关于DeepSeek-R1的五大认知误区
打破迷雾:关于 DeepSeek-R1 的五大真相
近期由深度探索公司(DeepSeek)推出的R1大模型在行业内掀起热潮,其突出的逻辑分析能力被许多技术爱好者称为"推理之王"。但伴随着关注度的提升,一些模糊的认知也开始悄然传播。为了让大家能真正理解这项技术革新背后的本质,本篇文章将用通俗易懂的语言,解读关于这款模型的五个典型认识误区。
一、在线“满血”模型 == 本地部署模型?
关于 DeepSeek-R1 模型的相关内容充斥在网上的各种公众号和文章里,有很多内容是教大家怎么部署本地 DeepSeek,或者教大家如何使用“满血”DeepSeek,导致让很多初次接触这款模型的人误认为,“本地部署”的模型和在线“满血”的模型是一回事,但实际上他们存在显著差异。
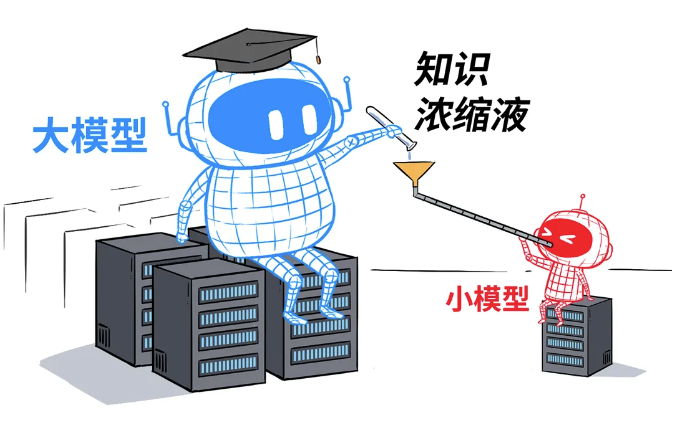
首先科普两个概念,大模型参数和模型蒸馏。
参数简单理解就是,大模型的参数越多,知道的知识越多,能力就越强。比如我们熟知的通义千问大模型,如 Qwen2.5-7B 、 Qwen2.5-14B 等的意思就是 Qwen2.5 这个模型的70亿参数版本和140亿参数版本。
而模型蒸馏就是把大参数的模型(称之为教师模型)学到的本领,用“浓缩”的方式教给小参数的模型(称之为学生模型)的过程,让大模型教小模型一些基本的解题思路,即让学生和老师一样思考问题。目的是在保证一定精度的同时,大幅降低运算成本和硬件要求。
所以“本地部署”的模型,由于限制于成本和硬件条件,都是蒸馏模型。而在线“满血”模型才是真正的拥有完整参数的模型,在性能和能力上,蒸馏模型与满血模型存在着一定差距。
二、模型的运行成本真的那么低吗
会有这个误区也是源于对第一个问题的理解不清。对于大多数用户来说,能在普通设备上本地部署并流畅运行是最直接的吸引力,不少人因而认为这代表着原版 DeepSeek-R1 的高效简洁,这显然是不对的。
原版的满血 DeepSeek-R1 的运行和部署成本实际上非常高,要运行这样的系统,需要专门配备的高性能计算集群和专业技术团队,其运营成本堪比大型数据中心,绝非"经济实惠",只是相比较其他的大模型来说,耗费的成本是低的,但依旧不是普通用户和绝大多数企业有能力承担的。而能在普通电脑上运行流畅的“本地部署”版本都是为了能大幅降低运算成本和硬件要求的蒸馏模型。
当然效率提升往往伴随质量下降,虽然本地部署模型不拥有“满血”模型的原本实力,但其真正价值在于"数字资产沉淀",能够进行知识库的私有化构建,满足企业内部的对于智能化的一些定制化使用的需求,且能够保证公司数据的安全性,有效的避免敏感信息外泄。

三、并非一切问题的万能钥匙
首先要强调的是,DeepSeek-R1 仍属于当前人工智能技术发展框架下的强化升级模型,拥有模拟人类思考过程的能力,但这并不意味着它能解决所有难题。很多人会认为 DeepSeek-R1 因为具备强大的通用思维能力,那么其“推理思考”能力就是解决一切问题的万能钥匙,在各个领域上都能大显身手,但实际上在不同的行业不同领域,不同模型表现出来的能力也会有所不同,甚至在垂直领域,专用的即使是小模型也可以达到更好的效果。

四、优质的输入才有优质的输出
关于"无需指导就能理解意图"的说法存在重大误导。要老师给出的优秀答案则需要学生清晰描述问题,同样对于大模型来说,正确及优质的提问才能有优质的回答,提问的质量决定了输出的质量。DeepSeek-R1 这类推理模型对提问方式更是尤为敏感。
对于R1模型,提问方式与之前的模型相比可能有一些微妙的区别,相比较其他模型需要提供范例或步骤的提问方式,R1更适合"直接提问+明确要求"的沟通模式,但要注意不要指导模型做事,添加过多的要求和约束反而会降低回答的质量。而这对用户的沟通技巧提出了更高要求,对用户的“思考质量”也提出了更高的要求,“如何向大模型提问”成为一门需要下功夫研究的学问。
五、行业领先地位的客观认识
虽然 DeepSeek-R1 在逻辑推演等专项领域表现优异,但并不是在所有领域都已达到领先地位,我们需要打破一些盲目崇拜,理性的看待这次由 DeepSeek 引发的浪潮。
DeepSeek 的模型并不具备多模态(图像、音频、视频等)方面的处理能力。比如在处理需要同时理解图文信息的场景时(例如分析带图表的科研论文),DeepSeek 目前还无法与支持多模态的竞争对手比肩。而在超长文本处理方面,行业领头羊已经实现单次处理百万字级的超长文档,相当于能完整解析《战争与和平》这样的鸿篇巨著,这仍是 DeepSeek 需要追赶的目标。
AI 在各个领域各个方面都在飞速的发展,在 DeepSeek 专注优化推理能力得到喜人的成果的同时,其他大模型也在不同的方向进行突破,这些创新都在推动整体行业的边界扩张,每个分支的创新都在为整个体系积累可能性,这种多样性发展对技术进步至关重要。

六、写在最后
DeepSeek-R1 的出现无疑是大模型领域的一项重要进展,其在推理能力上的突出表现为我们带来了新的惊喜和期待。然而在这光环之下我们也更应该客观理性的认识 R1,避免盲目追捧和过度解读,只有这样才能更好地利用这一强大的工具,推动自身业务的发展。
本文来自博客园,作者:knqiufan,转载请注明原文链接:https://www.cnblogs.com/knqiufan/p/18736024


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本