
案例实战(一)
一个超大数据量处理系统是如何不堪重负OOM的
大家是否还记得我们不止一次提过的一个超大数据量的计算引擎系统?这个系统是我们自己研发的一个非常复杂的PB级数据计算系统,远比很多流行的开源技术要强悍,架构上也非常复杂,同时处理的数据量也特别大。
首先用最最简化的一张图给大家解释系统的工作流程。简单来说,就是不停的从数据存储中加载大量的数据到内存里来进行复杂的计算,如下图所示。
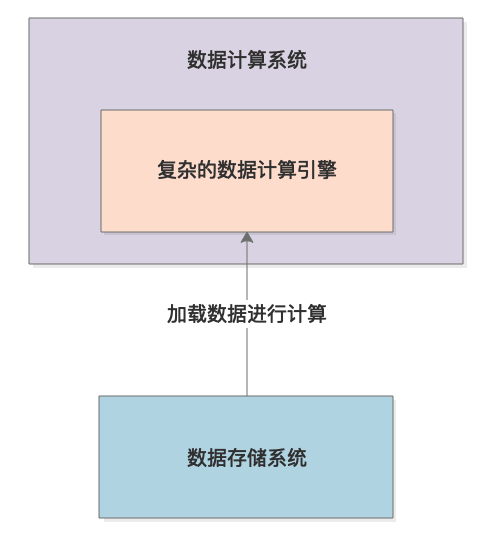
这个系统会不停的加载数据到内存里来计算,每次少则加载几十万条数据,多则加载上百万条数据,所以系统的内存负载压力是非常大的。
这个系统每次加载数据到内存里计算完毕之后,就需要将计算好的数据推送给另外一个系统,两个系统之间的数据推送和交互,最适合的就是基于消息中间件来做
因此当时就选择了将数据推送到Kafka,然后另外一个系统从Kafka里取数据,如下图。
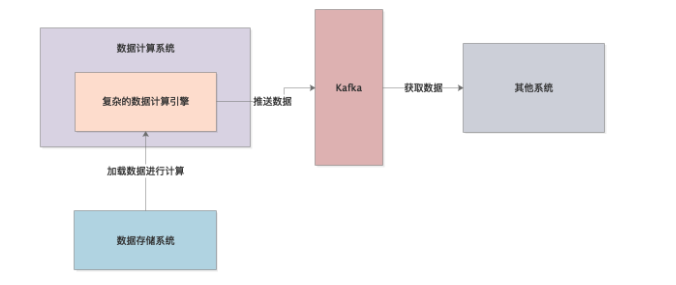
这就是系统完整的一个运行流程,加载数据、计算数据、推送数据。
针对Kafka故障设计的高可用场景
既然系统架构如此,那么大家思考一下,数据计算系统要推送计算结果到Kafka去,万一Kafka挂了怎么办?此时就必须设计一个针对Kafka的故障高可用机制
就当时而言,刚开始负责这块的工程师选择了一个思考欠佳的技术方案。一旦发现Kafka故障,就会将数据都留存在内存里,不停的重试,直到Kafka恢复才可以,大家看下图的示意。
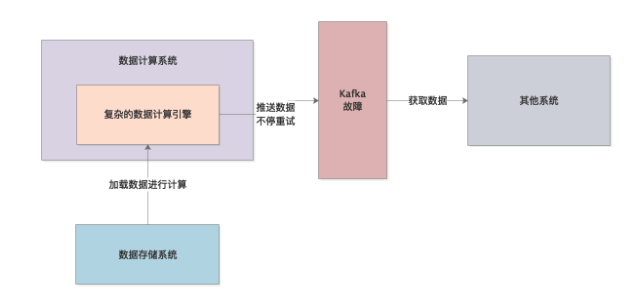
这个时候就有一个隐患了,万一真的遇上Kafka故障,那么一次计算对应的数据必须全部驻留内存,无法释放,一直重试等待Kafka恢复,这是绝对不合理的一个方案设计。
然后数据计算系统还在不停的加载数据到内存里来处理,每次计算完的数据还无法推送到Kafka,全部得留存在内存里等着,如此循环往复,必然导致内存里的数据越来越多。
无法释放的内存最终导致OOM
正是因为有这个机制的设计,所以有一次确实发生了Kafka的短暂临时故障,也因此导致了系统无法将计算后的数据推送给Kafka
然后所有数据全部驻留在内存里等待,并且还在不停的加载数据到内存里来计算。
内存里的数据必然越来越多,每次Eden区塞满之后,大量存活的对象必须转入老年代中,而且这些老年代里的对象还是无法释放掉的。
老年代最终一定会满,而且最终一定会有一次Eden区满之后,一大批对象要转移到老年代,结果老年代即使Full gc之后还是没有空间可以放的下,最终就会导致内存溢出。然后线上收到报警说内存溢出。
最后这个系统全线崩溃,无法正常运行。
如何对这个问题进行修复呢?
其实很简单,当时就临时直接取消了Kafka故障下的重试机制,一旦Kafka故障,直接丢弃掉本地计算结果,允许释放大量数据占用的内存。后续的话,将这个机制优化为一旦Kafka故障,则计算结果写本地磁盘,允许内存中的数据被回收。
这就是一个非常真实的线上系统设计不合理导致的内存溢出问题,想必大家看了这个案例后,一定对内存溢出问题感触更加深刻了。
案例实战:两个新手工程师误写代码是如何导致OOM的
第一个案例:一时迷糊写出了一个无限循环调用
第一个案例是当时团队里招聘的一个实习生同学,写出了一个代码上的bug导致线上系统出现栈内存溢出的场景。
当时有一个非常重要的系统,我们设计了一个链路监控机制,也就是会在一个比较核心的链路节点,写一些重要的日志到Elasticsearch集群里去,事后会基于ELK进行核心链路日志的一些分析,如下图所示。
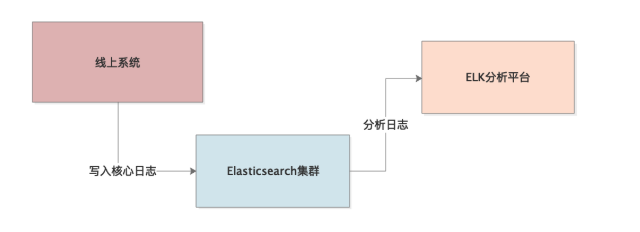
同时我们对这个机制做了规定,如果在某个节点写日志时发生了某些异常,此时也必须将这个链路节点的异常写入ES集群里去,因为我们在分析的时候,需要知道系统运行到这里有一个异常。
因此当时那个实习生同学写出来的伪代码大致如下:

不知道大家看了上面的代码是作何感想?当时这个同学居然在log()方法中一旦ES集群出现故障的时候再次调用了自己,继续尝试将日志写入ES集群。
因此在线上系统中,有一次ES集群短暂故障了一会儿,结果直接就导致log()方法中写ES集群每次都是失败的,都会抛异常。
而一旦抛异常进入了catch语句中,就会再次重新回过头来调用log()方法。
然后log()方法再次写ES集群发现不行,继续抛异常进入catch中,再次循环调用自己。
线上系统本来在ES集群故障的时候不该有什么问题的,因为核心业务逻辑都是可以运行的,最多不过就是无法把核心日志写入ES集群罢了。
但是因为这个bug,导致在ES故障时,所有系统全部在写日志的时候,陷入了一个无限循环调用log()方法的困境中。
之前给大家演示过,一旦无限循环调用方法自己,一定会在一定时间导致线程的栈内存溢出的,此时直接会导致JVM进程的崩溃
系统居然因为这么一个小问题崩溃了!这就是一次非常真实的线上案例。
后来针对此类问题,我们都是通过严格的持续集成+严格的Code Review标准来避免的
第二个案例:没有缓存的动态代理
第二个案例同样是之前的一个新手工程师写的,这个并不是实习生,是一个校招生同学,在团队里工作了1年左右的时间。
但是确实因为经验不足,有一次在实现一块代码机制的时候,也是犯了一个很大的错误。
简单来说,当时这个同学想要实现一个动态代理机制,也就是说在系统运行的时候,针对已有的某个类,生成一个动态代理类,也就是动态生成类,然后对那个类的一些方法调用做一些额外的处理。
当时这个是一个我们自己研发的分布式事务框架,对于这个框架是有这位同学参与在里面的,因此在框架中有时候要对一些已经有的类实现动态代理,去实现分布式事务一些的复杂底层机制。
当时大概的一个伪代码其实跟之前给大家的代码是类似的:
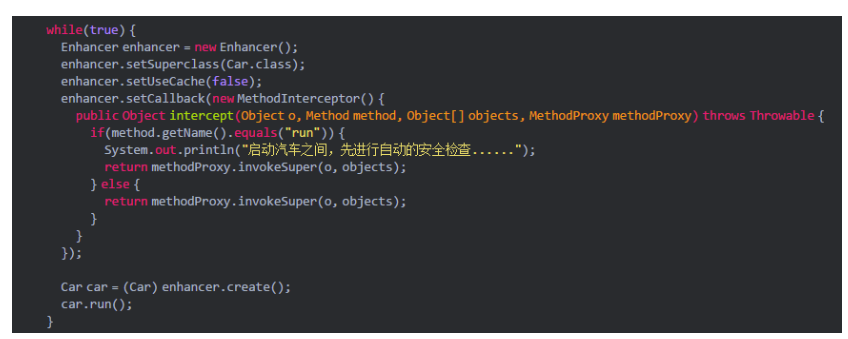
不知道大家发现类似这种代码里的一个问题没有?比如你用CGLIB的Enhancer针对某个类动态生成了一个子类,这个子类你完全可以缓存起来,下次直接用这个已经生成好的子类来创建对象就可以了
类似下面这样:

其实这个类只要生成一次就可以了,下次来直接用这个动态生成的类创建一个对象就可以了。
但是当时那个工程师没有缓存这个动态生成的类,就是每次调用方法都生成一个类,这就闯祸了。
有一次线上系统负载很高的时候,因为这个框架直接导致瞬间创建了一大堆的类,塞满了Metaspace区域无法回收,进而导致Metaspace区域直接内存溢出,系统也崩溃了,这也是一个很大的问题。
后来对于这类问题,是严格要求每次上线必须走严格的自动化压力测试,通过高并发压力下系统是否正常运行支撑24小时,来判断是否可以上线。
这样类似于这类代码在上线之前就会被压力测试露出马脚,因为压力一大,瞬间会引发这个问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号