
scrapy-Redis 分布式爬虫
案例1 :(增量式爬取)京东全部图书,自己可以扩展 爬取每一本电子书的评论
1.spider:


# -*- coding: utf-8 -*- import scrapy from copy import deepcopy import json import urllib class JdSpider(scrapy.Spider): name = 'jd' allowed_domains = ['jd.com','p.3.cn'] start_urls = ['https://book.jd.com/booksort.html'] def parse(self, response): dt_list = response.xpath("//div[@class='mc']/dl/dt") #大分类列表 for dt in dt_list: item = {} item["b_cate"] = dt.xpath("./a/text()").extract_first() em_list = dt.xpath("./following-sibling::dd[1]/em") #小分类列表 for em in em_list: item["s_href"] = em.xpath("./a/@href").extract_first() item["s_cate"] = em.xpath("./a/text()").extract_first() if item["s_href"] is not None: item["s_href"] = "https:" + item["s_href"] yield scrapy.Request( item["s_href"], callback=self.parse_book_list, meta = {"item":deepcopy(item)} ) def parse_book_list(self,response): #解析列表页 item = response.meta["item"] li_list = response.xpath("//div[@id='plist']/ul/li") for li in li_list: item["book_img"] = li.xpath(".//div[@class='p-img']//img/@src").extract_first() if item["book_img"] is None: item["book_img"] = li.xpath(".//div[@class='p-img']//img/@data-lazy-img").extract_first() item["book_img"]="https:"+item["book_img"] if item["book_img"] is not None else None item["book_name"] = li.xpath(".//div[@class='p-name']/a/em/text()").extract_first().strip() item["book_author"] = li.xpath(".//span[@class='author_type_1']/a/text()").extract() item["book_press"]= li.xpath(".//span[@class='p-bi-store']/a/@title").extract_first() item["book_publish_date"] = li.xpath(".//span[@class='p-bi-date']/text()").extract_first().strip() item["book_sku"] = li.xpath("./div/@data-sku").extract_first() yield scrapy.Request( "https://p.3.cn/prices/mgets?skuIds=J_{}".format(item["book_sku"]), callback=self.parse_book_price, meta = {"item":deepcopy(item)} ) #列表页翻页 next_url = response.xpath("//a[@class='pn-next']/@href").extract_first() if next_url is not None: next_url = urllib.parse.urljoin(response.url,next_url) yield scrapy.Request( next_url, callback=self.parse_book_list, meta = {"item":item} ) def parse_book_price(self,response): item = response.meta["item"] item["book_price"] = json.loads(response.body.decode())[0]["op"] print(item)
2. 配置文件
# 增加配置
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" SCHEDULER = "scrapy_redis.scheduler.Scheduler" SCHEDULER_PERSIST = True REDIS_URL = "redis://127.0.0.1:6379" # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = False
案例2:分布式爬取当当图书
1.scrapy 配置settings.py中
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" SCHEDULER = "scrapy_redis.scheduler.Scheduler" SCHEDULER_PERSIST = True REDIS_URL = "redis://127.0.0.1:6379" # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = False
2. 当当爬虫文件 spider.py 文件中:
# -*- coding: utf-8 -*- import scrapy from scrapy_redis.spiders import RedisSpider from copy import deepcopy import urllib class DangdangSpider(RedisSpider): name = 'dangdang' allowed_domains = ['dangdang.com'] # start_urls = ['http://book.dangdang.com/']# 不在写start_url地址,如果写了就会重复每台电脑就会重复爬取该地址 # 在redis中 先存start_url 地址 :lpush dangdang http://book.dangdang.com/ redis_key = "dangdang" def parse(self, response): #大分类分组 div_list = response.xpath("//div[@class='con flq_body']/div") for div in div_list: item = {} item["b_cate"] = div.xpath("./dl/dt//text()").extract() item["b_cate"] = [i.strip() for i in item["b_cate"] if len(i.strip())>0] #中间分类分组 dl_list = div.xpath("./div//dl[@class='inner_dl']") for dl in dl_list: item["m_cate"] = dl.xpath("./dt//text()").extract() item["m_cate"] = [i.strip() for i in item["m_cate"] if len(i.strip())>0][0] #小分类分组 a_list = dl.xpath("./dd/a") for a in a_list: item["s_href"] = a.xpath("./@href").extract_first() item["s_cate"] = a.xpath("./text()").extract_first() if item["s_href"] is not None: yield scrapy.Request( item["s_href"], callback=self.parse_book_list, meta = {"item":deepcopy(item)} ) def parse_book_list(self,response): item = response.meta["item"] li_list = response.xpath("//ul[@class='bigimg']/li") for li in li_list: item["book_img"] = li.xpath("./a[@class='pic']/img/@src").extract_first() if item["book_img"] == "images/model/guan/url_none.png": item["book_img"] = li.xpath("./a[@class='pic']/img/@data-original").extract_first() item["book_name"] = li.xpath("./p[@class='name']/a/@title").extract_first() item["book_desc"] = li.xpath("./p[@class='detail']/text()").extract_first() item["book_price"] = li.xpath(".//span[@class='search_now_price']/text()").extract_first() item["book_author"] = li.xpath("./p[@class='search_book_author']/span[1]/a/text()").extract() item["book_publish_date"] = li.xpath("./p[@class='search_book_author']/span[2]/text()").extract_first() item["book_press"] = li.xpath("./p[@class='search_book_author']/span[3]/a/text()").extract_first() print(item) #下一页 next_url = response.xpath("//li[@class='next']/a/@href").extract_first() if next_url is not None: next_url = urllib.parse.urljoin(response.url,next_url) yield scrapy.Request( next_url, callback=self.parse_book_list, meta = {"item":item} )
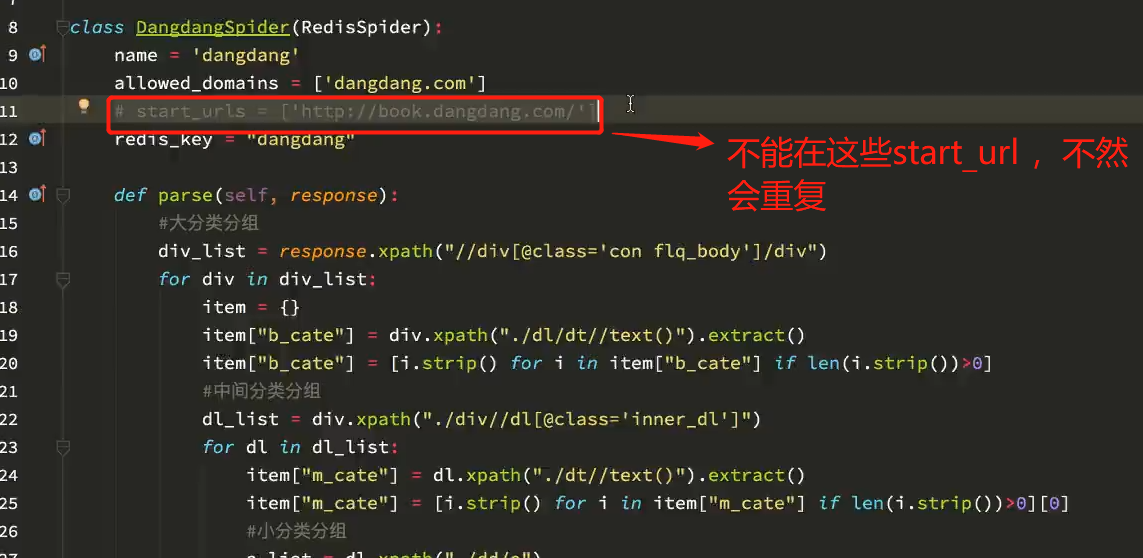
redis数据库操作

案例3 : 使用RedisCrawlSpider 自动提取url地址,并可以实现分布式
amazon 爬取亚马逊电子书
1. 创建amazon 爬虫命令:
scrapy genspdier -t crawl amazon amazon.com # 创建 crawlSpdier 爬虫

2.对crawlSpider 爬虫进行修改为 RedisCrawlSpdier
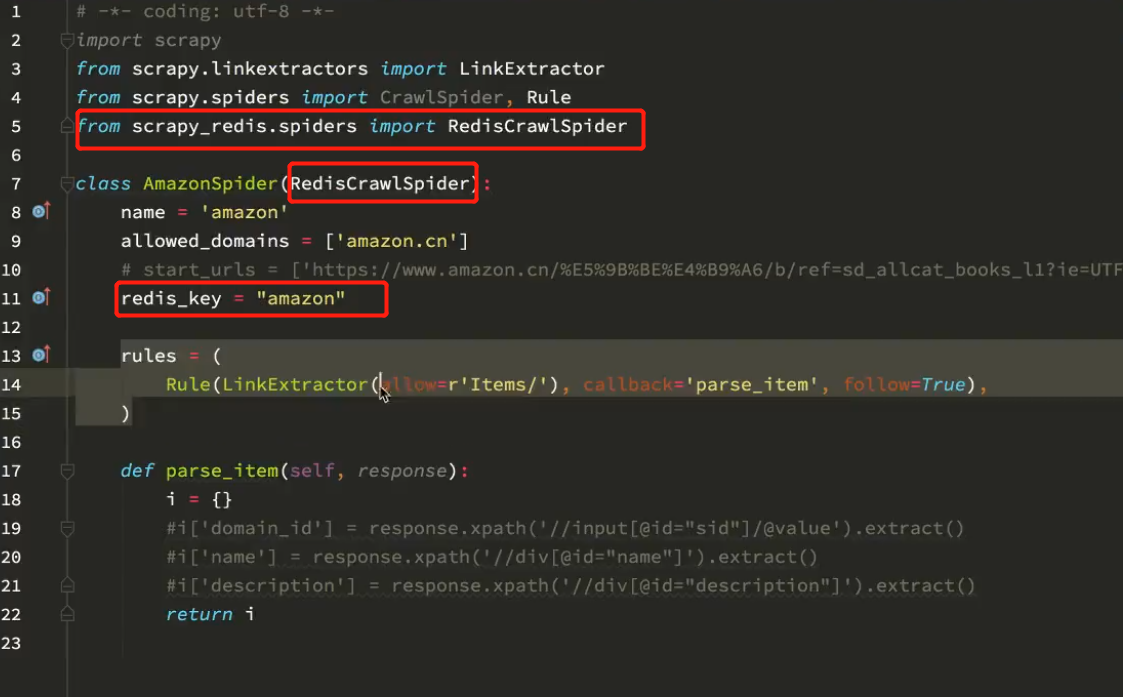
2. settings.py 中:
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" SCHEDULER = "scrapy_redis.scheduler.Scheduler" SCHEDULER_PERSIST = True REDIS_URL = "redis://127.0.0.1:6379" # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = False
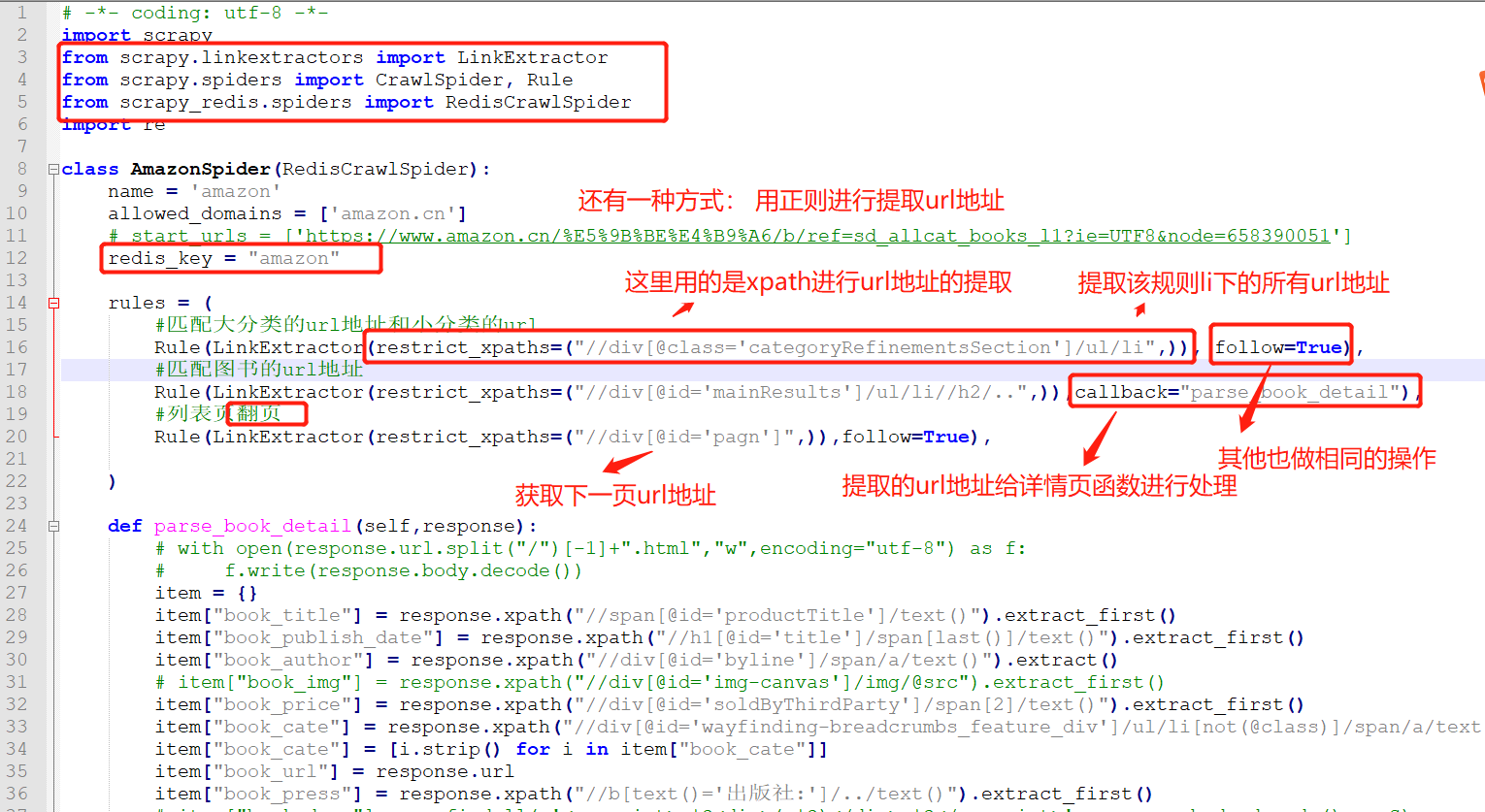
3. amazon.py 最后的爬虫文件
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from scrapy_redis.spiders import RedisCrawlSpider import re class AmazonSpider(RedisCrawlSpider): name = 'amazon' allowed_domains = ['amazon.cn'] # start_urls = ['https://www.amazon.cn/%E5%9B%BE%E4%B9%A6/b/ref=sd_allcat_books_l1?ie=UTF8&node=658390051'] redis_key = "amazon" rules = ( #匹配大分类的url地址和小分类的url Rule(LinkExtractor(restrict_xpaths=("//div[@class='categoryRefinementsSection']/ul/li",)), follow=True), #匹配图书的url地址 Rule(LinkExtractor(restrict_xpaths=("//div[@id='mainResults']/ul/li//h2/..",)),callback="parse_book_detail"), #列表页翻页 Rule(LinkExtractor(restrict_xpaths=("//div[@id='pagn']",)),follow=True), ) def parse_book_detail(self,response): # with open(response.url.split("/")[-1]+".html","w",encoding="utf-8") as f: # f.write(response.body.decode()) item = {} item["book_title"] = response.xpath("//span[@id='productTitle']/text()").extract_first() item["book_publish_date"] = response.xpath("//h1[@id='title']/span[last()]/text()").extract_first() item["book_author"] = response.xpath("//div[@id='byline']/span/a/text()").extract() # item["book_img"] = response.xpath("//div[@id='img-canvas']/img/@src").extract_first() item["book_price"] = response.xpath("//div[@id='soldByThirdParty']/span[2]/text()").extract_first() item["book_cate"] = response.xpath("//div[@id='wayfinding-breadcrumbs_feature_div']/ul/li[not(@class)]/span/a/text()").extract() item["book_cate"] = [i.strip() for i in item["book_cate"]] item["book_url"] = response.url item["book_press"] = response.xpath("//b[text()='出版社:']/../text()").extract_first() # item["book_desc"] = re.findall(r'<noscript>.*?<div>(.*?)</div>.*?</noscript>',response.body.decode(),re.S) # item["book_desc"] = response.xpath("//noscript/div/text()").extract() # item["book_desc"] = [i.strip() for i in item["book_desc"] if len(i.strip())>0 and i!='海报:'] # item["book_desc"] = item["book_desc"][0].split("<br>",1)[0] if len(item["book_desc"])>0 else None print(item)
4. 爬虫程序写完之后进行启动redis 服务
redis-cli
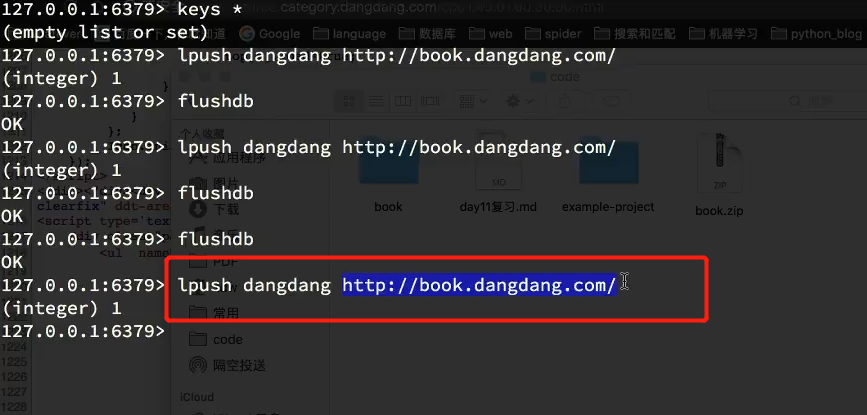
5. 在redis中存入 start_url ,在redis中执行以下命令
lpush amazon https://www.amazon.cn/%E5%9B%BE%E4%B9%A6/b/ref=sd_allcat_books_l1?ie=UTF8&node=658390051
类似 爬取dangdang 图书
爬虫中涉及到的小知识点:
1. url 的补全
import urllib next_url = response.xpath("//a[@class='pn-next']/@href").extract_first() next_url = urllib.parse.urljoin(response.url,next_url)
2. scrapy 中获取文本内容
response.body.decode()
3. 获取scrapy xpath 中获取兄弟节点标签
em_list = dt.xpath("./following-sibling::dd[1]/em")
4. 获取通过字节点获取父节点
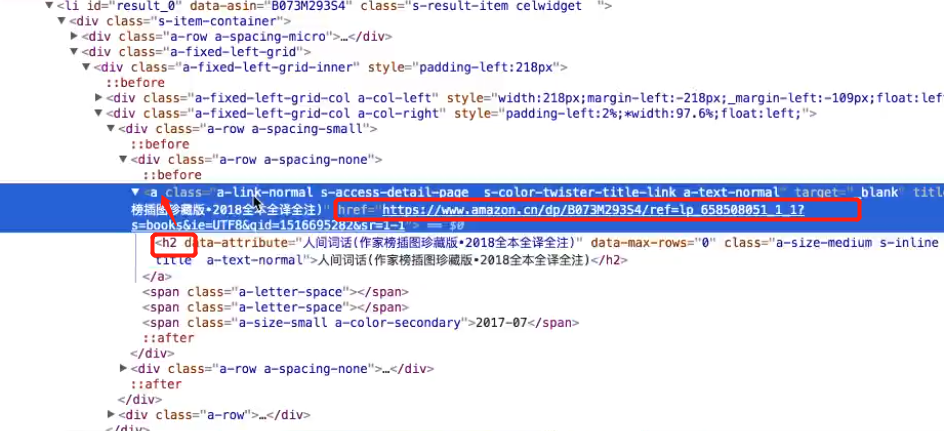
获取a标签中的h2标签,通过h2 标签获取a标签的的herf 属性

5. 获取h1 标签中的最后一个span 标签 h1/span[last()]/text()

6. 网页中base64 转图片,以后自己也可以将图片转化为base64 格式的字符串用来存图片。

7. 找出没有某个class 属性的li li[not(@class)]


8. 用crawlSpdier 时写rule规则时 ,找下图中的下一页的url ,提取url 地址时

rules = ( #匹配大分类的url地址和小分类的url Rule(LinkExtractor(restrict_xpaths=("//div[@class='categoryRefinementsSection']/ul/li",)), follow=True), #匹配图书的url地址 Rule(LinkExtractor(restrict_xpaths=("//div[@id='mainResults']/ul/li//h2/..",)),callback="parse_book_detail"), #列表页翻页 Rule(LinkExtractor(restrict_xpaths=("//div[@id='pagn']",)),follow=True), )
9. 提取下面内容


有疑问可以加wx:18179641802,进行探讨

 浙公网安备 33010602011771号
浙公网安备 33010602011771号