
Scrapy 模拟登陆
Scrapy 模拟登陆
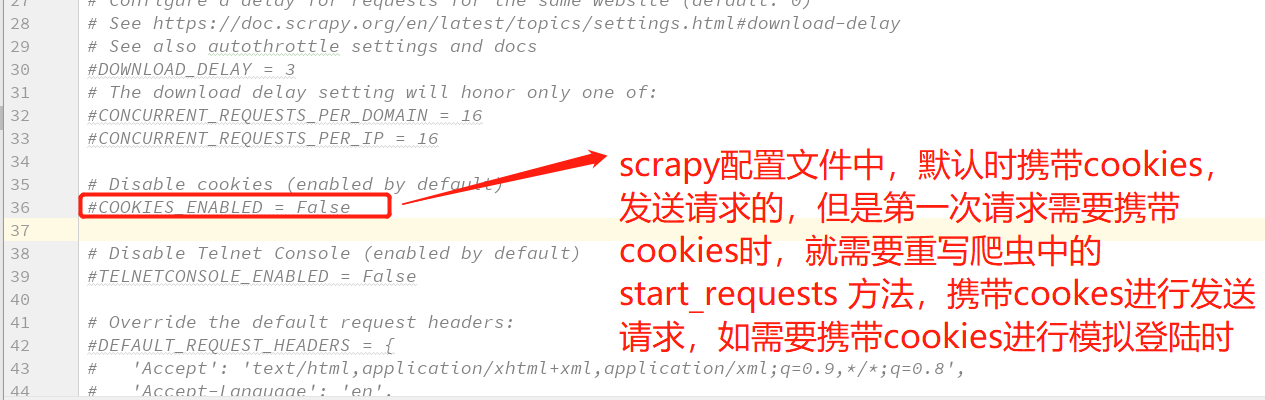
1. 重写 爬虫中的start_requests 方法,直接携带cookies 进行登录
注意的是在scrapy 中,cookies 不能放在headers 中,而需要把cookies作为一个独立的参数。因为在scrapy配置文件中单单独定义了一个cookies配置,读取cookies
会直接从该配中进行cookies的获取。
import scrapy class RenrenSpider(scrapy.Spider): name = 'renren' # allowed_domains = ['renren.com'] start_urls = ['http://www.renren.com/467372239/profile'] #重写start_requests,携带cookie登录 def start_requests(self): # 直接携带登录后的cookies,用程序进行模拟登陆,此cookies 是手动从登录后的用户页面获取的cookies值。 cookies = "anonymid=jt79zqv32wojoo; _r01_=1; ln_uact=1970664163@qq.com; ln_hurl=http://hdn.xnimg.cn/photos/hdn521/20120626/2140/h_main_0eaI_4eba0000010a1375.jpg; jebe_key=f32e6ca1-2cf0-4c86-9704-f044e43596c6%7C6c2f984601684a4271fb8c935cca39fb%7C1552485889426%7C1%7C1552485886593; _de=3C53B1DB040C239CEA46451CE0EBFBB16DEBB8C2103DE356; depovince=GUZ; jebecookies=383e5b17-6a15-4f29-87e4-8bc34d3f7d5c|||||; JSESSIONID=abcFlwgP7q7zDbiPlx4Mw; ick_login=b8ee1ebc-9b38-4b55-85e2-278bdc40f14a; p=c4d2de67ce9245d603bc0ee23389a23f9; first_login_flag=1; t=1130c7f349026f1788028140af80c58d9; societyguester=1130c7f349026f1788028140af80c58d9; id=467372239; xnsid=479ffbb4; ver=7.0; loginfrom=null; wp_fold=0; jebe_key=f32e6ca1-2cf0-4c86-9704-f044e43596c6%7C6c2f984601684a4271fb8c935cca39fb%7C1552485889426%7C1%7C1553576509085" # 使用字典推导式进行 转化成字典形式的cookies cookies = {i.split('=')[0]:i.split('=')[1] for i in cookies.split(';')} yield scrapy.Request( self.start_urls[0] , dont_filter=True, cookies=cookies ) def parse(self, response): import re print(re.findall('邓纪云',response.body.decode())) # 找是否含有该名字信息,如果有的话就说明模拟登陆成功!
在配置文件中注册:可以观察 cookies 在scrapy 发送请求的传递过程。
COOKIES_DEBUG=True
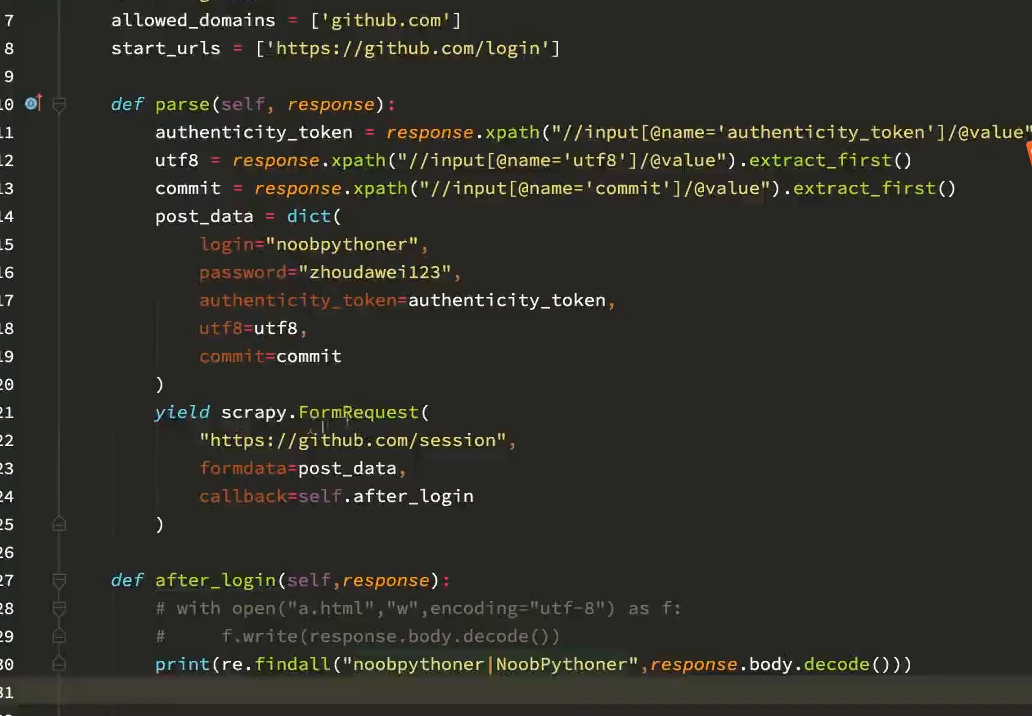
2. scrapy 模拟登陆之发送post的请求
案例:登录GitHub
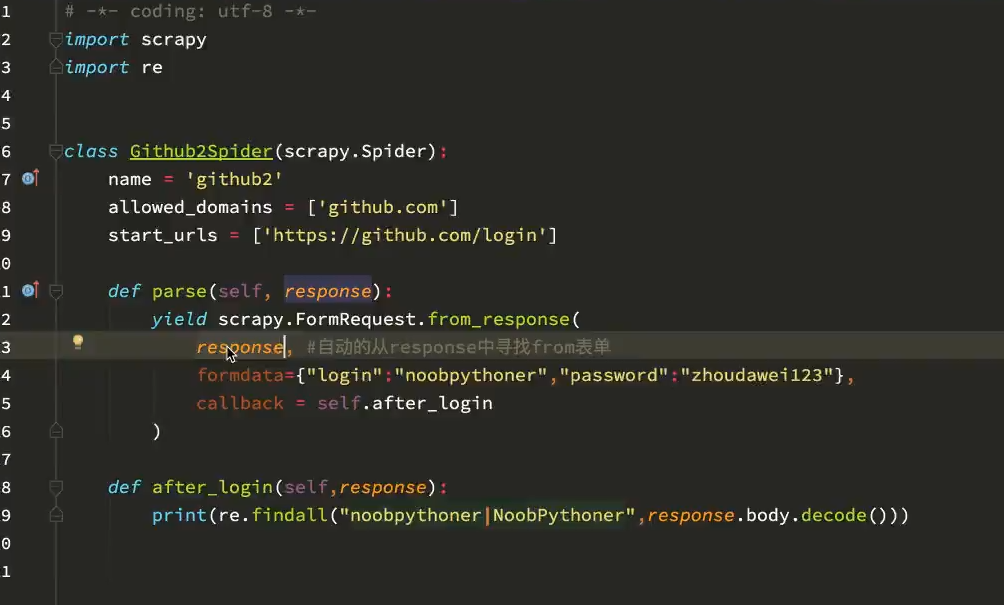
3. scrapy 通过scrapy.Form_request.from_response() 方法进行模拟登陆。
前提是 form表单中有action地址。登录页面中:

有疑问可以加wx:18179641802,进行探讨

 浙公网安备 33010602011771号
浙公网安备 33010602011771号