

go in action学习,go语法一些特殊点
1.如果接口类型只包含一个方法,那么这个类型的名字以 er 结尾。如果接口类型内部声明了多个方法,其名字需要与其行为关联。
2.如果要让一个用户定义的类型实现一个接口,这个用户定义的类型要实现接口类型里声明的所有方法。
3.实现一个接口时,使用一个空结构声明了具体的结构类型,这样空结构在创建实例时,不会分配任何内存。这种结构很适合创建没有任何状态的类型。
4.如果声明函数的时候带有接收者,则意味着声明了一个方法。这个方法会和指定的接收者的 类型绑在一起。即可以使用这个类型的值或者指向这个类型值的指针来调用这个方法。
函数带有接受者 -> 可以理解为接口的实现者,只有这个类型的对象,才可以调用这个具体的函数。同时往往会定义一个没有接受者的函数,即一个抽象层。
func Search(feed *Feed, searchTerm string)
// 方法声明为使用 defaultMatcher 类型的值作为接收者 func (m defaultMatcher) Search(feed *Feed, searchTerm string) // 方法声明为使用指向 defaultMatcher 类型值的指针作为接收者 func (m *defaultMatcher) Search(feed *Feed, searchTerm string)
5.因为大部分方法在被调用后都需要维护接收者的值的状态,所以会将方法的接收者声明为指针。
6.使用指针作为接收者声明的方法,只能在接口类型的值是一个指针的时候被调用。使用值作为接收者声明的方法,在接口类型的值为值或者指针时,都可以被调用。

// 方法声明为使用指向 defaultMatcher 类型值的指针作为接收者 func (m *defaultMatcher) Search(feed *Feed, searchTerm string) // 通过 interface 类型的值来调用方法 var dm defaultMatcher var matcher Matcher = dm // 将值赋值给接口类型 matcher.Search(feed, "test") // 使用值来调用接口方法 > go build
// 编译报错 cannot use dm (type defaultMatcher) as type Matcher in assignment
// 方法声明为使用 defaultMatcher 类型的值作为接收者 func (m defaultMatcher) Search(feed *Feed, searchTerm string) // 通过 interface 类型的值来调用方法 var dm defaultMatcher var matcher Matcher = &dm // 将指针赋值给接口类型 matcher.Search(feed, "test") // 使用指针来调用接口方法 > go build Build Successful
7.通道会一直被阻塞,直到有结果写入 。如果使用for 循环,一旦通道被关闭,循环就会终止,所以一般会用另一个goroutine来接受通道。
8.在main import进的package里面的文件init函数,就会在main执行前被调用。
9.结构体的标签用法,但使用标签会有效率问题,微服务的话,json传递信息时有另外一种方式 用proto
type ( // item 根据 item 字段的标签,将定义的字段 // 与 rss 文档的字段关联起来 item struct { XMLName xml.Name `xml:"item"` PubDate string `xml:"pubDate"` Title string `xml:"title"` Description string `xml:"description"` Link string `xml:"link"` GUID string `xml:"guid"` GeoRssPoint string `xml:"georss:point"` }
10.导入包时,使用‘_’使用下划线标识符作为别名导入包,可以让main.go 代码文件里的代码并没有直接使用任何包里的标识符,但一样会在main执行前执行init的调用并不报错。
11.每个代码文件都属于一个包,而包名应该与代码文件所在的文件夹同名。
12.Go 语言提供了多种声明和初始化变量的方式。如果变量的值没有显式初始化,编译器会 将变量初始化为零值。
13.使用指针可以在函数间或者 goroutine 间共享数据。通过启动 goroutine 和使用通道完成并发和同步。
14.在 Go 语言里,包是个非常重要的概念。其设计理念是使用包来封装不同 语义单元的功能。
15.要导入的多个包具有相同的名字,重名的包可以通过命名导入来导入。命名导入是 指,在 import 语句给出的包路径的左侧定义一个名字,将导入的包命名为新名字。
package main import ( "fmt" myfmt "mylib/fmt" ) func main() { fmt.Println("Standard Library") myfmt.Println("mylib/fmt") }
16.空白标识符 下划线字符(_)在 Go 语言里称为空白标识符,有很多用法。这个标识符用来抛弃不 想继续使用的值,如给导入的包赋予一个空名字,或者忽略函数返回的、不感兴趣的值。
17.(1)go vet 命令会帮忙捕获以下问题:
Printf 类函数调用时,类型匹配错误的参数。
定义常用的方法时,方法签名的错误。
错误的结构标签。
没有指定字段名的结构字面量。
(2)go fmt格式化代码
(3)开发人员启动自己的文档服务器,只需要在终端会话中输入如下命令: godoc -http=:6060。go doc tar 直接在终端看文档。
18.环境变量 GOPATH 决定了 Go 源代码在磁盘上被保存、编译和安装的位置。可以为每个工程设置不同的 GOPATH,以保持源代码和依赖的隔离。可以使用 go get 来获取别人的包并将其安装到自己的 GOPATH 指定的目录。社区开发的依赖管理工具,如 godep(需要重写import路径)、vender 和 gb(不用重写import路径,但是跟go get兼容,一个gb项目的依赖包路径跟go get不一样)
godep
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | $GOPATH/src/github.com/ardanstudios/myproject |-- Godeps | |-- Godeps.json | |-- Readme | |-- _workspace | |-- src | |-- bitbucket.org | |-- ww | | |-- goautoneg | | |-- Makefile | | |-- README.txt | | |-- autoneg.go | | |-- autoneg_test.go | |-- github.com | |-- beorn7 | |-- perks | |-- README.md | |-- quantile | |-- bench_test.go | |-- example_test.go | |-- exampledata.txt | |-- stream.go | |-- examples |-- model |-- README.md |-- main.go |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | 重写路径前 package main import ( "bitbucket.org/ww/goautoneg" "github.com/beorn7/perks" )重写路径后 package main import ( "github.ardanstudios.com/myproject/Godeps/_workspace/src/ bitbucket.org/ww/goautoneg" "github.ardanstudios.com/myproject/Godeps/_workspace/src/github.com/beorn7/perks" ) |
gb
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | /home/bill/devel/myproject ($PROJECT)|-- src| |-- cmd| | |-- myproject| | | |-- main.go| |-- examples| |-- model| |-- README.md|-- vendor |-- src |-- bitbucket.org | |-- ww | |-- goautoneg | |-- Makefile | |-- README.txt | |-- autoneg.go | |-- autoneg_test.go |-- github.com |-- beorn7 |-- perks |-- README.md |-- quantile |-- bench_test.go |-- example_test.go |-- exampledata.txt |-- stream.go |
19.在 Go 语言里,数组是一个值。这意味着数组可以用在赋值操作中。变量名代表整个数组,因此,同样类型的数组可以赋值给另一个数组。
1 2 3 4 5 6 7 | // 声明第一个包含 5 个元素的字符串数组var array1 [5]string// 声明第二个包含 5 个元素的字符串数组// 用颜色初始化数组array2 := [5]string{"Red", "Blue", "Green", "Yellow", "Pink"}// 把 array2 的值复制到 array1array1 = array2 |
20.切片的结构,
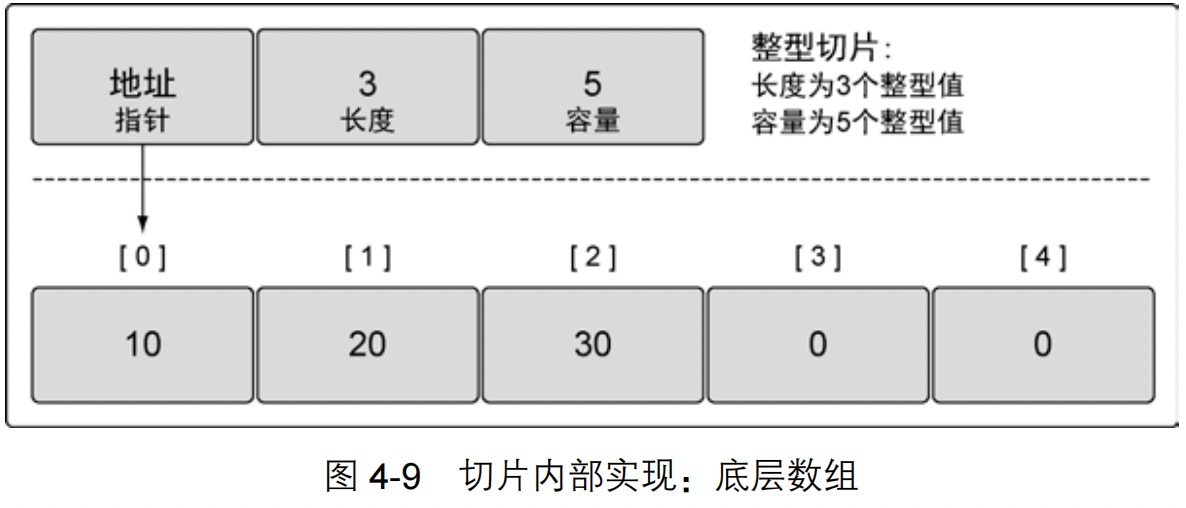
1 2 3 4 5 6 7 8 9 10 11 12 | // 创建一个整型切片// 其长度为 3 个元素,容量为 5 个元素slice := make([]int, 3, 5)// 创建 nil 整型切片var slice []int// 使用 make 创建空的整型切片slice := make([]int, 0)// 使用切片字面量创建空的整型切片slice := []int{} |
21.切片只能访问到其长度内的元素。试图访问超出其长度的元素将会导致语言运行时异常。与切片的容量相关联的元素只能用于增长切片。在使用这部分元素前,必须将其合并到切片的长度里。
1 2 3 4 5 6 7 8 9 10 | // 其长度和容量都是 5 个元素slice := []int{10, 20, 30, 40, 50}// 创建一个新切片// 其长度为 2 个元素,容量为 4 个元素newSlice := slice[1:3]// 修改 newSlice 索引为 3 的元素// 这个元素对于 newSlice 来说并不存在newSlice[3] = 45Runtime Exception:panic: runtime error: index out of range |
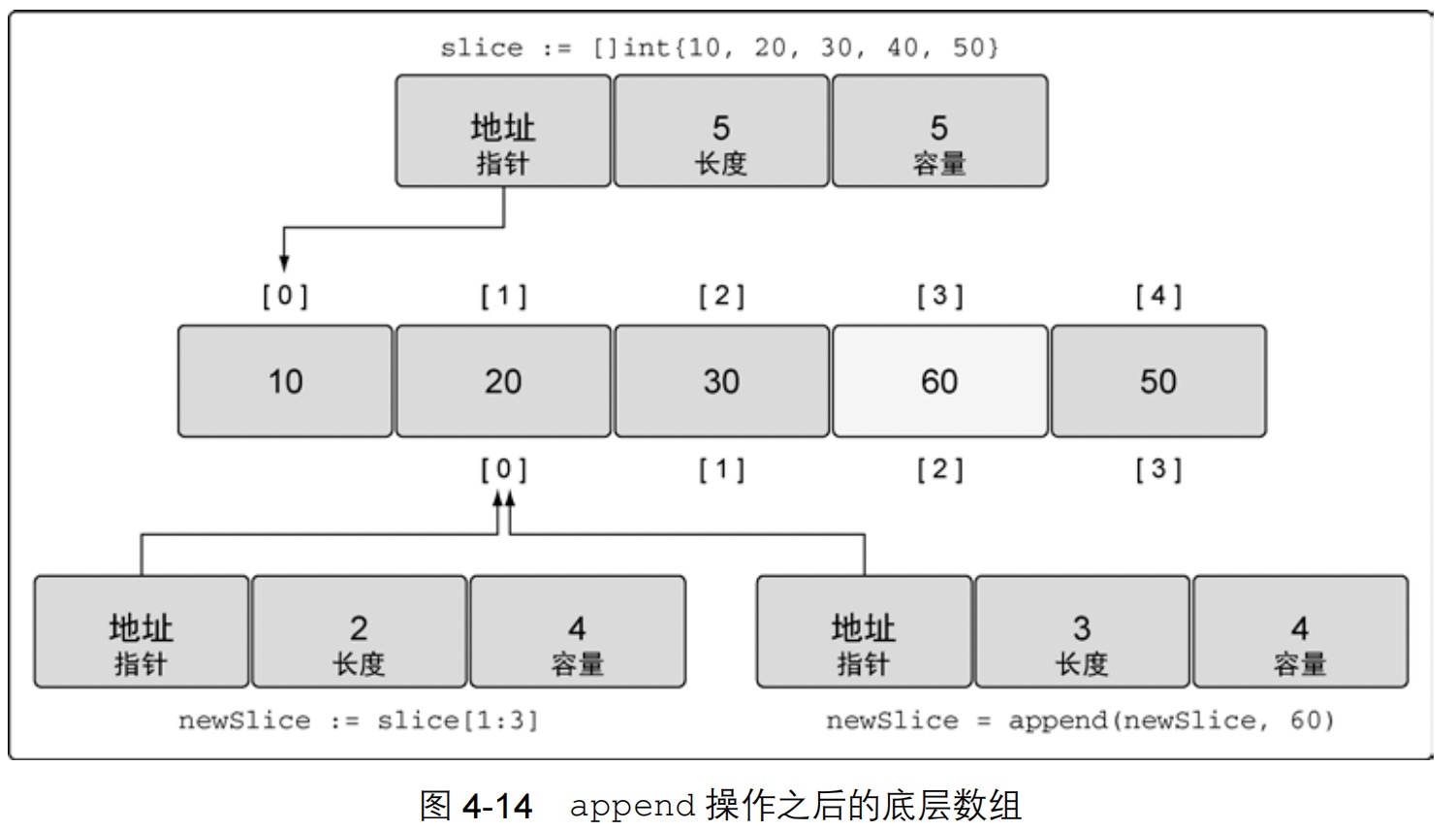
22.切片增长,函数 append 总是会增加新切片的长度,而容量有可能会改变,也可能不会改变,这取决于被操作的切片的可用容量。
1 2 3 4 5 6 7 8 9 | // 创建一个整型切片// 其长度和容量都是 5 个元素slice := []int{10, 20, 30, 40, 50}// 创建一个新切片// 其长度为 2 个元素,容量为 4 个元素newSlice := slice[1:3]// 使用原有的容量来分配一个新元素// 将新元素赋值为 60newSlice = append(newSlice, 60) |
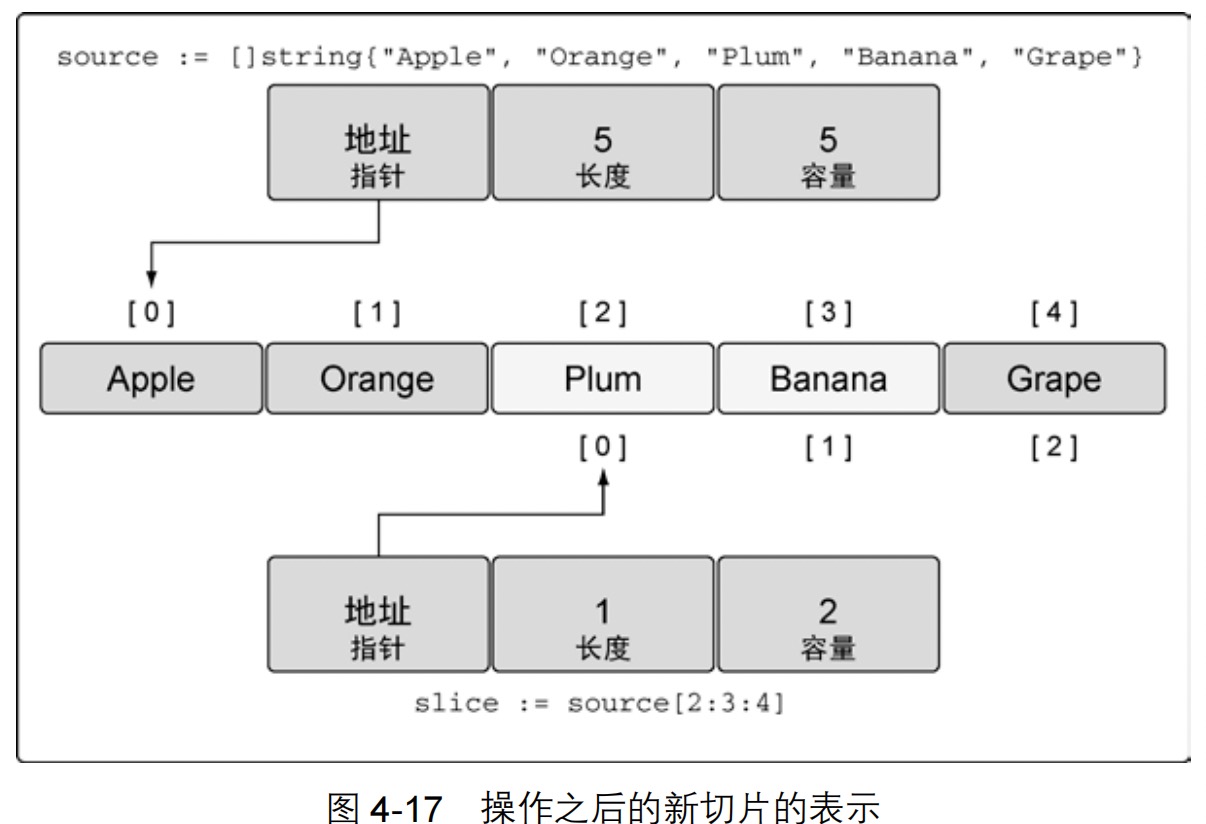
23.使用 3 个索引创建切片。
1 2 3 4 5 6 7 | // 创建字符串切片// 其长度和容量都是 5 个元素source := []string{"Apple", "Orange", "Plum", "Banana", "Grape"}// 将第三个元素切片,并限制容量// 其长度为 1 个元素,容量为 2 个元素slice := source[2:3:4] |
24.内置函数 append 会首先使用可用容量。一旦没有可用容量,会分配一个新的底层数组。这导致很容易忘记切片间正在共享同一个底层数组。一旦发生这种情况,对切片进行修改,很可能会导致随机且奇怪的问题。对切片内容的修改会影响多个切片,却很难找到问题的原因。如果在创建切片时设置切片的容量和长度一样,就可以强制让新切片的第一个 append 操作创建新的底层数组,与原有的底层数组分离。新切片与原有的底层数组分离后,可以安全地进行后续修改。
1 2 3 4 5 6 7 8 | // 创建字符串切片// 其长度和容量都是 5 个元素source := []string{"Apple", "Orange", "Plum", "Banana", "Grape"}// 对第三个元素做切片,并限制容量// 其长度和容量都是 1 个元素slice := source[2:3:3]// 向 slice 追加新字符串slice = append(slice, "Kiwi") |
25.将一个切片追加到另一个切片
1 2 3 4 5 6 7 | // 创建两个切片,并分别用两个整数进行初始化s1 := []int{1, 2}s2 := []int{3, 4}// 将两个切片追加在一起,并显示结果,切片 s2 里的所有值都追加到了切片 s1 的后面fmt.Printf("%v\n", append(s1, s2...))Output:[1 2 3 4] |
26.迭代切片,注意,range 创建了每个元素的副本,而不是直接返回对该元素的引用,如果使用该值变量的地址作为指向每个元素的指针,就会造成错误,因为迭代返回的变量是一个迭代过程中根据切片依次赋值的新变量,所以 value 的地址(&value)总是相同的。要想获取每个元素的地址,可以使用切片变量和索引值(&slice[index])。
1 2 3 4 5 6 7 8 9 10 11 12 | // 创建一个整型切片// 其长度和容量都是 4 个元素slice := []int{10, 20, 30, 40}// 迭代每一个元素,并显示其值for index, value := range slice {fmt.Printf("Index: %d Value: %d\n", index, value)} Output:Index: 0 Value: 10Index: 1 Value: 20Index: 2 Value: 30Index: 3 Value: 40 |
27.Go语言既允许使用值,也允许使用指针来调用方法,不必严格符合接收者的类型。
28.内置类型是由语言提供的一组类型,数值类型、字符串类型和布尔类型,这些类型本质上是原始的类型,当对这些值进行增加或者删除的时候,会创建一个新值。当把这些类型的值传递给方法或者函数时,应该传递一个对应值的副本。比如
1 2 3 4 5 6 | func Trim(s string, cutset string) string {if s == "" || cutset == "" {return s} return TrimFunc(s, makeCutsetFunc(cutset))} |
29.Go 语言里的引用类型有如下几个:切片、映射、通道、接口和函数类型。当声明上述类型的变量时,创建的变量被称作标头(header)值。从技术细节上说,字符串也是一种引用类型。
1 2 3 4 5 6 7 8 9 | func (ip IP) MarshalText() ([]byte, error) {if len(ip) == 0 {return []byte(""), nil} if len(ip) != IPv4len && len(ip) != IPv6len {return nil, errors.New("invalid IP address")} return []byte(ip.String()), nil} |
31.结构类型,用来描述一组数据值,这组值的本质即可以是原始的,也可以是非原始的。如果决定在某些东西需要删除或者添加某个结构类型的值时该结构类型的值不应该被更改,那么需要遵守之前提到的内置类型和引用类型的规范,即定义方法的接受者时,用的是值传递,在函数并返回了一个新对应类型的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | type Time struct {// sec 给出自公元 1 年 1 月 1 日 00:00:00// 开始的秒数sec int64// nsec 指定了一秒内的纳秒偏移,// 这个值是非零值,// 必须在[0, 999999999]范围内nsec int32// loc 指定了一个 Location, // 用于决定该时间对应的当地的分、小时、// 天和年的值// 只有 Time 的零值,其 loc 的值是 nil// 这种情况下,认为处于 UTC 时区loc *Location} |
非原始的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | // File 表示一个打开的文件描述符type File struct {*file}// file 是*File 的实际表示// 额外的一层结构保证没有哪个 os 的客户端// 能够覆盖这些数据。如果覆盖这些数据,// 可能在变量终结时关闭错误的文件描述符type file struct {fd intname stringdirinfo *dirInfo // 除了目录结构,此字段为 nilnepipe int32 // Write 操作时遇到连续 EPIPE 的次数} |
1 2 3 4 5 6 7 8 9 | func (f *File) Chdir() error {if f == nil {return ErrInvalid} if e := syscall.Fchdir(f.fd); e != nil {return &PathError{"chdir", f.name, e}} return nil} |
// runner 包管理处理任务的运行和生命周期 package runner import ( "errors" "os" "os/signal" "time" ) // Runner 在给定的超时时间内执行一组任务, // 并且在操作系统发送中断信号时结束这些任务 type Runner struct { // interrupt 通道报告从操作系统 // 发送的信号 依赖底层操作系统实现,linux下是syscall.Signal interrupt chan os.Signal // complete 通道报告处理任务已经完成 complete chan error // timeout 报告处理任务已经超时 timeout <-chan time.Time // tasks 持有一组以索引顺序依次执行的 // 函数 tasks []func(int) } // ErrTimeout 会在任务执行超时时返回 var ErrTimeout = errors.New("received timeout") // ErrInterrupt 会在接收到操作系统的事件时返回 var ErrInterrupt = errors.New("received interrupt") // New 返回一个新的准备使用的Runner func New(d time.Duration) *Runner { return &Runner{
// interrupt定义为1的缓冲channel,确保代码运行时发送这个事件不会被阻塞,如果goroutine没有准备好接受这个值就丢弃,比如
// 比如用户反复用ctrl+c,程序只会在这个通道缓冲区可用的时候接受事件,其余的所有事件会被丢弃。 interrupt: make(chan os.Signal, 1),
// 用无缓冲区通道,为了groutine等待main有接受到channel了才终止 complete: make(chan error),
// 代码运行时,经过了duration时间后,会像这个time类型通道发送一个值 timeout: time.After(d), } } // Add 将一个任务附加到Runner 上。这个任务是一个 // 接收一个int 类型的ID 作为参数的函数 func (r *Runner) Add(tasks ...func(int)) { r.tasks = append(r.tasks, tasks...) } // Start 执行所有任务,并监视通道事件 func (r *Runner) Start() error { // 我们希望接收所有中断信号 signal.Notify(r.interrupt, os.Interrupt) // 用不同的goroutine 执行不同的任务 go func() { r.complete <- r.run() }() select { // 当任务处理完成时发出的信号 case err := <-r.complete: return err // 当任务处理程序运行超时时发出的信号 case <-r.timeout: return ErrTimeout } } // run 执行每一个已注册的任务 func (r *Runner) run() error { for id, task := range r.tasks { // 检测操作系统的中断信号 if r.gotInterrupt() { return ErrInterrupt } // 执行已注册的任务 task(id) } return nil } // gotInterrupt 验证是否接收到了中断信号 func (r *Runner) gotInterrupt() bool { select { // 当中断事件被触发时发出的信号 case <-r.interrupt: // 停止接收后续的任何信号 signal.Stop(r.interrupt) return true // 继续正常运行 default让select变得不再阻塞 default: return false } }
main 是程序的入口 func main() { log.Println("Starting work.") // 为本次执行分配超时时间 r := runner.New(timeout) // 加入要执行的任务 r.Add(createTask(), createTask(), createTask()) // 执行任务并处理结果 if err := r.Start(); err != nil { switch err { case runner.ErrTimeout: log.Println("Terminating due to timeout.") os.Exit(1) case runner.ErrInterrupt: log.Println("Terminating due to interrupt.") os.Exit(2) } } log.Println("Process ended.") } // createTask 返回一个根据id // 休眠指定秒数的示例任务 func createTask() func(int) { return func(id int) { log.Printf("Processor - Task #%d.", id) time.Sleep(time.Duration(id) * time.Second) }
36.推荐使用系统标准Pool资源池sync.Pool。以下为简单实现
// 包 pool 管理用户定义的一组资源 package pool import ( "errors" "log" "io" "sync" ) // Pool 管理一组可以安全地在多个goroutine 间 // 共享的资源。被管理的资源必须 // 实现 io.Closer 接口 type Pool struct {
// 保证池内的值是线程安全 m sync.Mutex
// 保存共享资源 resources chan io.Closer
// 需要池外人为实现 factory func() (io.Closer, error)
// 标记池是否已经关闭 closed bool } // ErrPoolClosed 表示请求(Acquire)了一个 // 已经关闭的池 var ErrPoolClosed = errors.New("Pool has been closed.") // New 创建一个用来管理资源的池。 // 这个池需要一个可以分配新资源的函数, // 并规定池的大小 func New(fn func() (io.Closer, error), size uint) (*Pool, error) { if size <= 0 { return nil, errors.New("Size value too small.") } return &Pool{ factory: fn, resources: make(chan io.Closer, size), }, nil } // Acquire 从池中获取一个资源 func (p *Pool) Acquire() (io.Closer, error) { select { // 检查是否有空闲的资源 case r, ok := <-p.resources: log.Println("Acquire:", "Shared Resource") if !ok { return nil, ErrPoolClosed } return r, nil // 因为没有空闲资源可用,所以提供一个新资源 default: log.Println("Acquire:", "New Resource") return p.factory() } } // Release 将一个使用后的资源放回池里 func (p *Pool) Release(r io.Closer) { // 保证本操作和Close 操作的安全,和close用的同一个锁,因为不想在往一个已经关闭了的通道发送数据 p.m.Lock() defer p.m.Unlock() // 如果池已经被关闭,销毁这个资源 if p.closed { r.Close() return } select { // 试图将这个资源放入队列 case p.resources <- r: log.Println("Release:", "In Queue") // 如果队列已满,则关闭这个资源 default: log.Println("Release:", "Closing") r.Close() } } // Close 会让资源池停止工作,并关闭所有现有的资源 func (p *Pool) Close() { // 保证本操作与Release 操作的安全,阻止Close和Release同时运行 p.m.Lock() defer p.m.Unlock() // 如果 pool 已经被关闭,什么也不做 if p.closed { return } // 将池关闭 p.closed = true // 在清空通道里的资源之前,将通道关闭 // 如果不这样做,会发生死锁 close(p.resources) // 关闭资源 for r := range p.resources { r.Close() } }
// 这个示例程序展示如何使用pool 包 // 来共享一组模拟的数据库连接 package main import ( "log" "io" "math/rand" "sync" "sync/atomic" "time" ) const ( maxGoroutines = 25 // 要使用的goroutine 的数量 pooledResources = 2 // 池中的资源的数量 ) // dbConnection 模拟要共享的资源 type dbConnection struct { ID int32 } // Close 实现了io.Closer 接口,以便dbConnection // 可以被池管理。Close 用来完成任意资源的 // 释放管理 func (dbConn *dbConnection) Close() error { log.Println("Close: Connection", dbConn.ID) return nil } // idCounter 用来给每个连接分配一个独一无二的id var idCounter int32 // createConnection 是一个工厂函数, // 当需要一个新连接时,资源池会调用这个函数 func createConnection() (io.Closer, error) { id := atomic.AddInt32(&idCounter, 1) log.Println("Create: New Connection", id) return &dbConnection{id}, nil } // main 是所有Go 程序的入口 func main() { var wg sync.WaitGroup wg.Add(maxGoroutines) // 创建用来管理连接的池 p, err := pool.New(createConnection, pooledResources) if err != nil { log.Println(err) } // 使用池里的连接来完成查询 for query := 0; query < maxGoroutines; query++ { // 每个 goroutine 需要自己复制一份要 // 查询值的副本,不然所有的查询会共享 // 同一个查询变量 go func(q int) { performQueries(q, p) wg.Done() }(query) } // 等待 goroutine 结束 wg.Wait() // 关闭池 log.Println("Shutdown Program.") p.Close() } // performQueries 用来测试连接的资源池 func performQueries(query int, p *pool.Pool) { // 从池里请求一个连接 conn, err := p.Acquire() if err != nil { log.Println(err) return } // 将该连接释放回池里 defer p.Release(conn) // 用等待来模拟查询响应 time.Sleep(time.Duration(rand.Intn(1000)) * time.Millisecond) log.Printf("QID[%d] CID[%d]\n", query, conn.(*dbConnection).ID) }
37.work 展示如何使用无缓冲的通道来创建一个goroutine 池,这些goroutine 执行并控制一组工作,让其并发执行。
// work 包管理一个goroutine 池来完成工作 package work import "sync" // Worker 必须满足接口类型, // 才能使用工作池 type Worker interface { Task() } // Pool 提供一个goroutine 池,这个池可以完成 // 任何已提交的Worker 任务 type Pool struct { work chan Worker wg sync.WaitGroup } // New 创建一个新工作池 func New(maxGoroutines int) *Pool { p := Pool{ work: make(chan Worker), } p.wg.Add(maxGoroutines) for i := 0; i < maxGoroutines; i++ { go func() { for w := range p.work { w.Task() } p.wg.Done() }() } return &p } // Run 提交工作到工作池 func (p *Pool) Run(w Worker) { p.work <- w } // Shutdown 等待所有goroutine 停止工作 func (p *Pool) Shutdown() { close(p.work) p.wg.Wait() }
// 创建一个goroutine 池并完成工作 package main import ( "log" "sync" "time" ) // names 提供了一组用来显示的名字 var names = []string{ "steve", "bob", "mary", "therese", "jason", } // namePrinter 使用特定方式打印名字 type namePrinter struct { name string } // Task 实现Worker 接口 func (m *namePrinter) Task() { log.Println(m.name) time.Sleep(time.Second) } // main 是所有Go 程序的入口 func main() { // 使用两个goroutine 来创建工作池 p := work.New(2) var wg sync.WaitGroup wg.Add(100 * len(names)) for i := 0; i < 100; i++ { // 迭代 names 切片 for _, name := range names { // 创建一个 namePrinter 并提供 // 指定的名字 np := namePrinter{ name: name, } go func() { // 将任务提交执行。当Run 返回时 // 我们就知道任务已经处理完成 p.Run(&np) wg.Done() }() } } wg.Wait() // 让工作池停止工作,等待所有现有的 // 工作完成 p.Shutdown() }
38.Test案例,go test -v,-v 冗余打印测试案例日志,测试文件必须以_test.go结尾,测试函数必须是Test为前缀开头。且必须接受一个testing.T类型的指针参数。测试分为基础测试和表组测试
const checkMark = "\u2713" 打印√
const ballotX = "\u2717" 打印×


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
· 零经验选手,Compose 一天开发一款小游戏!