


3.K均值算法
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类


2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
iris = load_iris()
data = iris.data[:, 2] # 获取鸢尾花花瓣长度
n = len(data)
k = 3 #类中心个数,即最终分类的类别数
center = np.random.choice(data , k) # 随机取data中的k个数据作为第一次样本中心
d_k = np.zeros(n) # 获取每个点到样本中心的距离
while True:
new_center = np.zeros(k) # 定义一个新的中心
for i in range(n):
d = np.zeros(k) # 定义一个存放距离的数组
for j in range(k):
d[j] = (abs(center[j] - data[i])) # 计算这个点到中心点的距离
d_k[i] = np.argmin(d) # 找出最小距离的下标
# 计算各聚类新均值
for i in range(k): # 按照下标来聚类
index = d_k == i
new_center[i] = np.mean(data[index]) # 计算新聚类中心
# 判定结束
if np.all(center == new_center):
break
else:
center = new_center
plt.scatter(data, d_k, c=d_k, s=50, cmap="Paired")
plt.show()
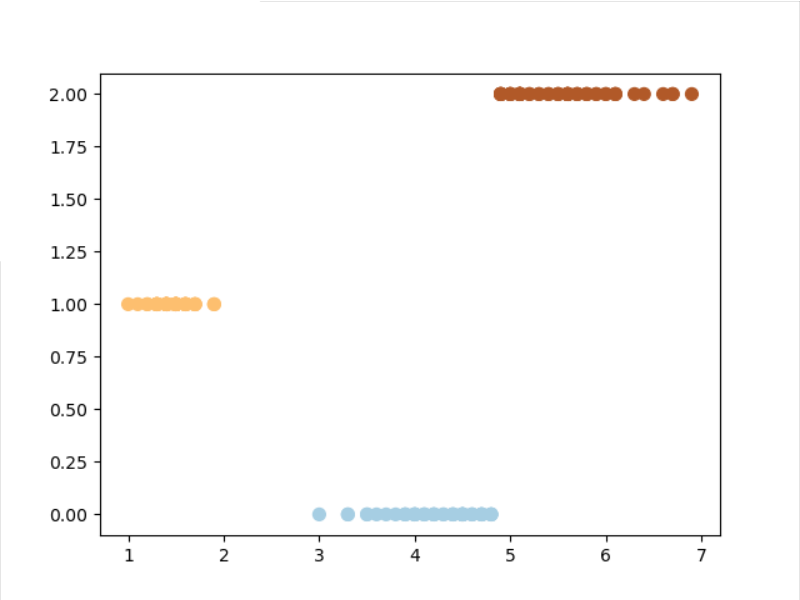
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
data = load_iris()
s = data.data[:,1]
X = s.reshape(-1,1)
model1 = KMeans(n_clusters=3)
model1.fit(X)
y_k = model1.predict(X)
plt.scatter(X[:,0],y_k,c=y_k,s=50,cmap='rainbow')
plt.show()

4). 鸢尾花完整数据做聚类并用散点图显示.
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
data = load_iris()
model = KMeans(n_clusters=3).fit(data['data'])
y2_k = model.predict(data['data'])
plt.scatter(data['data'][:,2],data['data'][:,3],c=y2_k,s=100,cmap='rainbow',alpha=0.5)
plt.show()
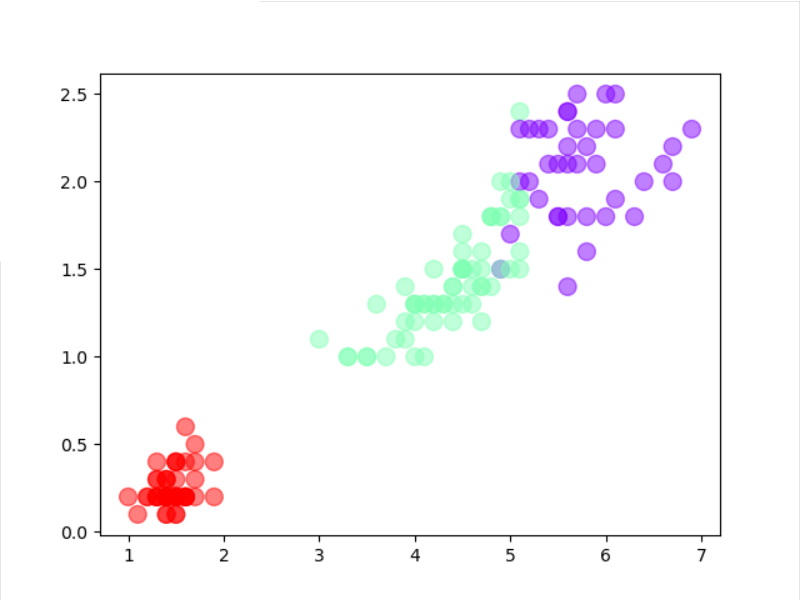
5).想想k均值算法中以用来做什么?
1、老师在统计学生的成绩时,可以用k均值算法来划分学生成绩好坏的等级;
2、可以给学校统计学生的身高和划分;
3、可以给植物学家处理收集的各种植物信息。
