

Java Jvm内存区域定义介绍
本文主要用于个人笔记记录,主要针对jdk1.8
一、Java内存区域(运行时数区)
图片这X掉的是方法区,方法区是JVM的规范,大家可能会搞混永久代和方法区,其实永久代就是Jdk 1.8以前 HotSpot对方法区的实现。
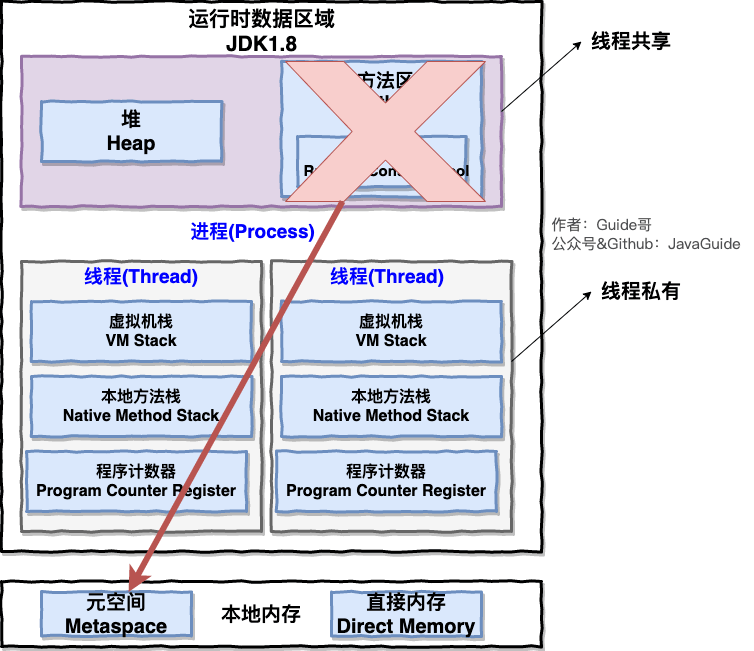
(图片取自java guide)
直接内存是非运行时数据区的一部分。
Java 内存可以粗糙的区分为堆内存(Heap)和栈内存 (Stack)。栈内存大多指的是虚拟机栈中局部变量表部分。
二、线程私有内存区域
先看看线程内的内存区域:
1.程序计数器:用于记录下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完成。为了线程切换后能恢复到正确的执行位置,每个线程的程序计数器都是独立的,这部分线程独立的内存区域称为线程私有。
注意:程序计数器是唯一一个不会出现 OutOfMemoryError 的内存区域,它的生命周期随着线程的创建而创建,随着线程的结束而死亡
2.Java 虚拟机栈:生命周期和线程相同,描述的是 Java 方法执行的内存模型,每次方法调用的数据都是通过栈传递的。
虚拟栈存着一个个栈帧,栈帧包括:局部变量表、操作数栈、动态链接、方法出口信息。
局部变量表,从名字显而易见,是存放执行方法的时候变量的信息,所以主要存放了编译期可知的各种数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。
方法/函数的调用,就是创建相应函数的栈帧压入Java栈,调用结束后,就会有栈帧弹出。
虚拟机栈主要是存放线程执行方法的一个个栈帧,栈帧占用栈多少空间是根据具体方法的参数等信息决定的,虚拟机栈有可能出现StackOverFlowError 和 OutOfMemoryError。
每个线程的栈大小,通过-Xss设置,公司内默认为256k,相同物理内存下,-Xss小,则能生成更多的线程,但操作系统对一个进程的线程是有限制的。-Xss过小,会出现栈溢出,特别是有递归,大的循环的时候;-Xss过大,影响创建栈的数量,如果是多线程应用,会出现内存溢出。
StackOverFlowError: 若 Java 虚拟机栈的内存大小不允许动态扩展(Hotspot不允许),那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出 StackOverFlowError 错误。OutOfMemoryError: Java 虚拟机栈的内存大小可以动态扩展(以前的Classic虚拟机允许), 如果虚拟机在动态扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常。
3.本地方法栈
和虚拟机栈所发挥的作用非常相似,区别是: 虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native (一些c、c++代码编写的代码调用操作系统指令)方法服务。在 HotSpot 虚拟机中本地方法栈和 Java 虚拟机栈合二为一。
异常抛出一样会StackOverFlowError 和 OutOfMemoryError,栈帧也同样是用于存放本地方法的局部变量表、操作数栈、动态链接、出口信息。
三、线程共享区域
1.堆
用于存放对象实例,“几乎”所有的对象实例以及数组都在这里分配内存。
但是,随着 JIT 编译器的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,JDK1.7起默认开启逃逸分析,如果某些方法中的对象引用没有被返回或者未被外面使用(也就是未逃逸出去),那么对象可以直接在栈上分配内存,就不会再分配到堆里。
Java 堆是垃圾收集器管理的主要区域,因此也被称作GC 堆(Garbage Collected Heap)。
从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以 Java 堆还可以细分为:新生代和老年代;再细致一点有:Eden、Survivor、Old 等空间。进一步划分的目的是更好地回收内存,或者更快地分配内存。
JDK 8后PermGen(永久代)已被 Metaspace(元空间) 取代,元空间使用的是直接内存。以前永久代用的是堆内存空间。
大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 S0 或者 S1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁)或者累积的某个年龄对象数量大小超过了 survivor 区的一半时,取这个年龄和 MaxTenuringThreshold 中更小的一个值,作为新的晋升年龄阈值;这些对象就会被晋升到老年代中。对象晋升到老年代的年龄阈值,通过参数 -XX:MaxTenuringThreshold 来设置。
对象流转
对象年龄:0 取对象年龄超过一半的数和MaxTenuringThreshold最小值作为迭代到老年代的阈值并修改 对象年龄:MaxTenuringThreshold
Eden -> S0 或者 S1(看现在标记整理清除使用的是哪个新生代) -> 老年代(Tenured)
堆最容易出现OutOfMemoryError错误。但有好几种:
1.java.lang.OutOfMemoryError: GC Overhead Limit Exceeded:当 JVM 花太多时间执行垃圾回收并且只能回收很少的堆空间时,就会发生此错误。
2.java.lang.OutOfMemoryError: Java heap space :假如在创建新的对象时, 堆内存中的空间不足以存放新创建的对象, 就会引发此错误。(和配置的最大堆内存有关,且受制于物理内存大小。最大堆内存可通过-Xmx参数配置。默认值看VM配置,-client取小于物理内存的 1/4 或 1GB,有的版本不受1GB影响;可以用这个命令查看java -XX:+PrintFlagsFinal -version | grep -iE 'HeapSize|PermSize|ThreadStackSize', -XX:+PrintConmandLineFlags也可以但要看具体jvm。
2.方法区(元空间)
用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。注意:永久代就是 HotSpot 虚拟机对虚拟机规范中方法区的一种实现方式。而jdk1.8后是元空间。
jdk1.8后用这两个命令设置元空间大小,与永久代很大的不同就是,如果不指定大小的话,随着更多类的创建,虚拟机会耗尽所有可用的系统内存。
-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)
-XX:MaxMetaspaceSize=N //设置 Metaspace 的最大大小
为什么要将永久代 (PermGen) 替换为元空间 (MetaSpace) 呢?
《深入理解Java虚拟机》第三版2.2.5提到

1.整个永久代有一个 JVM 本身设置的固定大小上限,无法进行调整,而元空间使用的是直接内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。溢出时会报错:java.lang.OutOfMemoryError: MetaSpace
2.可以使用 -XX:MaxMetaspaceSize 标志设置最大元空间大小,默认值为 unlimited就意味着它只受系统内存的限制。-XX:MetaspaceSize 调整标志定义元空间的初始大小如果未指定此标志,则 Metaspace 将根据运行时的应用程序需求动态地重新调整大小。
3.在 JDK8,合并 HotSpot 和 JRockit 的代码时, JRockit 从来没有一个叫永久代的东西, 合并之后就没有必要额外的设置这么一个永久代的地方了。
3.运行时常量池
方法区一部分。存在方法区的类存储(包括类的版本、字段、方法、接口等描述信息、常量池表)。存放编译期生成的各种字面量和符号引用。
同样因为在方法区中,当运行时常量池无法申请到内存时,会抛出java.lang.OutOfMemoryError。
但字符串常量放到了堆中。
JDK1.8版本的字符串常量池中存的是字符串对象,以及字符串常量值。
几个问题:
1.那么JVM 常量池中存储的是对象还是引用呢?字符串常量池呢?
运行时常量池其中的引用类型常量(例如CONSTANT_String、CONSTANT_Class、CONSTANT_MethodHandle、CONSTANT_MethodType之类)都存的是引用,实际的对象还是存在Java heap上的。字符串常量池则看情况而定。如果使用StringBuilder.append先创建堆对象,后面再intern,则是把常量池中的对象指向堆对象,常量池中也是个引用,普通的情况,字符串常量池是存了一个真的对象。
2.String s = new String("abc")这个语句创建了几个对象?
创建了2个对象,第一个对象是”abc”字符串存储在常量池中,第二个对象在JAVA Heap中的 String 对象(对象存储的就是字符常量池的引用),s指向的就是堆中这个String对象。
详细见此文章:https://blog.csdn.net/wangwenjie1997/article/details/108325863
3.如果是用"+"拼接的字符串呢?
"+"会被替换为采用了StringBuilder进行加号的拼接,只会在堆中创建一个String对象,并不会在常量池中存储对应的字符串。而“+”创建完字符串后,再调用intern做池化,因为JDK7之后对字符串常量池放到了堆中,所以当intern调用时,如果常量池没有这个字符串,就会在常量池中存了堆中对应字符串的引用。
即:当字符串常量池中并不存在对应字符串时,调用intern方法返回的地址为堆中对象的地址。
4.String.intern()方法流程?
5.那么的String.intern如何做到节省内存呢?
比如一个10w次的循环,new String(String.valueOf(sample[i % sample.length])),循环中如果字符串有重复的时候,new String创建都会判断常量池是否有该字面量对象,如果没有,都会创建一个,再创建一个堆中的字符串对象;也就是一直会在堆中创建一个对象指向字符串常量池的字符串对象。但如果用了new String(String.valueOf(sample[i % sample.length])).intern();new String().intern实际上如果字符串常量池有这个字符串对象,就会直接返回常量池的对象引用给到变量,这个过程是不会在 Java 堆中再创建一个 String 对象的。
4.直接内存
直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。也可能导致 OutOfMemoryError 错误出现。
JDK1.4 中新加入的 NIO(New Input/Output) 类,引入了一种基于通道(Channel)与缓存区(Buffer)的 I/O 方式,它可以直接使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆之间来回复制数据。本机直接内存的分配不会受到 Java 堆的限制,但是,是内存就会受到本机总内存大小以及处理器寻址空间的限制。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
· 零经验选手,Compose 一天开发一款小游戏!