
hive表DDL操作
1)启动 Hive
bin/hive
2)使用 Hive
hive> show databases;
hive> show tables;
hive> create table test (id int);
hive> insert into test values(1);
hive> select * from test;
Hive 常用交互命令
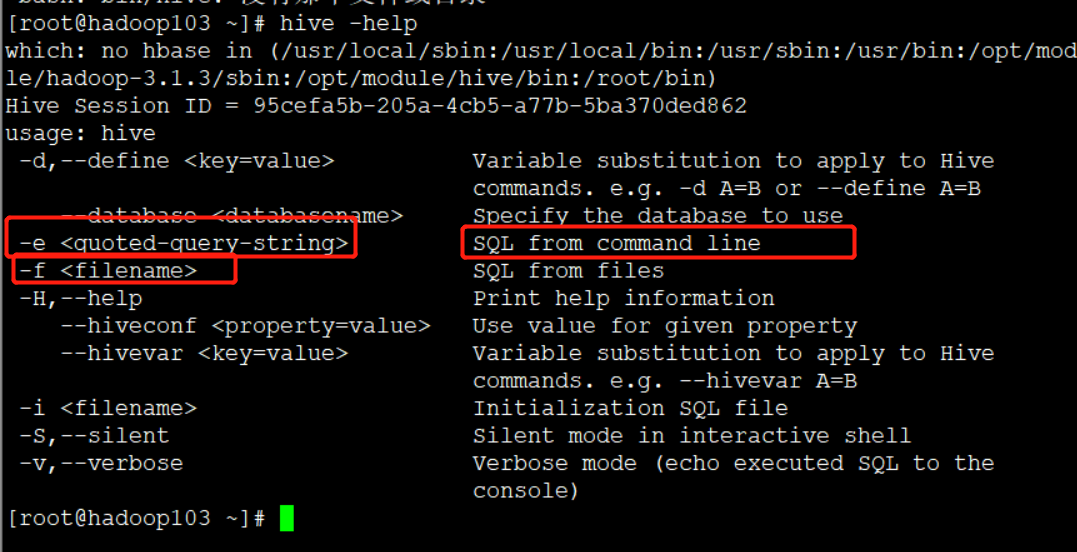
1)“-e”不进入 hive 的交互窗口执行 sql 语句
bin/hive -e "select id from student;"
2)“-f”执行脚本中 sql 语句
(1)在/opt/module/hive/下创建 datas 目录并在 datas 目录下创建 hivef.sql 文件
touch hivef.sql
(2)文件中写入正确的 sql 语句
select *from student;
(3)执行文件中的 sql 语句
bin/hive -f /opt/module/hive/datas/hivef.sql
(4)执行文件中的 sql 语句并将结果写入文件中
bin/hive -f /opt/module/hive/datas/hivef.sql >/opt/module/datas/hive_result.txt
DDL 操作
1. 创建库:
CREATE DATABASE [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES (property_name=property_value, ...)];
方式1:
create database hive1
方式2:
创建一个数据库,指定数据库在 HDFS 上存放的位置
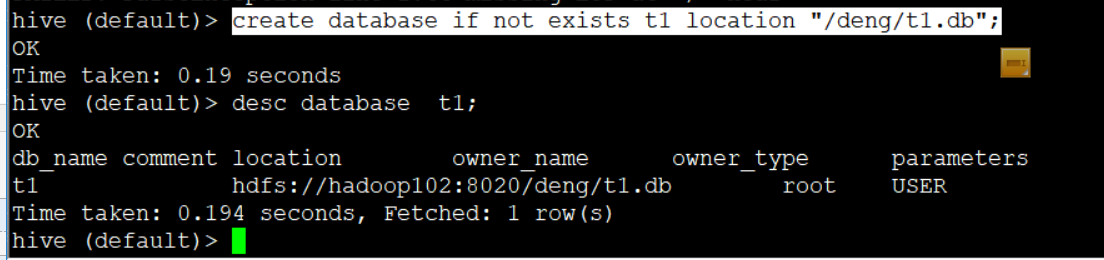
create database if not exists t1 location "/deng/t1.db";
2. 查看存在的数据库
show databases;
show databases like 'db_hive*';
3. 查看某数据库信息
desc database db_name
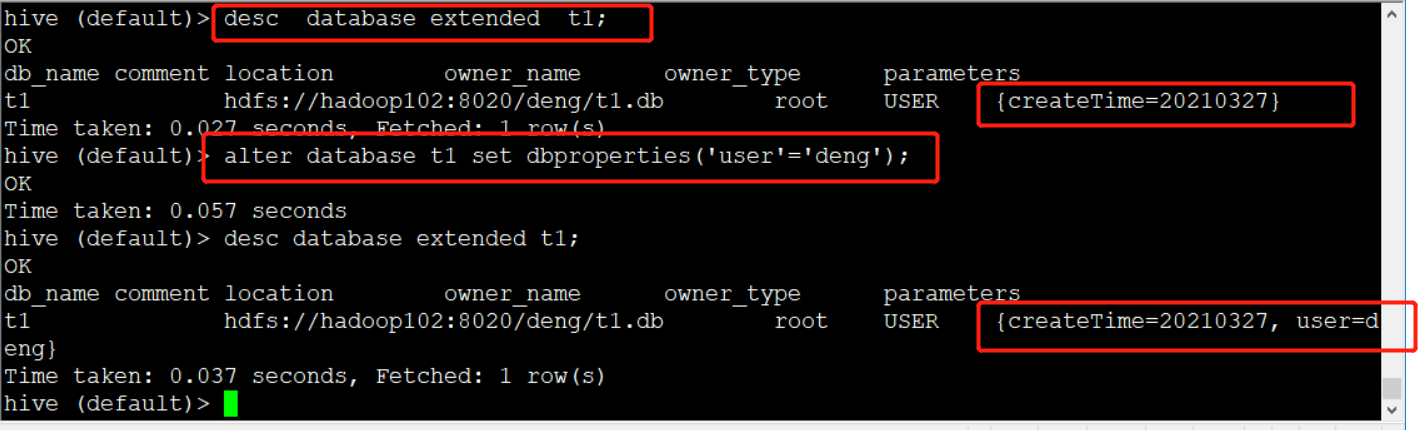
desc database extended db_hive;
修改数据库
alter database t1 set dbproperties('user'='deng');
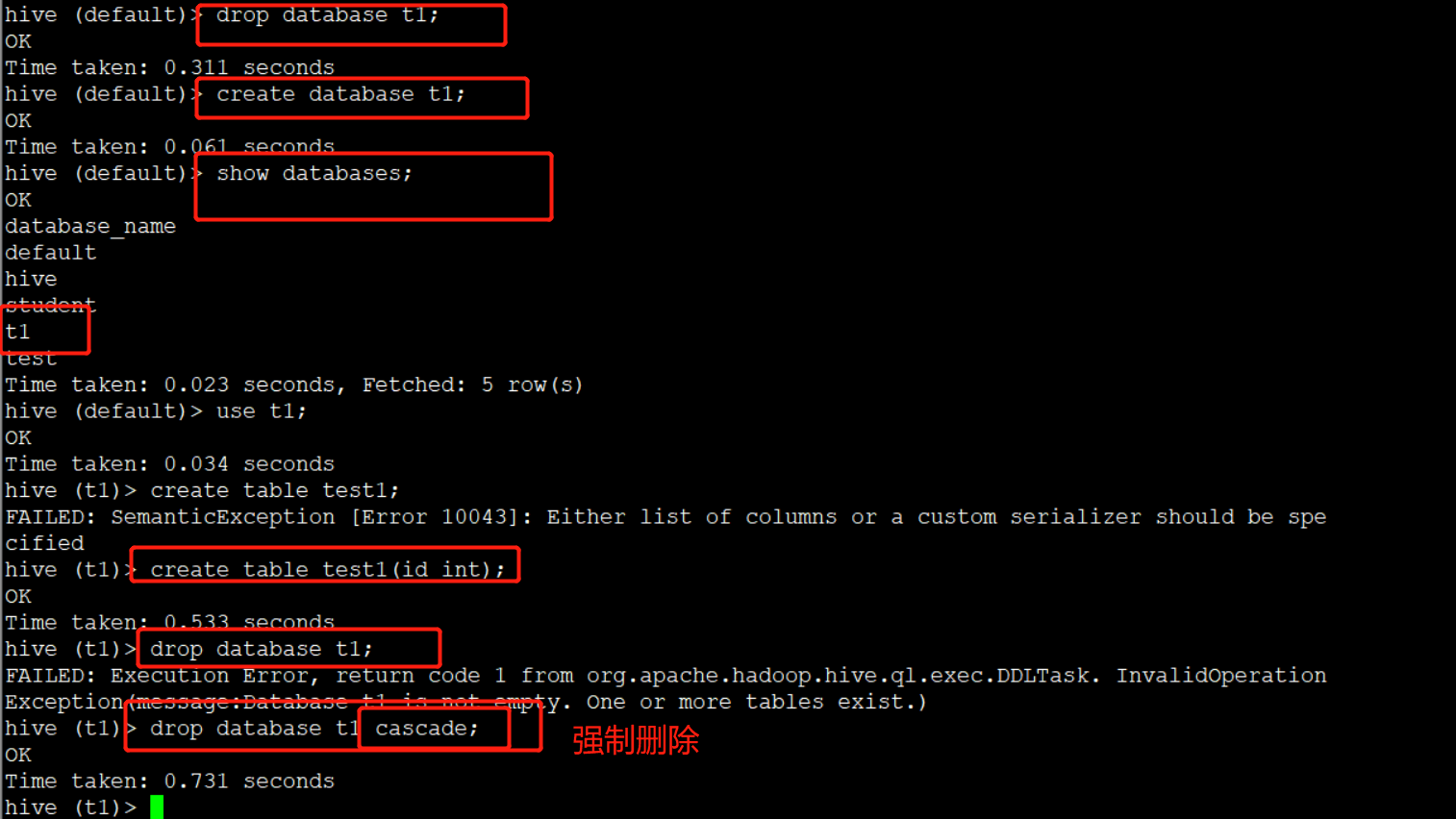
删除库
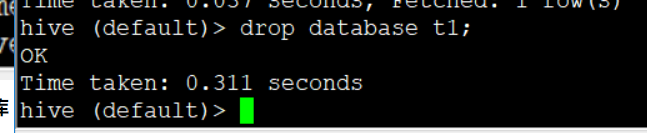
1. drop 删除空库
drop database t1;(数据库有内容时不能删除)
如果数据库不为空,可以采用 cascade 命令,强制删除
drop database t1 cascade;
创建表
建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] [AS select_statement]
字段解释说明
(1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;
用户可以用 IF NOT EXISTS 选项来忽略这个异常。
(2)EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实
际数据的路径(LOCATION),在删除表的时候,内部表的元数据和数据会被一起删除,而外
部表只删除元数据,不删除数据。
(3)COMMENT:为表和列添加注释。
(4)PARTITIONED BY 创建分区表
(5)CLUSTERED BY 创建分桶表
(6)SORTED BY 不常用,对桶中的一个或多个列另外排序
(7)ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value,
property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW
FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需
要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表
的具体的列的数据。
SerDe 是 Serialize/Deserilize 的简称, hive 使用 Serde 进行行对象的序列与反序列化。
(8)STORED AS 指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列
式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED
AS SEQUENCEFILE。
(9)LOCATION :指定表在 HDFS 上的存储位置。
(10)AS:后跟查询语句,根据查询结果创建表。
(11)LIKE 允许用户复制现有的表结构,但是不复制数据。
内部表(管理表)和外部表
内部表: 删除表时,元数据和hdfs 数据都会删除。
外部表:删除表时,只删除元数据,不删除hdfs 数据
1.中间表和临时表,一般用内部表
2. 生产环境一般用外部表
每天将收集到的网站日志定期流入 HDFS 文本文件。在外部表(原始日志表)的基础上
做大量的统计分析,用到的中间表、结果表使用内部表存储,数据通过 SELECT+INSERT 进入内部表。
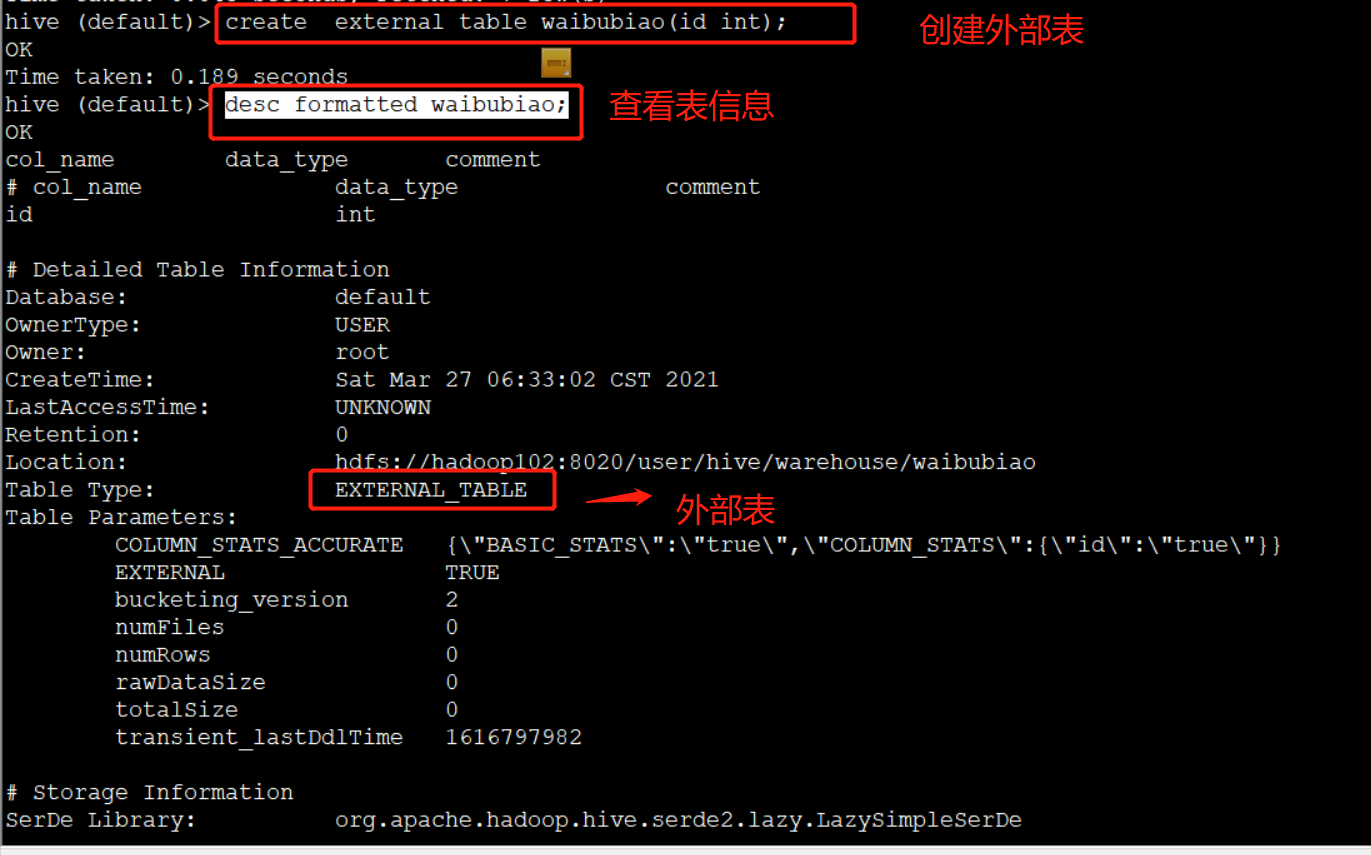
创建外部表
create external table waibubiao(id int);
查看表信息:
desc formatted waibubiao;
普通创建表
1.原数据
1001 ss1 1002 ss2 1003 ss3 1004 ss4 1005 ss5 1006 ss6 1007 ss7
创建表
先将数据存放在hdfs文件:
/user/hive/warehouse/student
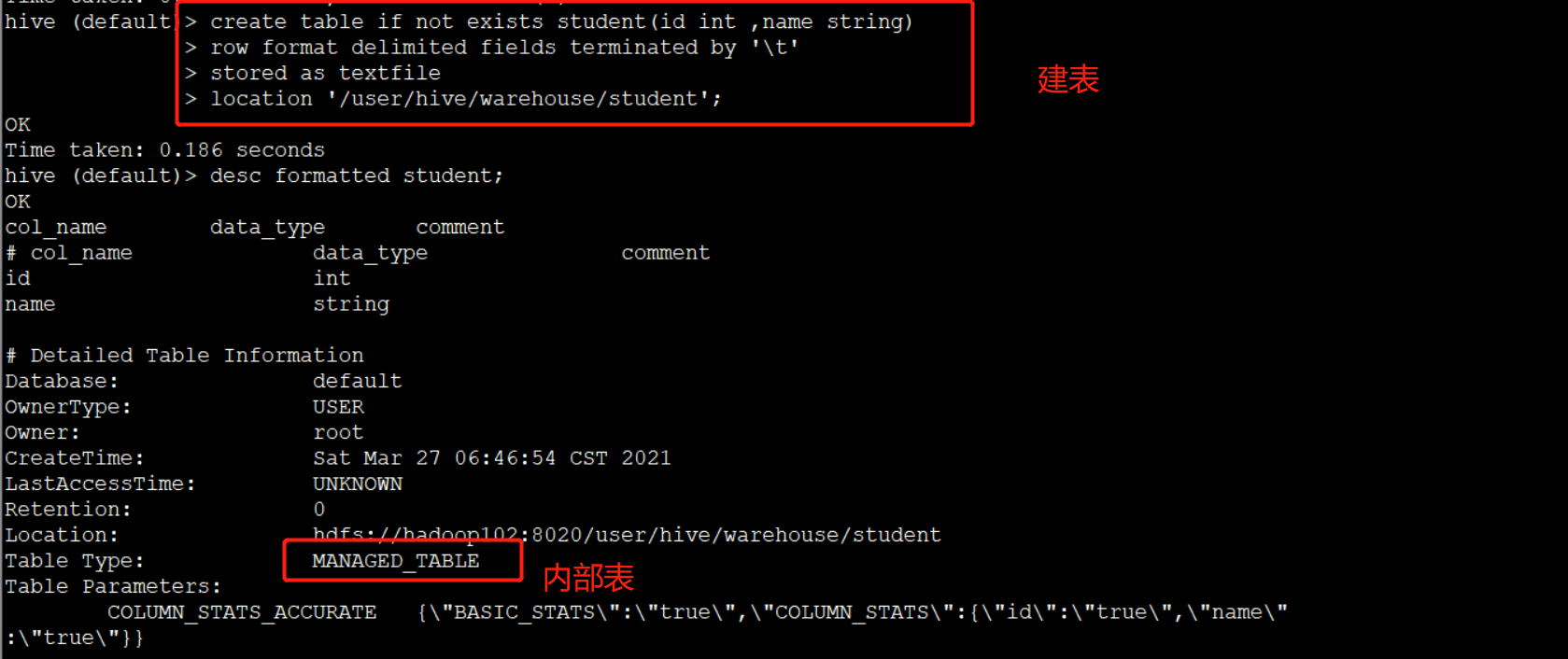
创建表:
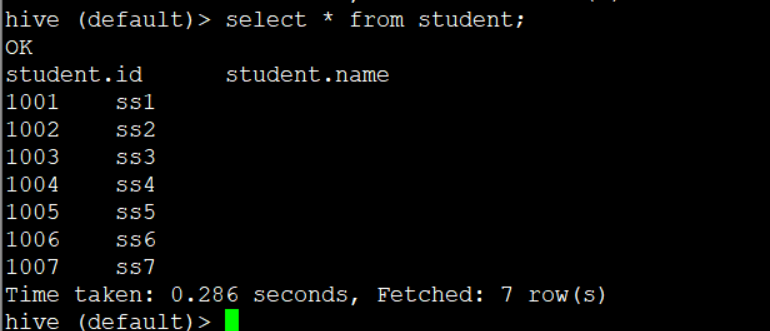
create table if not exists student( id int, name string ) row format delimited fields terminated by '\t' stored as textfile location '/user/hive/warehouse/student';
(1)普通创建表
create table if not exists student( id int, name string ) row format delimited fields terminated by '\t' stored as textfile location '/user/hive/warehouse/student';
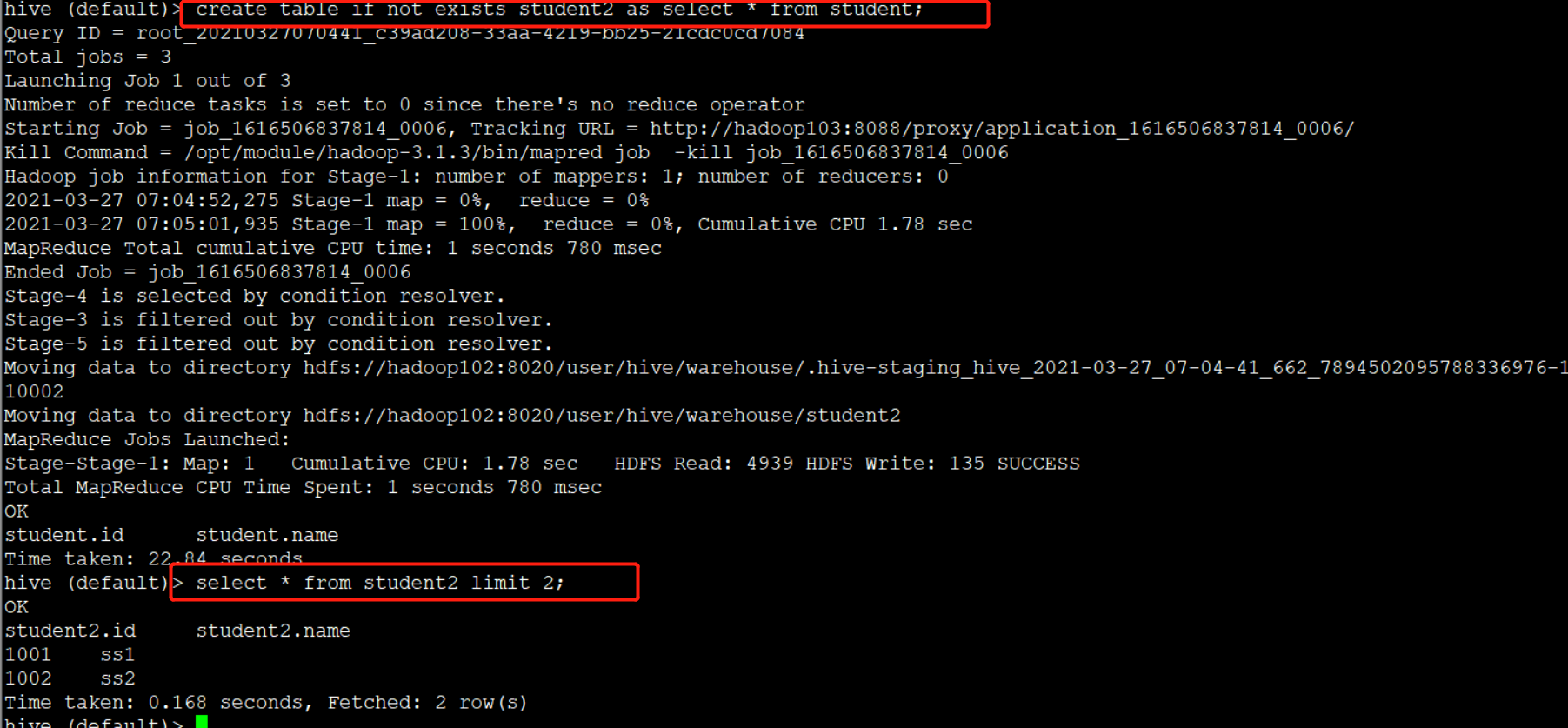
(2)根据查询结果创建表(查询的结果会添加到新创建的表中)
走mr
create table if not exists student2 as select id, name from student;
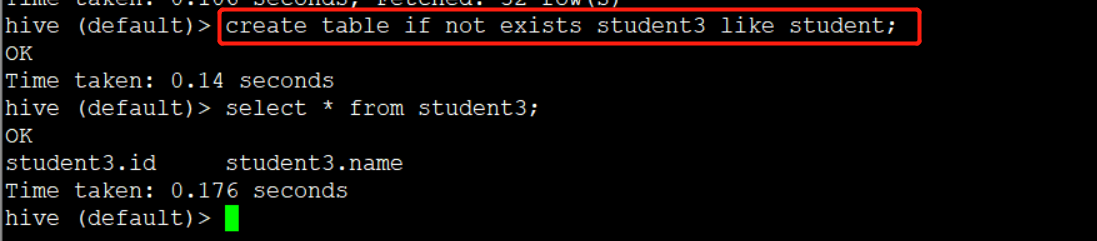
(3)根据已经存在的表结构创建表
create table if not exists student3 like student;
(4)查询表的类型
desc formatted student2;
管理表与外部表的互相转换
(1)查询表的类型
desc formatted student2;
Table Type: MANAGED_TABLE
(2)修改内部表 student2 为外部表
alter table student2 set tblproperties('EXTERNAL'='TRUE');
(3)查询表的类型
desc formatted student2;
Table Type: EXTERNAL_TABLE
(4)修改外部表 student2 为内部表
alter table student2 set tblproperties('EXTERNAL'='FALSE');
(5)查询表的类型
desc formatted student2;
Table Type: MANAGED_TABLE
注意:('EXTERNAL'='TRUE')和('EXTERNAL'='FALSE')为固定写法,区分大小写!
修改表
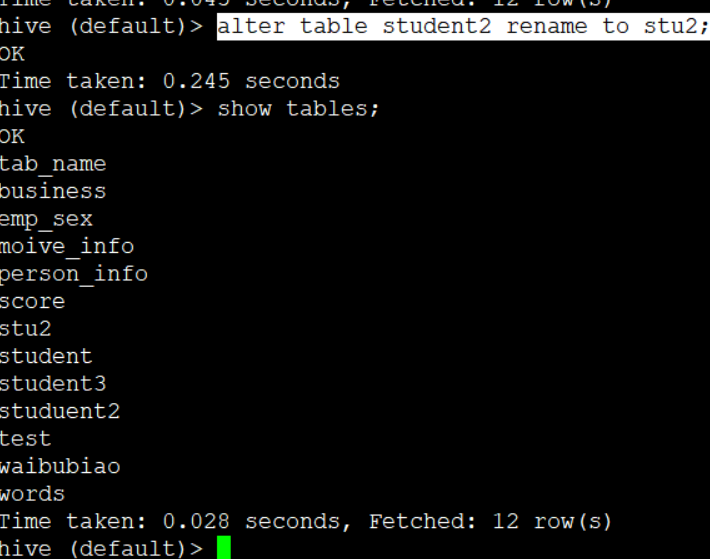
1.修改表名
alter table student2 rename to stu2;
增加/修改/替换列信息1)语法
(1)更新列
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name
column_type [COMMENT col_comment] [FIRST|AFTER column_name]
(2)增加和替换列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT
col_comment], ...)
注:ADD 是代表新增一字段,字段位置在所有列后面(partition 列前),
REPLACE 则是表示替换表中所有字段。
2)实操案例
(1)查询表结构
desc dept;
(2)添加列
alter table dept add columns(deptdesc string);
(3)查询表结构
desc dept;
(4)更新列
alter table dept change column deptdesc desc string;
(5)查询表结构
desc dept;
(6)替换列
alter table dept replace columns(deptno string, dname string, loc string);
(7)查询表结构
desc dept;
4.7 删除表
drop table dept
有疑问可以加wx:18179641802,进行探讨

 浙公网安备 33010602011771号
浙公网安备 33010602011771号