
Ubuntu 22.04 安装 K8S v1.24.6 containerd 添加 NVIDIA Runtime 支持
环境
| 主机名 | ip | 角色 | 显卡 |
|---|---|---|---|
| alg-k8s-master-01 | 172.18.255.122 | master | T4 |
| alg-k8s-node-01 | 172.18.255.123 | node | T4 |
所有节点初始化配置
apt update
apt install lrzsz -y
# master 节点操作
hostnamectl set-hostname alg-k8s-master-01
# node 节点操作
hostnamectl set-hostname alg-k8s-node-01
# 根据实际情况,格式化磁盘,这里是为了把 containerd 的安装目录转移到数据盘上,这边会把数据盘挂在 /data 目录下
parted /dev/vdb mklabel gpt
parted /dev/vdb mkpart primary 1 300G
mkfs.xfs /dev/vdb1
mkdir /data
blkid
# 根据实际情况修改,把数据盘挂载在 /data
vi /etc/fstab
mount -a
df -h
# 修改host
vi /etc/hosts
172.18.255.122 alg-k8s-master-01 cluster-endpoint
172.18.255.123 alg-k8s-node-01
# 开启IPv4转发
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
modprobe overlay
modprobe br_netfilter
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system
# 检查 swap
free -h
# 临时关闭 swap
swapoff -a
# 永久关闭
vi /etc/fstab
注释掉 /swap.img 这行
所有节点安装 containerd
mkdir -p /data/software && cd /data/software
curl -# -O https://mirrors.aliyun.com/docker-ce/linux/ubuntu/dists/jammy/pool/stable/amd64/containerd.io_1.6.20-1_amd64.deb
dpkg -i containerd.io_1.6.20-1_amd64.deb
# 创建 containerd 安装目录
mkdir -p /data/containerd
cd /etc/containerd/
rm config.toml
# 导出默认配置
containerd config default > /etc/containerd/config.toml
# 编辑配置文件
vi /etc/containerd/config.toml
# 修改 sandbox_image 行替换为 aliyun 的 pause 镜像
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.6"
# 修改存储目录
sed -i "s#/var/lib/containerd#/data/containerd#g" /etc/containerd/config.toml
# 配置 systemd cgroup 驱动
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
# 配置镜像加速
[plugins."io.containerd.grpc.v1.cri".registry]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins. "io.contianerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://registry.aliyuncs.com"]
# 启动containerd服务
systemctl enable containerd
systemctl restart containerd
systemctl status containerd
# 复制到其他节点
/etc/containerd/config.toml
安装 Kubernetes 软件 (所有节点都要操作)
# 安装依赖组件
apt-get install -y apt-transport-https ca-certificates curl
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
apt-get update
apt-get install -y kubelet=1.24.6-00 kubeadm=1.24.6-00 kubectl=1.24.6-00
下面这部分是重新编译 k8s 命令,修改证书时间长度,按需操作
apt-get install -y gcc make
cd /data/software
wget https://github.com/kubernetes/kubernetes/archive/refs/tags/v1.24.6.tar.gz
wget https://dl.google.com/go/go1.19.1.linux-amd64.tar.gz
# 配置 go 环境
tar zxvf go1.19.1.linux-amd64.tar.gz -C /usr/local/
vi /etc/profile
export GOROOT=/usr/local/go
export GOPATH=/usr/local/gopath
export PATH=$PATH:$GOROOT/bin
source /etc/profile
go version
# 更新证书参考
https://www.cnblogs.com/klvchen/articles/16166771.html
mv /usr/bin/kubeadm /usr/bin/kubeadm_bak
cp _output/local/bin/linux/amd64/kubeadm /usr/bin/kubeadm
chmod +x /usr/bin/kubeadm
mv /usr/bin/kubelet /usr/bin/kubelet_bak
cp _output/local/bin/linux/amd64/kubelet /usr/bin/kubelet
chmod +x /usr/bin/kubelet
mv /usr/bin/kubectl /usr/bin/kubectl_bak
cp _output/local/bin/linux/amd64/kubectl /usr/bin/kubectl
chmod +x /usr/bin/kubectl
初始化 K8S 集群
在 master 节点操作
cd ~
kubeadm config print init-defaults > kubeadm.yaml
# 修改 kubeadm.yaml
vi kubeadm.yaml
advertiseAddress: 172.18.255.122 # 修改
name: alg-k8s-master-01 # 修改
# 在clusterName: Kubernetes 下新增
controlPlaneEndpoint: cluster-endpoint:6443
imageRepository: registry.aliyuncs.com/google_containers # 修改
kubernetesVersion: 1.24.6 # 修改
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16 # 新增
# 下面的为新增
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
# 开始初始化集群
kubeadm init --config=kubeadm.yaml
# 初始化话过程会有告警,但是不影响使用
# 配置环境变量
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 安装网络插件
mkdir -p /data/yaml/kube-flannel/flannel
cd /data/yaml/kube-flannel/flannel
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
# 祛除 master 污点
kubectl taint nodes alg-k8s-master-01 node-role.kubernetes.io/control-plane:NoSchedule-
kubectl taint nodes alg-k8s-master-01 node-role.kubernetes.io/master:NoSchedule-
node 节点加入K8S集群
在 node 节点操作
# 各K8S集群的 token 值不同,根据上面 master 节点输出的值进行操作
kubeadm join cluster-endpoint:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:27f64abbd825b447e560c90701a5e17a8ff309b266a73efacac5ae900f845469
检查 K8S 集群是否正常
在 master 上操作
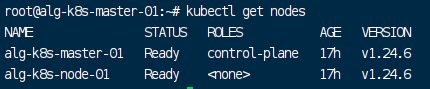
# 看到 Ready 状态即可
kubectl get nodes
# 看到所有 pod 都正常 running 即可
kubectl get pod -A
添加 NVIDIA Runtime 支持
所有节点进行操作
# 安装 nvidia 显卡驱动
因为我这边使用的是阿里云ECS,安装系统的时候已经自动安装完成驱动,手动安装驱动可以参考下面文章
https://www.cnblogs.com/klvchen/p/17295624.html
# 安装 nvidia-container-toolkit 和 nvidia-container-runtime
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
apt-get update
apt-get install -y nvidia-container-toolkit-base
apt-get install -y nvidia-container-runtime
# 修改 config.toml
cd /etc/containerd
cp config.toml config.toml.20230811
vi config.toml
[plugins."io.containerd.grpc.v1.cri"]
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "nvidia" # 修改
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
# 下面是添加
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"
# 重启 containerd
systemctl restart containerd
# 安装 nvidia-device-plugin
mkdir -p /data/yaml/nvidia-device-plugin
cd /data/yaml/nvidia-device-plugin
# 添加 helm repo
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin \
&& helm repo update
helm pull nvdp/nvidia-device-plugin --version 0.12.2
tar zxvf nvidia-device-plugin-0.12.2.tgz
kubectl create ns nvidia-device-plugin
helm install -n nvidia-device-plugin nvdp ./nvidia-device-plugin
# 检查
kubectl -n nvidia-device-plugin get pod

测试 pod 是否能成功调用 GPU
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
restartPolicy: Never
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
EOF
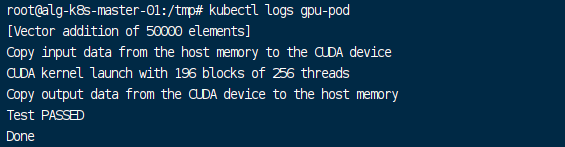
kubectl logs gpu-pod
# 显示 Test PASSED 则成功
参考:
https://blog.csdn.net/bing1zhi2/article/details/125508312
https://www.cnblogs.com/ryanyangcs/p/14102171.html
https://juejin.cn/post/7202877900240339000
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号