
scrapy中的CSVFeedSpider
目标网站:
http://beijingair.sinaapp.com/
目标文件的格式:
此处以爬取一个文件内容为例:
http://beijingair.sinaapp.com/data/beijing/all/20131205/csv
爬取更多 文件 :
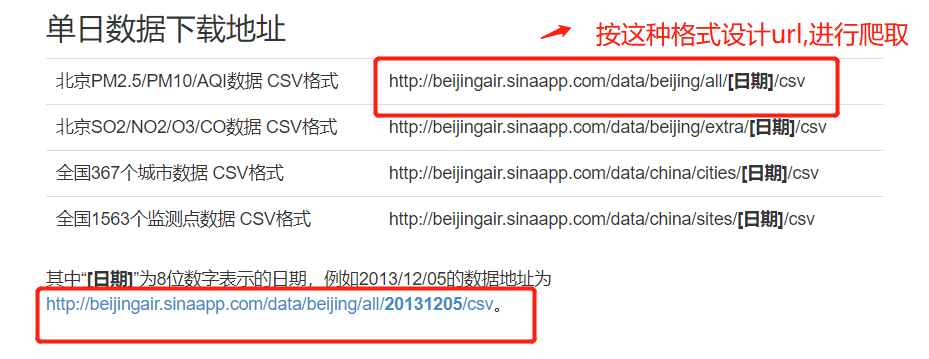
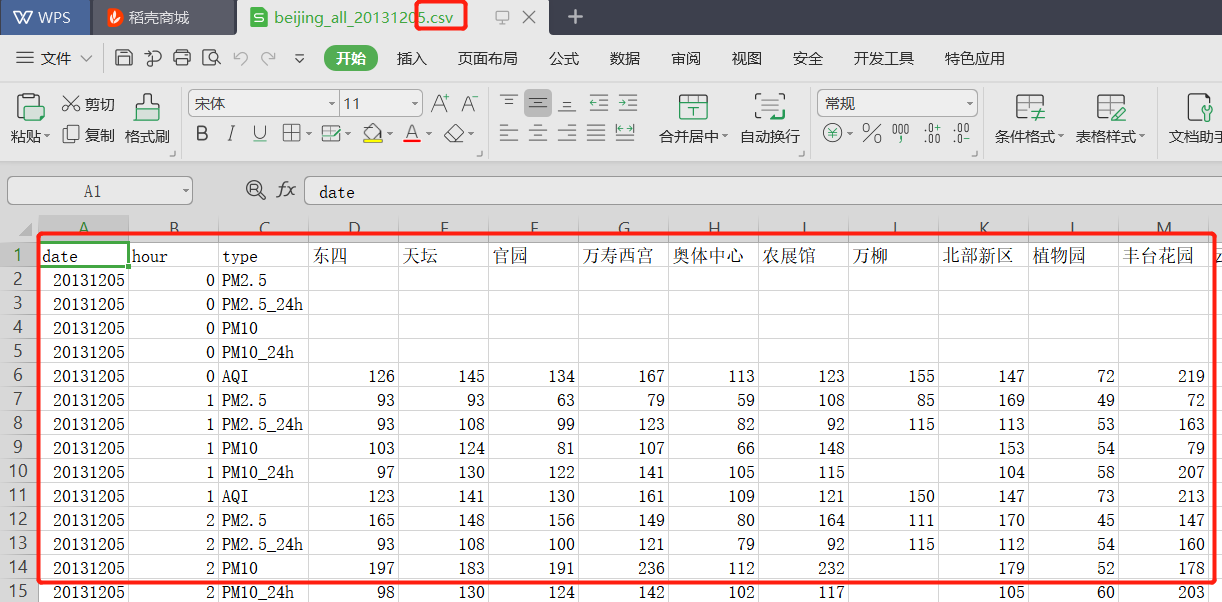
文件中的数据格式:
1.创建项目:
scrapy startproject CSVpro
2.创建爬虫后的初始化spider类:
scrapy genspider -t xmlfeed cnew chinanews.com
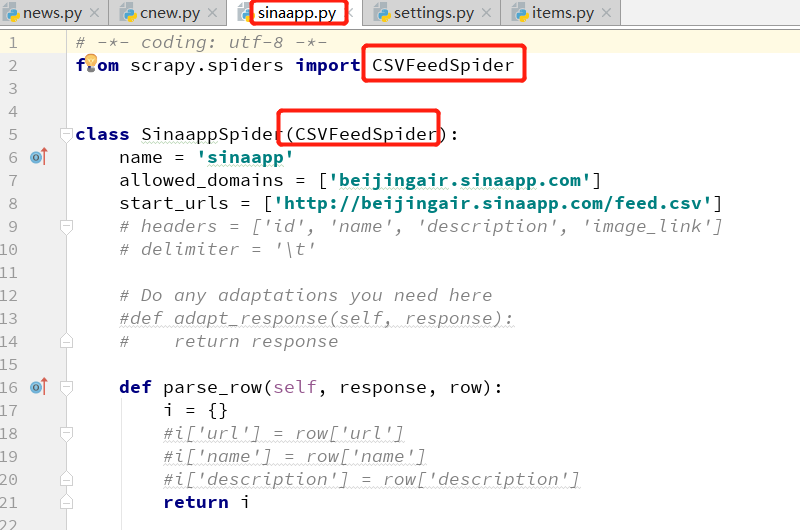
把start_url改为: http://beijingair.sinaapp.com/data/beijing/all/20131205/csv
start_url 可以装很多的目标url
# -*- coding: utf-8 -*- from scrapy.spiders import CSVFeedSpider class SinaappSpider(CSVFeedSpider): name = 'sinaapp' # allowed_domains = ['beijingair.sinaapp.com'] start_urls = [' http://beijingair.sinaapp.com/data/beijing/all/20131205/csv'] # start_urls = [' http://yum.iqianyue.com/weisuenbook/pyspd/part12/mydata.csv'] # headers = ['id', 'name', 'description', 'image_link'] # delimiter = '\t' # Do any adaptations you need here #def adapt_response(self, response): # return response # delimiter:主要存放字段之间的间隔符 delimiter = ',' # 表头信息 headers = ['date','type','hour'] def parse_row(self, response, row): i = {} #i['url'] = row['url'] #i['name'] = row['name'] #i['description'] = row['description'] i['date'] = row['date'] i['type'] = row['type'] i['hour'] =row['hour'] print(i) return i
有疑问可以加wx:18179641802,进行探讨

 浙公网安备 33010602011771号
浙公网安备 33010602011771号