
scrapy 中crawlspider 爬虫
爬取目标网站:
http://www.chinanews.com/rss/rss_2.html
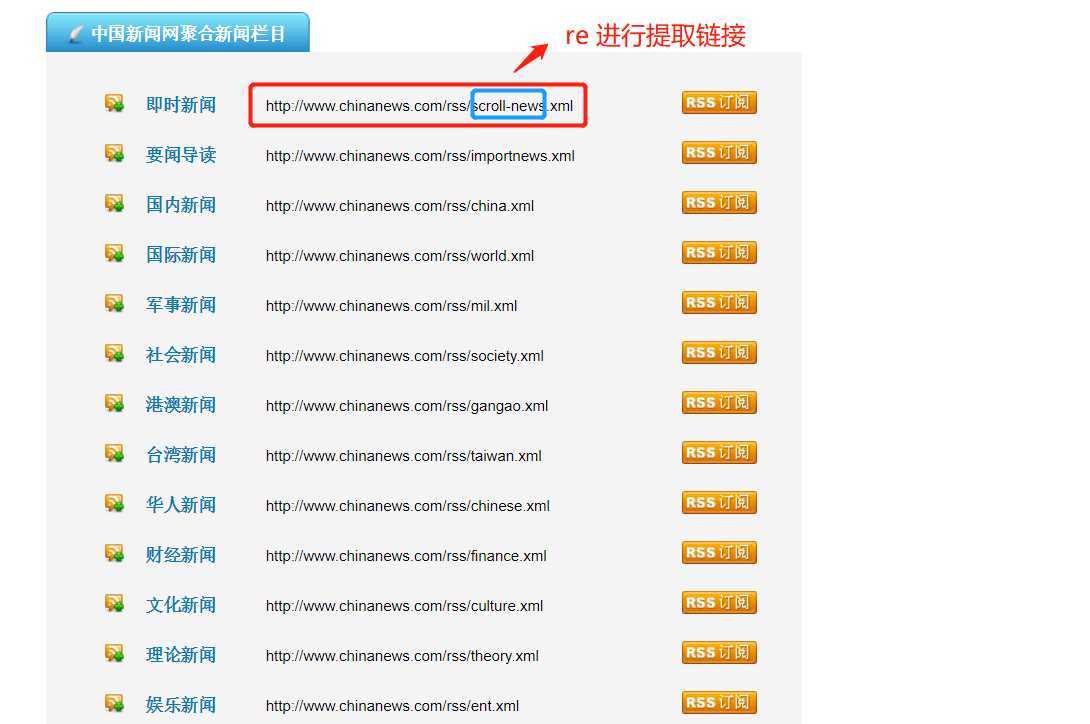
获取url后进入另一个页面进行数据提取

检查网页:
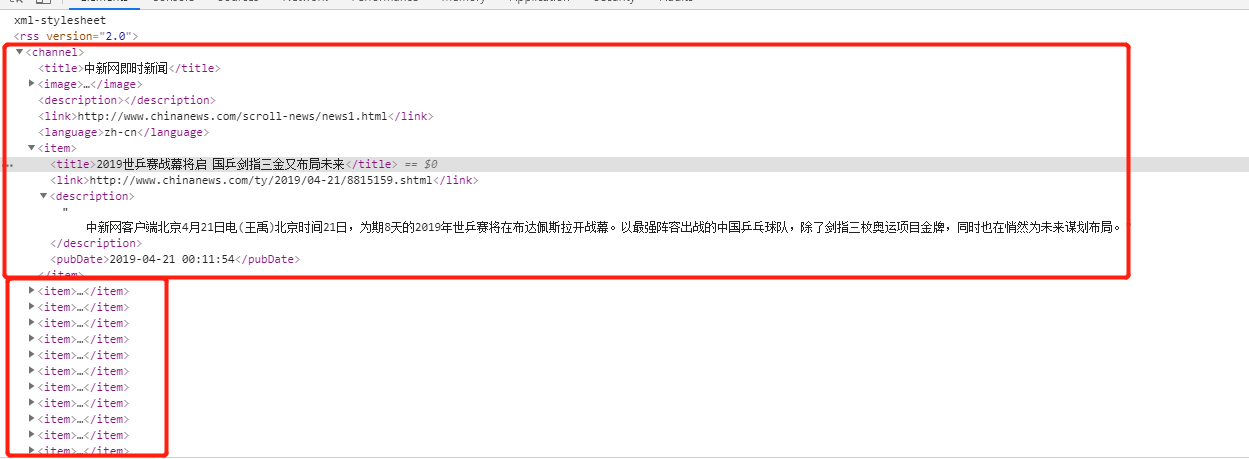
爬虫该页数据的逻辑:
Crawlspider爬虫类:
# -*- coding: utf-8 -*- import scrapy import re #from scrapy import Selector from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class NwSpider(CrawlSpider): name = 'nw' # allowed_domains = ['www.new.com'] start_urls = ['http://www.chinanews.com/rss/rss_2.html'] rules = (
Rule(LinkExtractor(allow='http://www.chinanews.com/rss/.*?\.xml'), callback='parse_item'), ) def parse_item(self, response): selector = Selector(response) items =response.xpath('//item').extract() for node in items: # print(type(node)) # item = {} item['title'] = re.findall(r'<title>(.*?)</title>',node,re.S)[0] item['link'] = re.findall(r'<link>(.*?)</link>',node,re.S)[0] item['desc'] = re.findall(r'<description>(.*?)</description>',node,re.S)[0] item['pub_date'] =re.findall(r'<pubDate>(.*?)</pubDate>',node,re.S)[0] print(item) #item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get() #item['name'] = response.xpath('//div[@id="name"]').get() #item['description'] = response.xpath('//div[@id="description"]').get() # yield item
有疑问可以加wx:18179641802,进行探讨

 浙公网安备 33010602011771号
浙公网安备 33010602011771号