TCP的慢启动和拥塞避免
TCP为了保证数据的完整性采用了许许多多的方法,像启用重传定时器、坚持定时器,通过最大路径发现获取到链路中允许通过的最大数据包大小,还有一些其它的如慢启动、拥塞避免、快速重传等等。
慢启动:
一般通信时,发送方一开始便向网络发送多个报文段,直至达到接收方通告的窗口大小为止。当发送方和接收方处于同一个局域网时,这种方式是可以的。但是如果在发送方和接收方之间存在多个路由器和速率较慢的链路时,就有可能出现一些问题。一些中间路由器必须缓存分组,并有可能耗尽存储器的空间。
慢启动算法通过观察到新分组进入网络的速率应该与另一端返回确认的速率相同而进行工作 。
慢启动为发送方的T C P增加了另一个窗口:拥塞窗口 (congestion window),记为c w n d。当 与另一个网络的主机建立 T C P连接时,拥塞窗口被初始化为 1个报文段(即另一端通告的报文段大小) 。每收到一个 A C K,拥塞窗口就增加一个报文段( c w n d以字节为单位,但是慢启动以报文段大小为单位进行增加)。发送方取拥塞窗口与通告窗口中的最小值作为发送上限。拥塞窗口是发送方使用的流量控制,而通告窗口则是接收方使用的流量控制。
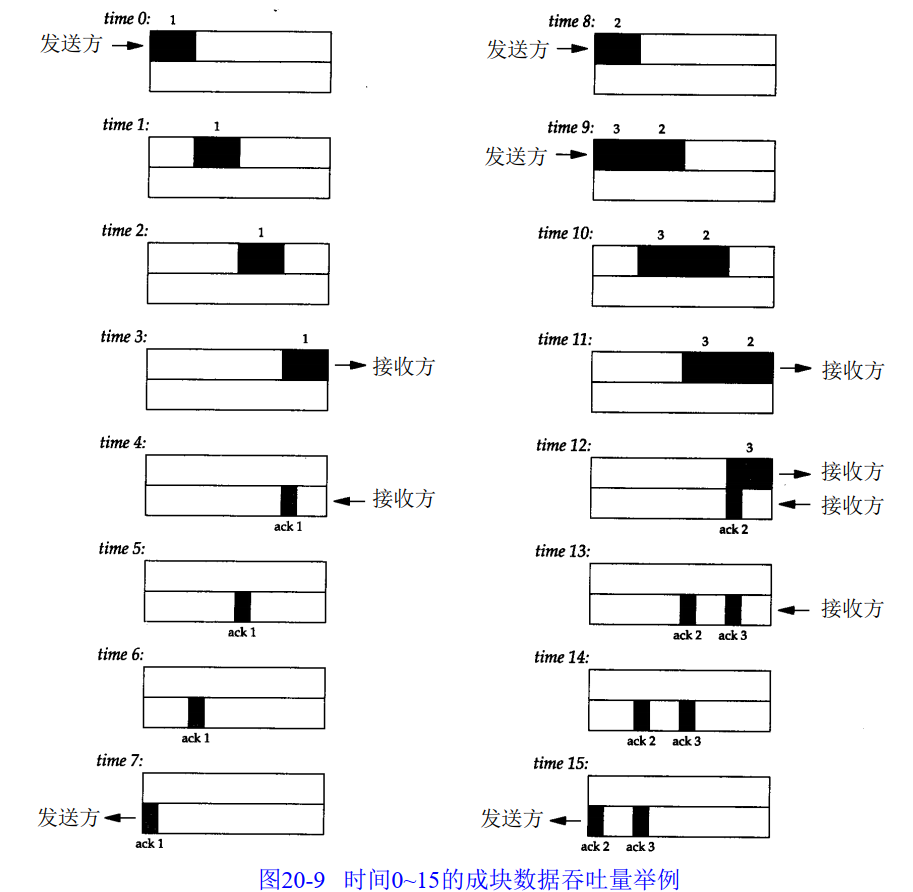
在时间0,发送方发送了一个报文段。由于发送方处于慢启动中(其拥塞窗口为 1个报文段),因此在继续发送以前它必须等待该数据段的确认。
在时间1, 2和3,报文段从左向右移动一个时间单元。在时间 4接收方读取这个报文段并产生确认。经过时间 5、 6和7, A C K移动到左边的发送方。我们有了一个 8个时间单元的往返时间RT T( R o u n d - Trip Ti m e)。我们有意把 A C K报文段画得比数据报文段小,这是因为它通常只有一个 I P首部和一个T C P首部。这里显示仅仅是一个单向的数据流动,并且假定 A C K的移动速率与数据报文段的移动速率相等。实际上并不总是这样。
当发送方收到A C K后,在时间8和9发送两个报文段(我们标记为2和3)。此时它的拥塞窗口为2个报文段。这两个报文段向右传送到接收方,在时间1 2和1 3接收方产生两个A C K。这两个返回到发送方的A C K之间的间隔与报文段之间的间隔一致,被称为 T C P的自计时( s e l f - c l o c k i n g )行为。由于接收方只有在数据到达时才产生A C K,因此发送方接收到的A C K之间的间隔与数据到达接收方的间隔是一致的(然而在实际中,返回路径上的排队会改变ACK的到达率)。

2个A C K的到达使得拥塞窗口从 2个报文段增加为 4个,而这4个报文段在时间 1 6 ~ 1 9时被发送。第 1个A C K在时间2 3到达。 4个A C K的到达使得拥塞窗口从4个报文段增加为8个,并在时间2 4 ~ 3 1发送8个报文段。
在时间3 1及其后续时间,发送方和接收方之间的管道 ( p i p e )被填满。此时不论拥塞窗口和通告窗口是多少,它都不能再容纳更多的数据。每当接收方在某一个时间单位从网络上移去一个报文段,发送方就再发送一个报文段到网络上。但是不管有多少报文段填充了这个管道,返回路径上总是具有相同数目的 A C K。
拥塞避免:
拥塞避免算法是一种处理丢失分组的方法。该算法假定由于分组受到损坏引起的丢失是非常少的(远小于 1 %),因此分组丢失就意味着在源主机和目的主机之间的某处网络上发生了拥塞。有两种分组丢失的指示:发生超时和接收到重复的确认。
拥塞避免算法和慢启动算法是两个目的不同、独立的算法。但是当拥塞发生时,我们希望降低分组进入网络的传输速率,于是可以调用慢启动来作到这一点。在实际中这两个算法通常在一起实现。 拥塞避免算法和慢启动算法需要对每个连接维持两个变量:一个拥塞窗口 c w n d和一个慢启动门限s s t h re s h。这样得到的算法的工作过程如下:
1) 对一个给定的连接,初始化 c w n d为1个报文段, s s t h re s h为6 5 5 3 5个字节。
2) TCP输出例程的输出不能超过 c w n d和接收方通告窗口的大小。拥塞避免是发送方使用的流量控制,而通告窗口则是接收方进行的流量控制。前者是发送方感受到的网络拥塞的估计,而后者则与接收方在该连接上的可用缓存大小有关。
3) 当拥塞发生时(超时或收到重复确认) , s s t h re s h被设置为当前窗口大小的一半( c w n d和接收方通告窗口大小的最小值,但最少为 2个报文段) 。此外,如果是超时引起了拥塞,则c w n d被设置为1个报文段(这就是慢启动)。
4) 当新的数据被对方确认时,就增加 c w n d,但增加的方法依赖于我们是否正在进行慢启动或拥塞避免。如果 c w n d小于或等于 s s t h re s h,则正在进行慢启动,否则正在进行拥塞避免。慢启动一直持续到我们回到当拥塞发生时所处位置的半时候才停止(因为我们记录了在步骤 2中给我们制造麻烦的窗口大小的一半),然后转为执行拥塞避免。
慢启动算法初始设置 c w n d为1个报文段,此后每收到一个确认就加 1,呈一种指数形态增长。拥塞避免算法要求每次收到一个确认时将 c w n d增加1 /c w n d。与慢启动的指数增加比起来,这是一种加性增长 (additive increase)。我们希望在一个往返时间内最多为 c w n d增加1个报文段(不管在这个 RT T中收到了多少个 A C K),然而慢启动将根据这个往返时间中所收到的确认的个数增加c w n d。
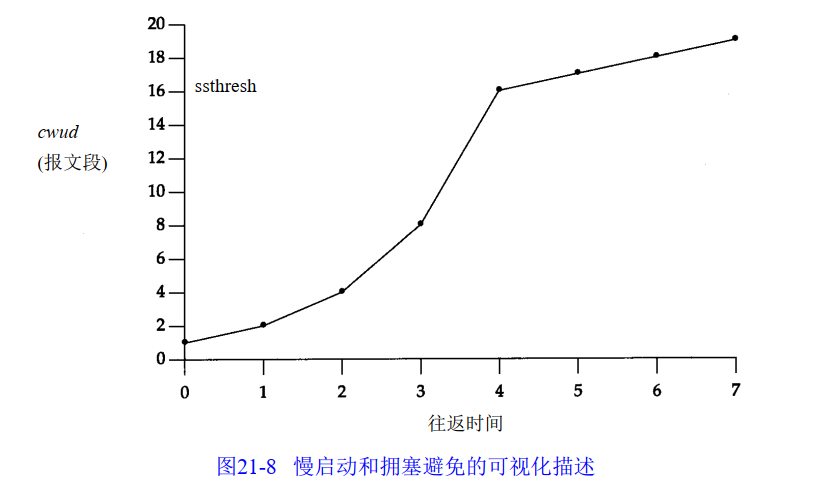
在该图中,假定当 c w n d为3 2个报文段时就会发生拥塞。于是设置 s s t h re s h为1 6个报文段,而c w n d为1个报文段。在时刻 0发送了一个报文段,并假定在时刻 1接收到它的 A C K,此时c w n d增加为2。接着发送了2个报文段,并假定在时刻 2接收到它们的 A C K,于是c w n d增加为4(对每个A C K增加1次) 。这种指数增加算法一直进行到在时刻 3和4之间收到8个A C K后c w n d等于s s t h re s h时才停止,从该时刻起, c w n d以线性方式增加,在每个往返时间内最多增加 1个报文段。
可以理解为 c w n d小于等于16时,采用慢启动算法,大于16时,采用拥塞避免算法。至于慢启动门限的这个取值16,是初始化为最大拥塞窗口的一半。
慢启动只是采用了比引起拥塞更慢些的分组传输速率,但在慢启动期间进入网络的分组数增加的速率仍然是在增加的。
只有在达到s s t h re s h拥塞避免算法起作用时,这种增加的速率才会慢下来。
当流动报文段数量增加到超过最大拥塞窗口数量时,会引起报文丢失,此时,会有快速重传、快速回复等算法来进行一系列的修复操作,如:修改s s t h re s h为当前拥塞窗口的一半并重传丢失报文等等。
