将冲动传达到丘脑的内侧膝状体。连接这两个区域的纤维束叫做下丘臂。从内侧膝状体,听觉反射的纤维将冲动传导颞上回(41区和42区),即听觉视皮层。
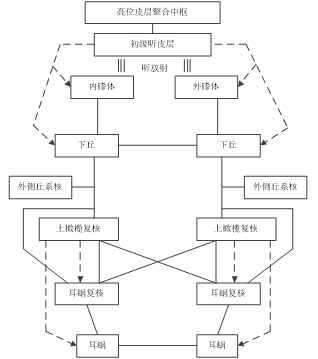
听觉通路
听觉信息的中枢处理
听觉中枢纵跨脑干、中脑、丘脑的大脑皮层,是感觉系统中最长的中枢通路之一。中枢听觉系统对声音有加工、分析的作用,像感觉声音的音色、音调、音强、判断方位。还有专门分化的细胞,对声音的开始和结束分别产生反应。传到大脑皮层的听觉信息还与大脑中管理“读”“写”“说”的语言中枢相联系,有效完成我们经常用到的读书、写字、说话等功能。
从耳蜗神经传入的冲动,在时间和空间上同所接受的声音特性不同而有不同的构型,这是输入信息编码的总形式。最后产生的听觉,能准确而精细地反映声音的各种复杂特性。
频率分析机理
关于耳蜗频率分析机理的意见分歧很大,但基本上可用两种观点概括:一是部位原则或部位学说,认为不同频率的声音刺激兴奋基底膜不同部位的感受细胞,兴奋部位是频率分析的依据。二是时间原则或冲动频率学说,认为不同频率的声音使听神经兴奋后发放不同频率的冲动,冲动频率是声音频率分析的依据。以上两种观点都有事实依据,但也各有不足之处。现在普遍认为两者不是互相排斥,二是可以互相补充的。比如,从耳蜗核至听皮层的各级中枢的某些部位,神经细胞的排列或多或少地有频率区域分布(部位原则);在内膝体及它以下各级听觉中枢中,都观察到神经单元放电与刺激声的同步锁相关系(时间原则),特别是在耳蜗核和上橄榄核水平尤为明显。
听觉的频率分析不是一个简单的周边过程,中枢在精确的声音辨别中起决定性作用。比如根据计算耳蜗的频率分辨率是不高的,在1KHz左右时约为30Hz,而人在1KHz左右时却可辨别3Hz甚至更小的频率差。精确的频率分析显然是在中枢进行的。心理物理实验结果表明,人的频率辨别精度与声音的信号时程之间有特定的函数关系。当信号时程短于某一临界时间T时,辨别的精确度与信号时程t的平方根成正比,或辨别阈ΔF与t的平方根成反比,即ΔF=Kt-1/2(t < T)。超出这一临界时间后,辨别精确度便恒定在最佳水平,不再随时程增长而改变,即ΔF=K (t > T)。T为120-150ms。这揭示听觉中枢可能有积累输入信息并对它进行统计学处理的过程,因为若对某一量进行多次测量取其统计值,则测量结果的精确度正是与测量次数的平方根成正比。
强度分析机理
被兴奋的神经单元是高阈值还是低阈值,兴奋单元的总数是多少,发放的神经冲动是多少,这三者都可以成为强度分析的依据。但有资料显示,听皮层及其他听觉中枢与声音的强度间还有一定的区域分布关系,即不同的区域分别对不同的刺激强度敏感,这表明似乎部位原则也在起作用。
声源定位和双耳听觉
双耳感受到的声音时间差和强度差便是声源定位的主要依据。对于高频声,强度差的作用较重要;对于低频声,时间差的作用较重要。
另外,由于双耳综合作用,声音的响度可以增加,相当于单耳时提高3-6dB;双耳听觉的辨别能力比单耳好,特别是在有噪声干扰的情况下,双耳听觉对语言的识别能力明显好于单耳。在双耳听觉条件下,右耳对语言信号的感受似占较重要的地位,左右则似对非语言信号的感受较重要,这可能和大脑两半球的分工有关。
对复杂声的分析
关于听觉系统如何辨别复杂的问题,目前存在两种截然不同的观点:①复杂声的感受以听觉系统对其简单组成成分的感受为基础,复杂声在听觉中枢引起的神经活动过程,是各组成成分引起的神经活动过程的总和。②听觉系统有分工检测各种复杂声音或声音某种特征的专门结构单元,称为探测器或特征检测器,它们只对特定的声音或特定的声音特征敏感,对其他声音或声音特征则无反应。
韵律认知
语音信息流包括音段信息和韵律信息。音段信息通过音色来表达,韵律信息通过韵律特征来表达。
韵律特征主要包含3个方面:重音、语调和韵律结构(指韵律成分的边界结构)。由于它可以覆盖两个以上音段,所以为超音段特征。韵律结构是一个层次结构,一般公认有3个层次,从小到大依次是韵律词、韵律短语、语调短语。
语调构造是由韵律结构和重音结构决定的。语调变化主要是声调调域(Range)和调阶(Register)的改变,声调变化主要是音高特征的改变。调域受说话人的心理状态、语气、韵律结构等因素的影响会发生改变。
SAMPA是目前国际上同行的可机读语音键盘符号系统,在语料库的音段标注中广泛使用。在汉语普通话的语音音段标注中已制定出一套可行的SAMPA-C符号系统。
韵律生成
迄今为止,最全面的韵律产生模型是由Levelt等人提出的韵律编码和加工模型【416】。Levelt认为,口语句子的产生过程中,所有阶段的加工都是并行的、递增的。韵律编码包括许多过程,一些在词的范畴加工,一些在句子的范畴加工。当句子的句法结构展开时,词汇的语音规则也产生了。词汇通常分为两部分:Lemma(包含语义和句法特征)和Lexeme(包含词形及音韵形式)的提取。韵律生成可分为3个阶段:
一是词形-韵律提取,以Lemma作为输入提取Lexeme。所以韵律特征的生成不需要知道音段信息。
二是音段提取,以Lexeme作为输入提取音段内容(词所包含的音素及其在音节中的位置),然后韵律和音段二者结合在一起。
三是话语语音规划,由韵律产生器执行,产生句子的韵律和语调模式。其中韵律的产生包括两个主要步骤:①产生韵律词、韵律短语和语调短语等韵律单元。词形-韵律提取阶段的加工结果与连接成分组合,成为韵律词。通过扫描句子句法结构,再综合各类相关信息,然后把语法短语的扩展成分包含进来,组成一个韵律短语。而说话者在语流某个点上的停顿,产生语调短语。②产生韵律结构的节律栅。在句子韵律结构和单个词的节律栅的基础上,韵律产生器最终构建出整个句子的节律栅。最后用节律仍未表示重音和时间模式?。
1999年,Levelt又提出了单词的产生过程中韵律生成的新观点,认为在荷兰语、英语和德语这样的重音语言中,存在一个主要的词韵律模式,即词重音放在第一个全元音音节上。所以规则词的重音在递增的音节化过程中是遵照这个规则自动产生的,而不是提取的。不规则词的重音不能自动产生。所以,只有不规则词的韵律结构,才作为音韵代码的一部分被储存起来。
神经机制
Levelt等用元分析的方法分析了58个脑功能成像研究结果,总结词汇产生过程的神经机制:视觉和概念上的引入过程涉及枕叶、腹侧颞叶和前额区(0-257ms);接着激活传至Wernicke区,单词的音韵代码存储在该区,这种信息传播至Broca区和(或)颞左中上叶,进行后音韵编码(275-400ms);然后进行语音编码,这一过程与感觉运动区和小脑有关,激活感觉运动区进行发音(400-600ms)。
实验表明,语言学韵律的产生仅激活左半球,而情感韵律的产生则仅仅激活右半球。
语音识别
以1952年贝尔实验室研制的特定说话人孤立词数字识别系统为起点,语音识别发展历程大致可分为4个阶段:一是20世纪50年代至70年代,以DWT、LPC、VQ和N-GRAM技术为主。二是20世纪80年代至90年代中期,以HMM技术为主。三是20世纪90年代中期至本世纪初,以GMM+HMM技术为主。四是21世纪初至今,以DL技术为主,声学建模由传统的基于短时平稳假设的分段建模方法变革到基于不定长序列的直接判别式区分的建模。
系统结构
语音识别系统包含4个主要模块。
1. 信号处理模块。主要进行前端信号处理与特征抽取,输入为语音信号,输出为特征向量。随着远场语音交互需求越来越大,该模块的地位越来越重要。主要过程:①声源定位;②消除噪声;③自动增益;④语音增强;⑤频域变换;⑥特征提取。
2. 声学模型。主要对声学和发音学知识建模,输入为特征向量,输出为某条语音的声学模型得分。该模型是对声学、语音学、环境的变量,以及说话人性别、口音的差异等的知识表示,其好坏直接决定整个语音识别系统的性能。
3. 语言模型。主要是对一组字序列构成的知识表示,用于估计某条文本语句产生的概率,称为语言模型得分。模型中存储的是不同单词之间的共现概率,一般从语料库中估计得到。语言模型与应用领域和任务密切相关,当这些信息已知时,语言模型得分更加精确。
4. 解码器。根据声学模型和语言模型,将输入的语音特征矢量序列转化为字符序列。解码器将所有候选句子的声学模型得分和语言模型得分融合在一起,输出得分最高的句子作为最终的识别结果。
基于深度神经网络的语音识别系统
相比传统的GMM-HMM框架,最大改变是采用深度神经网络替换GMM模型对语音的观察概率进行建模。
最初主流的深度神经网络是最简单的前馈网络(Feedforward Deep Neural Network, FDNN),其相比GMM优势在于:①使用FDNN估计HMM的状态的后验概率分布不需要对语音数据分布进行假设;②FDNN的输入特征可以是多种特征的融合,包括离散的或连续的;③FDNN可以利用相邻的语音帧所包含的结构信息。
考虑到语音信号的长时相关性,一个自然而然的想法就是选用具有更强长时建模能力的神经网络模型,于是循环神经网络(RNN)近年来逐渐替代FDNN成为主流方案。随后引入长短时记忆模块(LSTM),解决了传统简单RNN梯度消失等问题。再后又引入链接时序分类CTC,使得训练过程无须帧级别的标注,实现有效的“端对端”训练。端到端的语音识别系统直接预测字符而非音素,从而也就不再需要使用词典和决策树了。
语音合成
按照人类言语功能的不同层次,语音合成也可以分为三个层次,即从文字到语音的合成、从概念到语音的合成、从意向到语音的合成。目前的语音合成技术只能到达第一个层次。
文字到语音合成
典型系统由文本分析、韵律预测、声学模型3个模块构成。
文本分析模块
文本分析是语音合成系统的前端,它的作用是对输入的任意自然语言文本进行分析,输出尽可能多的语言相关特诊和信息。它的处理流程依次为:文本预处理、文本规范化、自动分词、词性标注、字音转换、多音字消歧、字形到音素(Grapheme to Phoneme, G2P)、短语分析等。
韵律预测模块
韵律即实际语流中的抑扬顿挫和轻重缓急,例如重音的位置分布及其等级差异,韵律边界的位置分布及其等级差异,语调的基本骨架及其跟声调、节奏和重音的关系等。韵律预测模块接收文本分析模块的处理结果,预测相应的韵律特征, 包括停顿、句重音等超音段特征。
声学模型模块
目前主流有2种方法:一是基于时域波形的拼接合成方法,首先对基频、时长、能量和节奏等信息建模,并在大规模语料库中根据这些信息挑选最合适的语音单元,然后通过拼接算法生成自然语言波形。二是基于语音参数的合成方法,根据韵律和文本信息的指导来得到语音的声学参数,然后通过语音参数合成器来生成自然语音波形。
概念语音转换
日本大阪大学实现了一种概念语言转换系统。这是一个基于格结构表述的语音输出系统SCOS(http://www.zzrtu.com/jsj/)。
听觉场景分析
听觉场景分析(Auditory Scene Analysis, ASA)源自Cherry在1953年发现的鸡尾酒效应,90年代初由加拿大Bregman提出【100】。1995年,Markus提出一种基于人的双耳听觉特性的双耳模型CASA方法【461】。1999年,Godsmark和Brown进一步发展了一种黑板模型的计算听觉 场景分析模型【271】。
ASA是用来研究听觉系统如何对外界刺激进行组织与加工的。其认为有两个:一是找出那些能够使声谱成分组合到一起或使它们分离成独立的听觉流或表象的声学特征;二是研究听觉分组的方法。场景分析包括2个阶段:一是以格式塔原则为基础的初级分析,它把不同感觉元素分配到相应组中;二是图式加工,它可以对知觉组织进行验证和修复。这两个阶段分别对应于自下而上和自上而下两个处理过程。
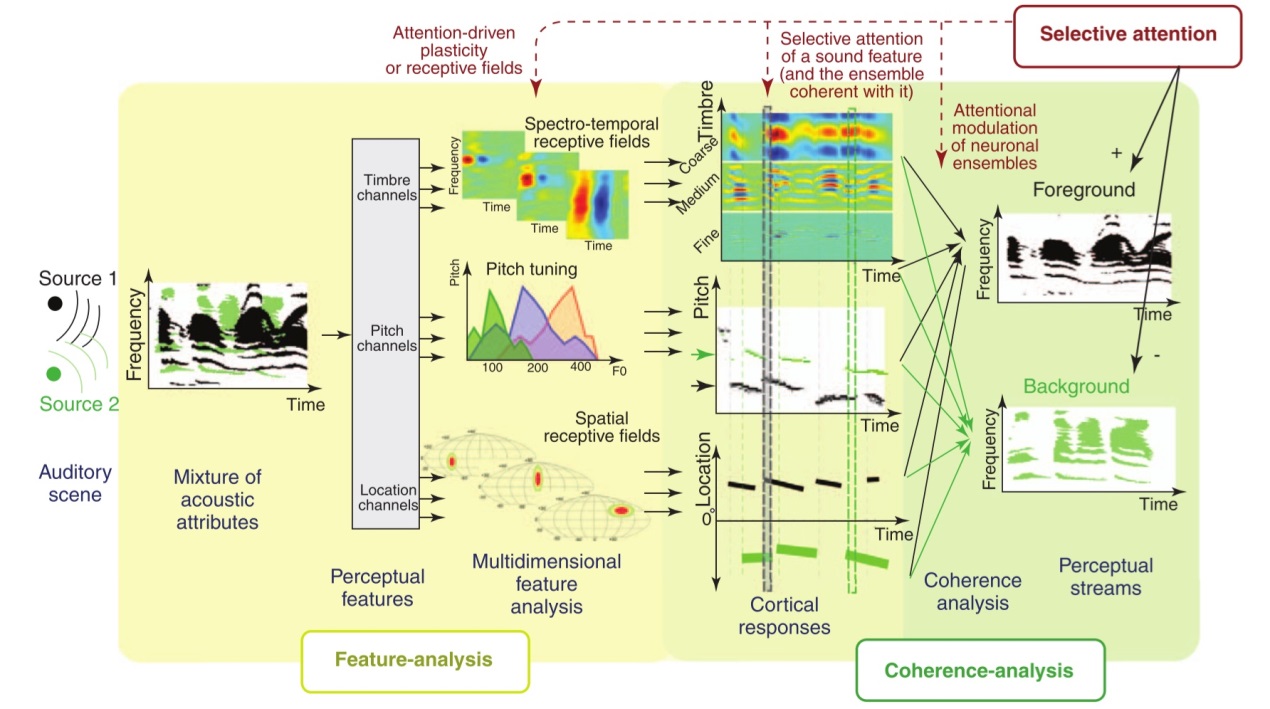
初级分析
初级分析过程是先天的,无须有意注意参与。其策略是:先把听觉信号分割成许多独立的单元,这些单元与声谱中特定时域和频域相对应。然后,对这些单元进行分组或分离。
分组:指听觉系统把某些具有相似特征或时间接近的音知觉为一个流,使之从复杂的环境声中突出出来。
分离:指从复杂环境声中辨别出声音的不同来源或区分不同声音。
分离和分组是一对统一的概念,如果出现了分组,也就意味着流与流之间产生了分离。
初级分析包括序列整合和时间性整合。前者把在不同时间内顺序出现的谱成分纳入一个知觉流,以便计算环境中声音的序列特性;后者则把同时出现的成分分开,将它们放入不同的流中。
序列整合
序列分组中的流形成遵循接近性或相似性原则,时间或频率接近的音将被分成一组。
序列整合有两种形式:一是对由两个音高不同的简单音交替出现构成的序列的整合,听者会把这个序列听成两个来源不同、分别由低音和高音构成的流。二是对由频率关系较为复杂的音所构成的序列进行整合。
把两组频率关系变化的音,按一定的顺序排列成一个序列,该序列能否产生曲调取决于音之间的频率关系。当两组音的频域相同时,曲调将消失;但如果它们分别在两个没有重叠的频率范围内,则曲调便被听成一个独立的流。
影响流分离最重要的两个因素:一是交替速度,二是两个交替出现音之间的频率差。Bregman等认为【100】,产生分组效应的时间间隔为35ms。Darwin等发现【170】,当单个谐波提前或滞后32ms时,这个谐波就会与其他谐波产生分离。Dai等甚至认为【169】,听者可以按照特定任务要求,去调节时间整合间隔。但究竟是相同频率音之间的间隔重要,还是两个不同频率音之间的时间间隔重要,这个问题还有待进一步研究。
序列分组的影响因素还有基频、时间接近性、谱形状、强度和空间位置等。这些因素在分组中有竞争也有合作。如果所有因素对分组都有促进作用,则分组将被加强。例如,空间差异与其他因素联合起来时,其作用最强;又如,仅响度不同的两个声音可能不会产生分离,但如果加入其他差异,则响度可能起重要作用。
时间性整合
声音中的谐波在频域中呈线性分布,而在基底膜上激活的相应位置则呈对数分布。在对数频率单元中,低次谐波之间相距较远,而高次谐波则相距较近。因此,谐波捕获有如下规律:①复合音中低次谐波比高次谐波易被捕获;②包含奇次谐波的谱成分比包含连续谐波的谱成分易被捕获;③相邻谐波被剔除的谐波易被捕获。因此,谐波之间的频率相差越大,这些谐波越容易从复合音中被捕获。
Duifhuis等发现【199】,在音高知觉中,听觉系统能够把额外声从复合音中剔除,其作用原理如同筛子,对信息进行过滤,称这种工作机制为“谐波筛”(Harmonicsieve)。那些与基频很接近的谐波可以通过筛子,而其他额外声则无法通过,这种效应在低信噪比情况下更为突出。谐波筛是流形成的机制之一,其工作方式不是全或无的,而是渐进的。在失调比例很小的情况下(3%-8%),谐波仍然能够通过谐波筛。谐波筛只对那些可分辨的谐波起作用,它不能完全把额外音从元音的第一共振峰频域中剔除,因为两者之间可以产生部分整合。
调频和调幅对同时性整合同样产生影响。FM中,听觉系统使用FM范围差异对同时呈现的音进行知觉分离。FM有两种:一是等差调制,它把原来的每个谐波都加上相同的频率。通过这种变化后,它们之间的谐波关系消失,从而使音的不同成分产生分离。二是等比调制,即每个谐波乘以相同的整数。这种处理之后,其谐波关系没有改变,但谐波之间的间距被扩大了。AM使不同谱位置上振幅产生变化,这种变化以及它们的出现时差和消失时差都对流分离产生影响。振幅的同步变化可以使谱产生分离,这与神经活动特征相一致。对应于不同谱位置的神经元的同步活动,保持时间很短。在频谱图上的每一段内,相对应的神经元同步活动,而段与段之间则不同步。音的识别就是通过对这些段中同步性变化的察觉而实现的。
实验表明,空间位置信息的频率信息的加工可能是独立的。另外,人可以同时听到不同位置上频率不同的两个纯音,两者不会融合。例如,在250-4000Hz内,最大频率差超过7%时,便不会产生融合。虽然听者把左右耳声音听成两个独立的音,但当双耳听到的音在频率上接近时,便出现双耳整合。
图式加工
听者把环境中特定的声音信号存入记忆中,形成认知单元,也即认知图式。当听觉系统获得的信息模式与图式相同时,图式将被激活,并且通过图式对模式的其余部分进行推测。图式还可以被与其相关联的其他图式激活。
1.注意与知识的作用
有意注意可以控制图式,只要任务要求注意参与,图式就会出现,即产生以图式为基础的分离。听觉系统可以利用频率线索把注意集中于一个特定的频率范围内。注意参与的加工过程可以很容易地把一个流分离,但不能对流之间的信息进行整合,因为注意只能指向一个流。图式形成过程就是获得关于刺激知识的过程。利用获得的知识,听者可以对刺激的变化趋势进行预测。当我们听到一个重复的音时,就会掌握它的规则,形成图式。这些规则知识使我们心理上做好准备,把这一序列整合到连续的心理表征之中。由于规则可以很容易地使注意集中,所以它对流形态的影响很大。轨迹规则效应在有记忆参与的任务中最明显,以轨迹为基础的组织效果随刺激呈现次数增加而增加。
2.语音的加工
对言语声的组织同样有两种形式:一是序列整合,把按顺序出现的词(或元音)的各部分整合到一起,这是词识别的基础。产生这种整合的前提条件是相邻部分的声学特性(如:音高、共振峰以及基频等)具有连续性,或相差不大。语音的流分离与非语音的流分离一样,也受到序列速度的影响,速度越快分离程度也越大。二是同时性整合,对众多的声音进行同时性整合,从而形成一个直觉流。同时性整合过程中,基频(或音高)是一个重要线索,差异越大,月容易分离。共振峰也表现出相同的作用规律。此外,声音的空间位置在同时性整合中也起一定作用,不同位置的声音很容易被区分。
初级分析与图式加工之间的关系
两者在功能上不是独立的,可能存在相互竞争。布莱曼等认为【100】:①图式加工在初级分析之后进行;②通过训练和学习,信息就可以用图式表征;③图式不参与听觉分析中的流形成过程;④图式描述的是知觉元素的典型特征,不论辅音、元音、音节或其他言语成分都是如此。
这两个过程对知觉的影响不同。①初级分析过程把感觉信息分离,而图式加工过程则对信息进行选择,而不是将它们从混合音中移走。②初级分析中的分组是对称的,当它把高音和低音分离时,就形成两个独立的流。同样,也可以把两个来自不同空间位置的音分离开,判断出一个音来自左边,另一个来自右边。图式加工则没有这种对称性。在一个混杂环境中,我们可以很容易地听出自己的名字,但并不能辨认出名字出现时的背景音是什么。③初级分析和图式加工的范围也不同,图式加工涉及的时间范围比初级分析的时间范围大。④两个系统所加工的感觉信息相同,但两者的加工难度不同,初级分析比图式加工更困难一些。
言语行为
Austin首先提出语言使用问题并进行认真研究,他认为,说任何一句话时,人们同时完成三种行为:①言内行为,②言外行为,③言后行为。
【100】Bregman. Auditory Scene Analysis. 1990
【271】Godsmark, Brown. A black board architecture for computational auditory scene analysis. 1999
【416】Levelt, Speaking: From intention to articulation. 1989
【461】Markus. Binaural Modeling and auditory scene analysis. 1995
本文来自博客园,作者:koala999,转载请注明原文链接:https://www.cnblogs.com/koala999/articles/16989288.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号