
scrapy数据存储在mysql数据库的两种方式
方法一:同步操作
1.pipelines.py文件(处理数据的python文件)
import pymysql class LvyouPipeline(object): def __init__(self): # connection database self.connect = pymysql.connect(host='XXX', user='root', passwd='XXX', db='scrapy_test') # 后面三个依次是数据库连接名、数据库密码、数据库名称 # get cursor self.cursor = self.connect.cursor() print("连接数据库成功") def process_item(self, item, spider): # sql语句 insert_sql = """ insert into lvyou(name1, address, grade, score, price) VALUES (%s,%s,%s,%s,%s) """ # 执行插入数据到数据库操作 self.cursor.execute(insert_sql, (item['Name'], item['Address'], item['Grade'], item['Score'], item['Price'])) # 提交,不进行提交无法保存到数据库 self.connect.commit() def close_spider(self, spider): # 关闭游标和连接 self.cursor.close() self.connect.close()
2.配置文件中
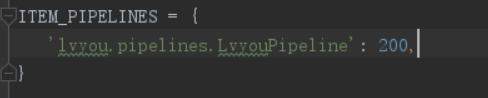
方式二 异步储存
pipelines.py文件:
通过twisted实现数据库异步插入,twisted模块提供了 twisted.enterprise.adbapi
1. 导入adbapi
2. 生成数据库连接池
3. 执行数据数据库插入操作
4. 打印错误信息,并排错
import pymysql from twisted.enterprise import adbapi # 异步更新操作 class LvyouPipeline(object): def __init__(self, dbpool): self.dbpool = dbpool @classmethod def from_settings(cls, settings): # 函数名固定,会被scrapy调用,直接可用settings的值 """ 数据库建立连接 :param settings: 配置参数 :return: 实例化参数 """ adbparams = dict( host=settings['MYSQL_HOST'], db=settings['MYSQL_DBNAME'], user=settings['MYSQL_USER'], password=settings['MYSQL_PASSWORD'], cursorclass=pymysql.cursors.DictCursor # 指定cursor类型 ) # 连接数据池ConnectionPool,使用pymysql或者Mysqldb连接 dbpool = adbapi.ConnectionPool('pymysql', **adbparams) # 返回实例化参数 return cls(dbpool) def process_item(self, item, spider): """ 使用twisted将MySQL插入变成异步执行。通过连接池执行具体的sql操作,返回一个对象 """ query = self.dbpool.runInteraction(self.do_insert, item) # 指定操作方法和操作数据 # 添加异常处理 query.addCallback(self.handle_error) # 处理异常 def do_insert(self, cursor, item): # 对数据库进行插入操作,并不需要commit,twisted会自动commit insert_sql = """ insert into lvyou(name1, address, grade, score, price) VALUES (%s,%s,%s,%s,%s) """ self.cursor.execute(insert_sql, (item['Name'], item['Address'], item['Grade'], item['Score'], item['Price'])) def handle_error(self, failure): if failure: # 打印错误信息 print(failure)
注意:
1、python 3.x 不再支持MySQLdb,它在py3的替代品是: import pymysql。
2、报错pymysql.err.ProgrammingError: (1064, ……
原因:当item['quotes']里面含有引号时,可能会报上述错误
解决办法:使用pymysql.escape_string()方法
例如:
sql = """INSERT INTO video_info(video_id, title) VALUES("%s","%s")""" % (video_info["id"],pymysql.escape_string(video_info["title"]))
3、存在中文的时候,连接需要添加charset='utf8',否则中文显示乱码。
4、每执行一次爬虫,就会将数据追加到数据库中,如果多次的测试爬虫,就会导致相同的数据不断累积,怎么实现增量爬取?
scrapy-deltafetch
scrapy-crawl-once(与1不同的是存储的数据库不同)
scrapy-redis
scrapy-redis-bloomfilter(3的增强版,存储更多的url,查询更快)
原文:https://blog.csdn.net/weixin_40096730/article/details/87863797
有疑问可以加wx:18179641802,进行探讨

 浙公网安备 33010602011771号
浙公网安备 33010602011771号