

kafka是什么?
Apache Kafka 是一款开源的消息引擎系统(支持可重用、通用的传输消息中间件)。
支持以下模型:
1.点对点(一对一)。2.发布/订阅(多对多)。
同时也是分布式流平台。用于处理两类问题:
1.数据正确性不足。数据收集轮询的间隔时间是一个高度经验化的问题。
2.系统高度定制化(每个子系统对接数据收集模块),维护成本高。
所以kafka 0.10.0.0有如下特征:
1.提供一套API实现生产者和消费者。2.降低网络传输和磁盘存储开销。3.实现高伸缩性架构。
kafka对比其他流式计算框架优势:
1.更容易实现端对端的正确性(Correctness),即精确处理一条消息有且只有一次机会影响系统状态。
2.对于流式计算的定位,提供一套搭建实时流式处理的库,而非一个完整系统。Kafka 提供类似于集群调度、弹性部署等开箱即用的运维特性
为何需要消息引擎?
数据量不大,可以考虑上游限流,但这就导致上游无法达到更高tps。
所以用消息引擎来消峰填谷,由于上游应用处理请求简单,瞬间tps可以很高,但下游处理复杂,就会出现下游无法及时处理上游数据导致堆积,甚至压垮下游服务。
kafka专业术语概念
Topic(主题):一类数据的总称。
Kafka Broker(Broker服务端进程):负责接收和处理客户端发生来的请求,对消息持久化;一个kafka消息引擎集群,由多个Broker组成。
Producer(生产者):向Topic发送消息的客户端应用。
Consumer(消费者):订阅Topic消息的客户端应用。
Replica(副本):备份机制(Replication)中,相同的数据拷贝;
分为Leader Replica(领导者副本:对客户端(consumer、producer)提供服务) 和Follower Replica(追随者副本:主动请求同步领导者副本的数据)。
注意一些概念:数据库Mysql的主从模式:从是可以提供读服务的。而kafka是主备含义。
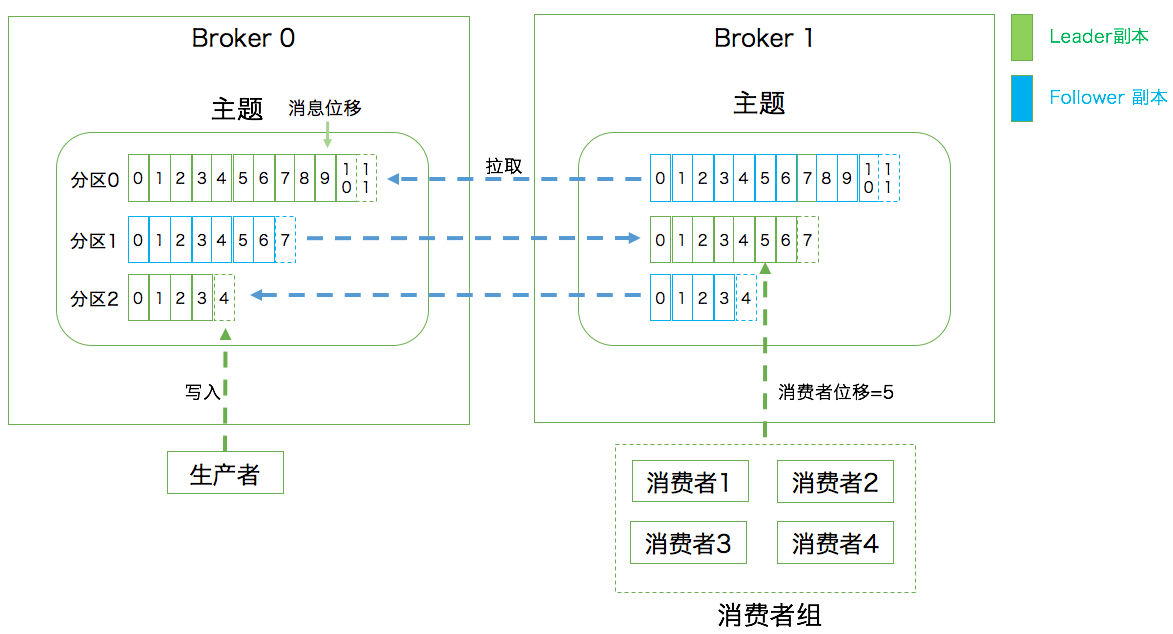
Partition(分区):kafka实现Scalability(伸缩性)的机制。避免leader replica积累太多数据,以至于一个broker无法容纳了。
把一个Topic分为多个Partition。实际上副本是对于分区来说的,每个分区下可以配置若干副本。
Offset(位移):从0开始,针对分区,一旦写入分区则不会变化,表示分区中每条消息的位置信息,是一个单调递增且不变的值。
Consumer Group(消费者组):多个consumer组成一个组消费一组主题。主题每个分区只能被组内一个consumer消费。以实现同时消费这个Topic,提高吞吐。如某个consumer挂掉,会把这个挂掉的consumer负责的分区转移给其他存活的consuemr,这个过程叫ReBalance。
Consumer offset是随时变化的,表示消费进度。
Coordinator 它专门为 Consumer Group 服务,负责为 Group 执行 Rebalance 以及提供位移管理和组成员管理等。
Consumer 端应用程序在提交位移时,其实是向 Coordinator 所在的 Broker 提交位移。同样地,当 Consumer 应用启动时,也是向 Coordinator 所在的 Broker 发送各种请求,然后由 Coordinator 负责执行消费者组的注册、成员管理记录等元数据管理操作。所有 Broker 在启动时,都会创建和开启相应的 Coordinator 组件。也就是说,所有 Broker 都有各自的 Coordinator 组件。
Consumer Group 如何确定为它服务的 Coordinator 在哪台 Broker 上呢,答案是 Kafka 内部位移主题 __consumer_offsets。
第 1 步:确定由位移主题的哪个分区来保存该 Group 数据:partitionId=Math.abs(groupId.hashCode() % offsetsTopicPartitionCount)。offsetsTopicPartitionCount默认是50.
第 2 步:找出该分区 Leader 副本所在的 Broker,该 Broker 即为对应的 Coordinator。
Controller 在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群。集群中任意一台 Broker 都能充当控制器的角色,但只有一个Broker成为控制器,行使其管理和协调的职责。
activeController 的 JMX 指标,可以帮助我们实时监控控制器的存活状态。控制器是重度依赖 ZooKeeper 。
如何选出controller?
Broker 在启动时,会尝试去 ZooKeeper 中创建 /controller 节点。Kafka 当前选举控制器的规则是:第一个成功创建 /controller 节点的 Broker 会被指定为控制器。
控制器的功能:
1.主题管理(创建、删除、增加分区)
2.分区重分配:指kafka-reassign-partitions 脚本提供的对已有主题分区进行细粒度的分配功能。
3.Preferred 领导者选举:Preferred 领导者选举主要是 Kafka 为了避免部分 Broker 负载过重而提供的一种换 Leader 的方案。
4.集群成员管理(新增 Broker、Broker 主动关闭、Broker 宕机):包括自动检测新增 Broker、Broker 主动关闭及被动宕机。这种自动检测是依赖于zookeeper的 Watch 功能和 ZooKeeper 临时节点组合实现的。每个 Broker 启动后,会在 /brokers/ids 下创建一个临时 znode。当 Broker 宕机或主动关闭后,该 Broker 与 ZooKeeper 的会话结束,这个 znode 会被自动删除。
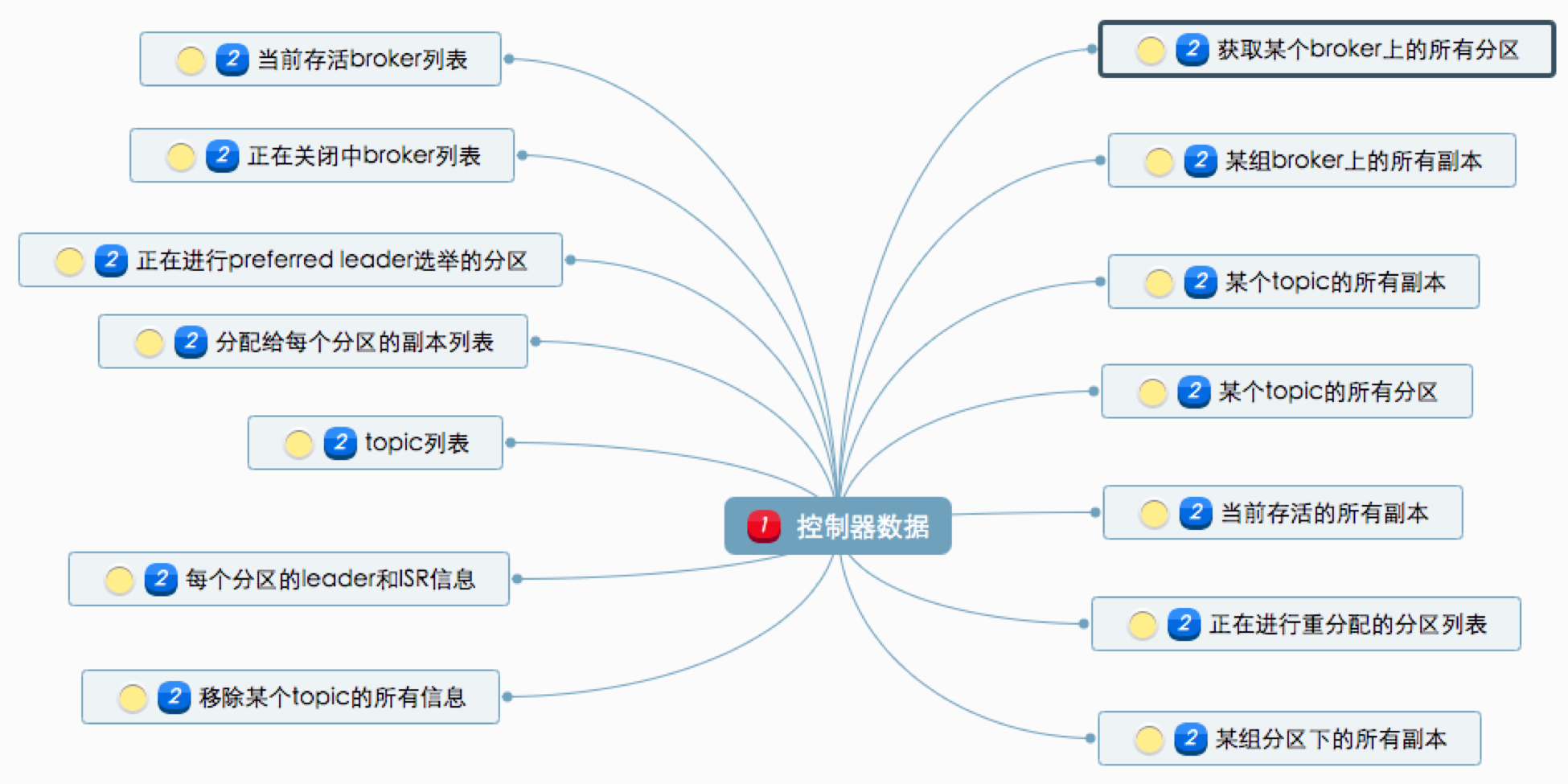
5.数据服务:向其他 Broker 提供数据服务。控制器上保存了最全的集群元数据信息,其他所有 Broker 会定期接收控制器发来的元数据更新请求,从而更新其内存中的缓存数据。
Kafka持久化数据
使用消息日志(Log),即磁盘的一个只能追加写(Append-only)消息的物理文件。追加写用顺序IO避免缓慢随机IO。
使用Log Segment 清理数据,一个日志文件分为多个日志段,消息只能写到当前最新日志段,写满后切分新的日志段,并保存老的日志段。
有定时任务定期检查老的日志段是否可以删除。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
· 零经验选手,Compose 一天开发一款小游戏!