
scrapyd的安装和scrapyd-client
1.创建虚拟环境 ,虚拟环境名为sd

mkvirtualenv sd #方便管理
2. 安装 scrapyd
pip3 install scrapyd
3. 配置
mkdir /etc/scrapyd
vim /etc/scrapyd/scrapyd.conf

写入一下配置
参考官网:https://scrapyd.readthedocs.io/en/stable/config.html#config
[scrapyd] eggs_dir = eggs logs_dir = logs items_dir = jobs_to_keep = 5 dbs_dir = dbs max_proc = 0 max_proc_per_cpu = 4 finished_to_keep = 100 poll_interval = 5.0 #bind_address = 127.0.0.1 bind_address = 0.0.0.0 http_port = 6800 debug = off runner = scrapyd.runner application = scrapyd.app.application launcher = scrapyd.launcher.Launcher webroot = scrapyd.website.Root [services] schedule.json = scrapyd.webservice.Schedule cancel.json = scrapyd.webservice.Cancel addversion.json = scrapyd.webservice.AddVersion listprojects.json = scrapyd.webservice.ListProjects listversions.json = scrapyd.webservice.ListVersions listspiders.json = scrapyd.webservice.ListSpiders delproject.json = scrapyd.webservice.DeleteProject delversion.json = scrapyd.webservice.DeleteVersion listjobs.json = scrapyd.webservice.ListJobs daemonstatus.json = scrapyd.webservice.DaemonStatus
bind_address:默认是本地127.0.0.1,修改为0.0.0.0,可以让外网访问。


一. 部署&运行 deploy: 部署scrapy爬虫程序 # scrapyd-deploy 部署服务器名 -p 项目名称 scrapyd-deploy ubuntu -p douyu run : 运行 #curl http://localhost:6800/schedule.json -d project=project_name -d spider=spider_name curl http://127.0.0.1:6800/schedule.json -d project=douyu -d spider=dy stop: 停止 #curl http://localhost:6800/cancel.json -d project=project_name -d job=jobid curl http://127.0.0.1:6800/cancel.json -d project=douyu -d job=$1 二. 允许外部访问配置 定位配置文件: default_scrapyd.conf find /home/wg -name default_scrapyd.conf cd /home/wg/scrapy_env/lib/python3.6/site-packages/scrapyd 允许外部访问: vim default_scrapyd.conf bind_address = 0.0.0.0 三. 远程监控-url指令: 1、获取状态 http://127.0.0.1:6800/daemonstatus.json 2、获取项目列表 http://127.0.0.1:6800/listprojects.json 3、获取项目下已发布的爬虫列表 http://127.0.0.1:6800/listspiders.json?project=myproject 4、获取项目下已发布的爬虫版本列表 http://127.0.0.1:6800/listversions.json?project=myproject 5、获取爬虫运行状态 http://127.0.0.1:6800/listjobs.json?project=myproject 6、启动服务器上某一爬虫(必须是已发布到服务器的爬虫) http://127.0.0.1:6800/schedule.json (post方式,data={"project":myproject,"spider":myspider}) 7、删除某一版本爬虫 http://127.0.0.1:6800/delversion.json (post方式,data={"project":myproject,"version":myversion}) 8、删除某一工程,包括该工程下的各版本爬虫 http://127.0.0.1:6800/delproject.json(post方式,data={"project":myproject}) 四. 常用脚本 循环任务: while true do curl http://127.0.0.1:6800/schedule.json -d project=FXH -d spider=five_sec_info sleep 10 done 实时时间打印: echo "$(date +%Y-%m-%d:%H:%M.%S), xx-spider定时启动--"
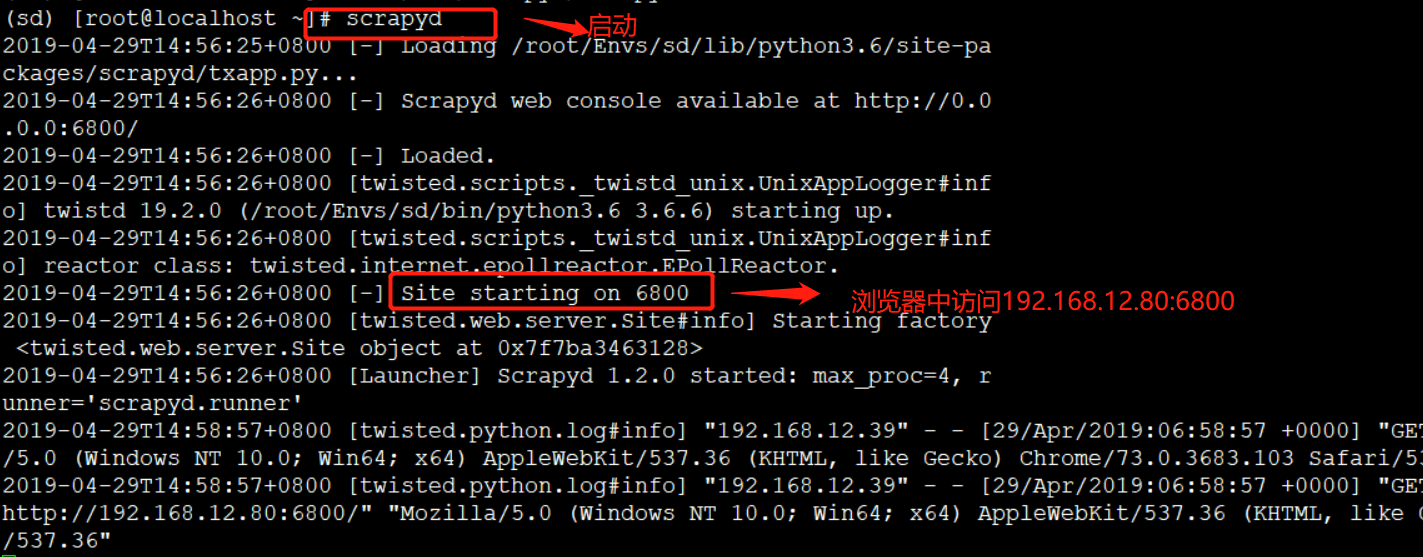
启动:
scrapyd
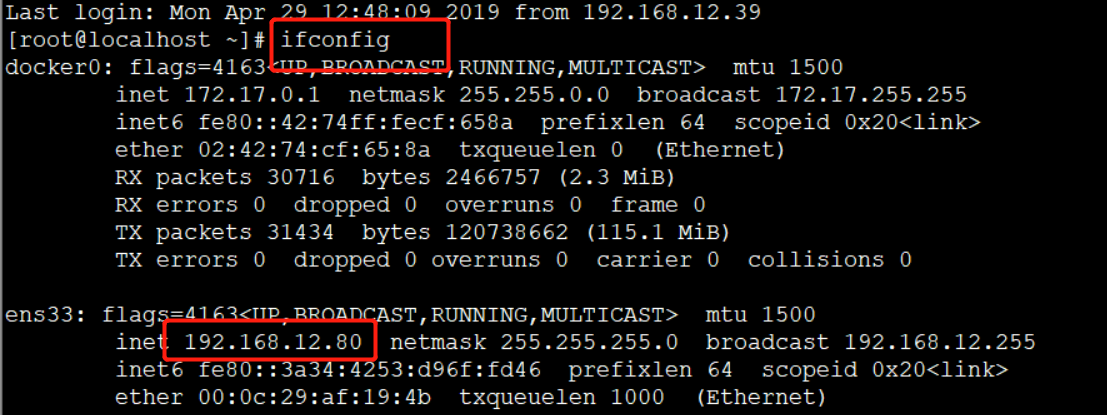
查看本机ip:
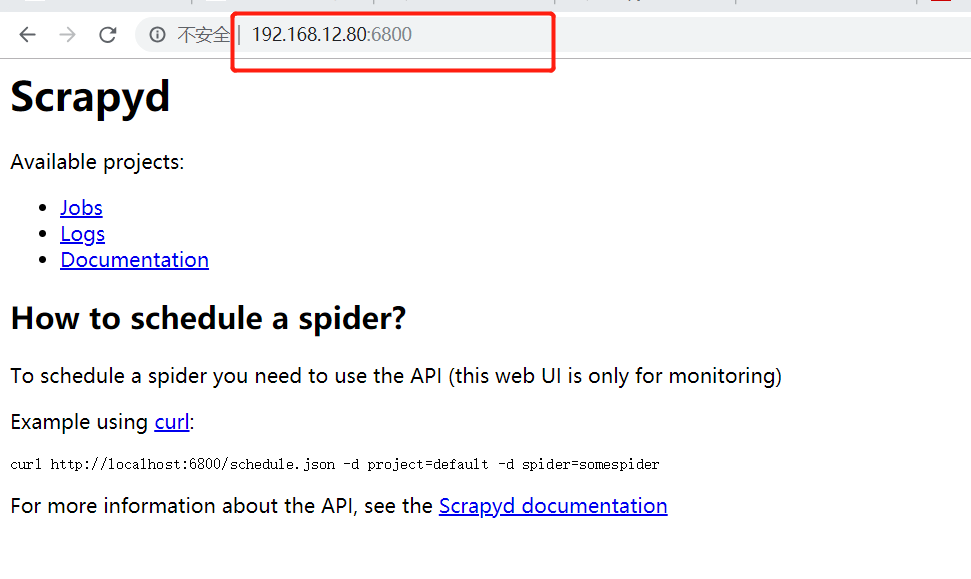
浏览器中访问:
192.168.12.80:6800
scrapyd-client 及部署
1. 安装scrapyd-client
pip3 install scrapyd-client
2.
安装成功后会有一个可用命令,叫作scrapyd-deploy,即部署命令。
我们可以输入如下测试命令测试Scrapyd-Client是否安装成功:
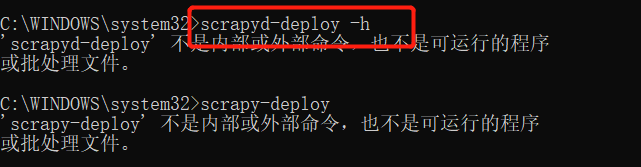
3. crapyd-deploy 不是内部命令,所以需要进行项目配置
windows下的scrapyd-deploy无法运行的解决办法
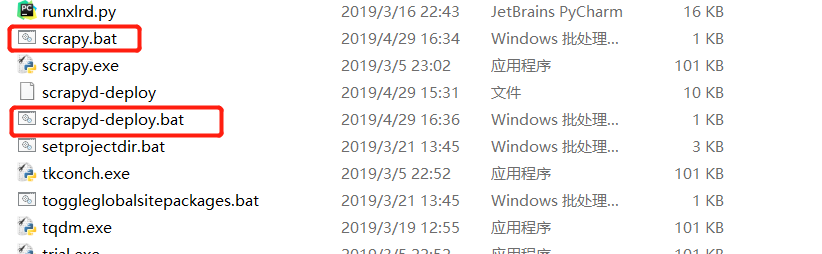
.进到c:/python/Scripts 目录下,创建两个新文件:
scrapy.bat
scrapyd-deploy.bat

编辑两个文件:
scrapy.bat文件中输入以下内容 :
@echo off "C:\Python36" "C:\Python36\Scripts\scrapy" %*
scrapyd-deploy.bat 文件中输入以下内容:
@echo off "C:\Python36\python" "C:\Python36\Scripts\scrapyd-deploy" %*
4.再次查看
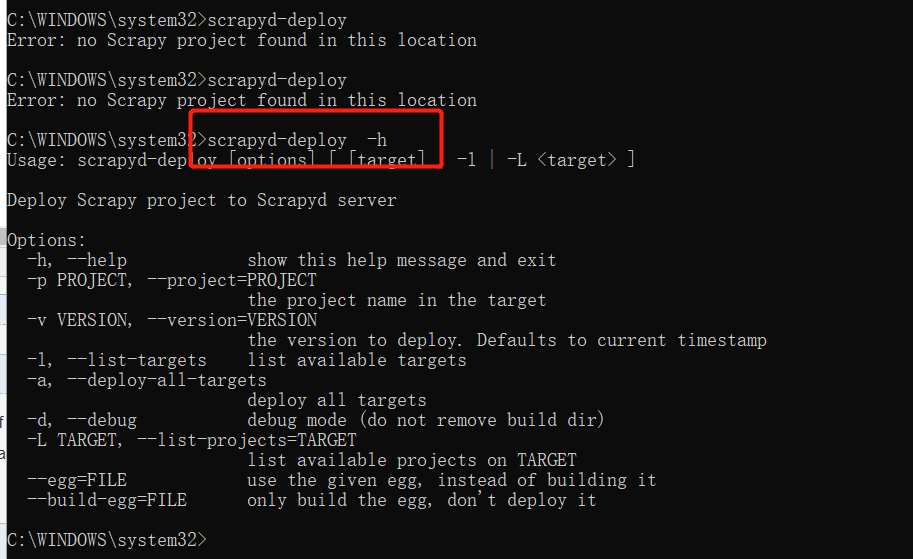
可以了。
有疑问可以加wx:18179641802,进行探讨

 浙公网安备 33010602011771号
浙公网安备 33010602011771号