
scrapy中的CrawlSpider
CrawlSpider爬虫的创建
1. 创建项目
scrapy startproject 项目名
例如:
scrapy startproject circ
2. 创建CrawlSpider 爬虫
scrapy genspider -t crawl 爬虫名 网站名
例如:
scrapy genspider -t crawl bjh bxjg.circ.gov.cn
3.项目结构
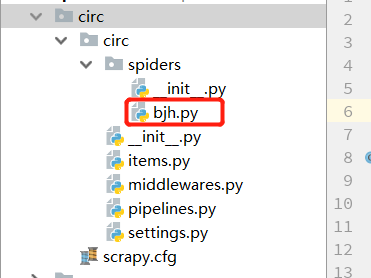
bjy.py 爬虫文件中代码结构如下:
在rule中的参数:
1. linkExtractor连接提取器,提取url地址
2. callback 提取出来的url地址的response 会交给callback处理
3. follow 当前url地址的响应是否重新进行rules来提取url地址
注意点:
在爬虫文件中,以前的parse方法,在CrawlSpider爬虫类中是有特殊的功能,不能定义。
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class BjhSpider(CrawlSpider): name = 'bjh' allowed_domains = ['bxjg.circ.gov.cn'] start_urls = ['http://bxjg.circ.gov.cn/web/site0/tab5240/module14430/page1.htm']
# allow 是正则规则 # linkExtractor连接提取器,提取url地址 # callback 提取出来的url地址的response 会交给callback处理 #follow 当前url地址的响应是否重新进行rules来提取url地址
rules = ( Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True), ) def parse_item(self, response): item = {} #item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get() #item['name'] = response.xpath('//div[@id="name"]').get() #item['description'] = response.xpath('//div[@id="description"]').get() return item
案例 一:
提取 起始url地址为:http://bxjg.circ.gov.cn/web/site0/tab5240/module14430/page1.htm
需求:

步骤:
1 .该url地址的响应是否有我们想要的内容,经分析有
2.提取url地址
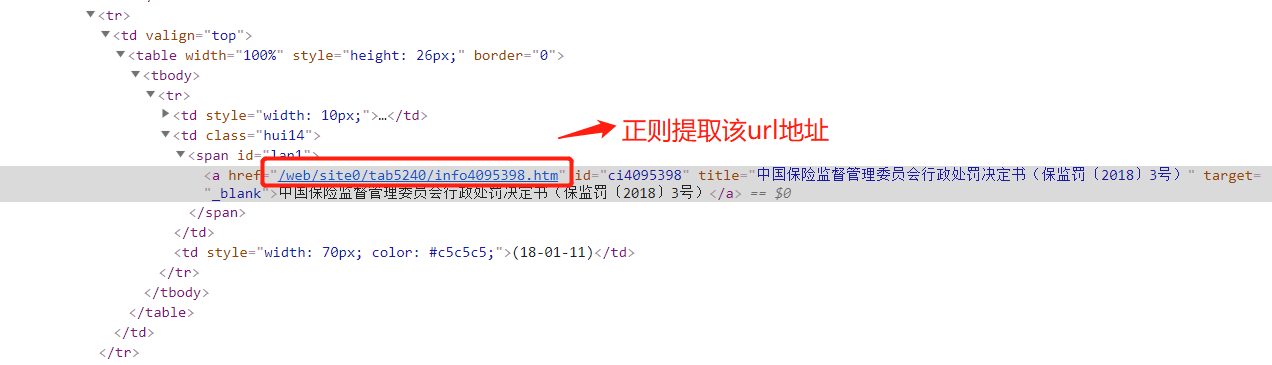
)1.提取详情页的url地址的正则:
allow=r'/web/site0/tab5240/info\d+/.htm' # \d+ 匹配数字 其后的/ 表示转义,因为后面有一个点号
)2. 提取页码url 的正则:
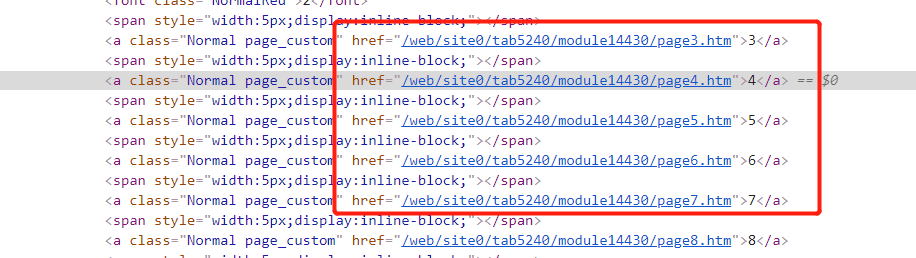
allow=r'/web/site0/tab5240/module14430/page\d+/.htm’ # 同理 \d+ 表示匹配数字,其后的/ 表示转义
想要的数据:详情页的标题和发布时间
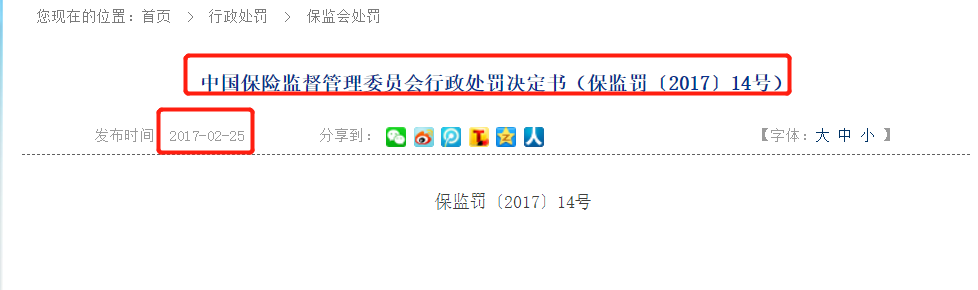
标题:正则提取

分布时间:正则 提取

爬虫代码:
# -*- coding: utf-8 -*- import scrapy import re from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class BjhSpider(CrawlSpider): name = 'bjh' allowed_domains = ['bxjg.circ.gov.cn'] start_urls = ['http://bxjg.circ.gov.cn/web/site0/tab5240/module14430/page1.htm'] # linkExtractor连接提取器,提取url地址 # callback 提取出来的url地址的response 会交给callback处理 #follow 当前url地址的响应是否重新进行rules来提取url地址 rules = ( Rule(LinkExtractor(allow=r'/web/site0/tab5240/info\d+/.htm'), callback='parse_item'), Rule(LinkExtractor(allow=r'/web/site0/tab5240/module14430/page\d+/.htm'), follow=True), ) def parse_item(self, response): item = {} item['title'] = re.findall("<!--TitleStart-->(.*?)<!--TitleEnd-->",response.body.decode())[0] item['pub_time'] = re.findall("发布时间:(20\d{2}-\d{2}-\d{2})",response.body.decode())[0] print(item)
总结:
crawlspider的使用
- 常见爬虫 scrapy genspider -t crawl 爬虫名 allow_domain
- 指定start_url,对应的响应会进过rules提取url地址
- 完善rules,添加Rule ` Rule(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm'), callback='parse_item'),`
- 注意点:
- url地址不完整,crawlspider会自动补充完整之后在请求
- parse函数不能定义,他有特殊的功能需要实现
- callback:连接提取器提取出来的url地址对应的响应交给他处理
- follow:连接提取器提取出来的url地址对应的响应是否继续被rules来过滤
有疑问可以加wx:18179641802,进行探讨

 浙公网安备 33010602011771号
浙公网安备 33010602011771号