
gNB-DU在下行链路中的 RLC SDU / PDU时延
RLC SDU , PDCP SDU这一整个流程有一张图:
如下图所示无线网络中有着多个(n+1)用户面数据和控制面m个IP 数据包;他们分别由SDAP、PDCP、RLC层出来后,由MAC层组合处理发送。
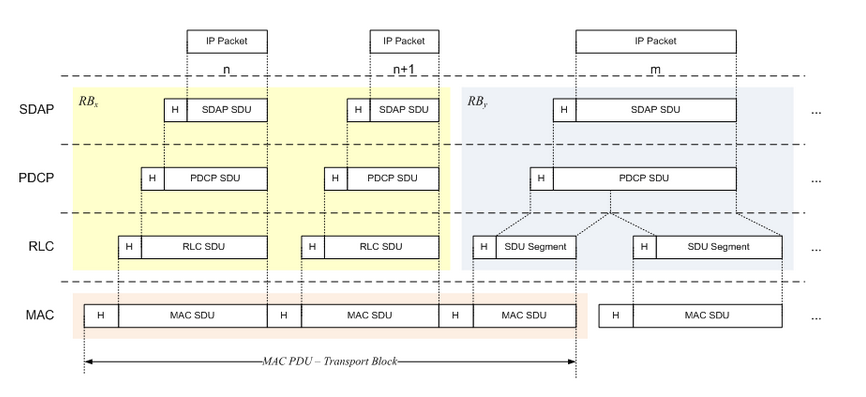
一直不知道这种图居然是3GPP协议里面画的,就在38.300协议里面6.6 L2 Data Flow 章节。 关于协议栈用户面、控制面划分,每层主要功能都是在38.300里面介绍的。
从这个图中可以看出,一个IP包最后形成一个RLC SDU。
RLC(Radio Link Control)层位于PDCP层(或RRC层)和MAC层之间。它通过RLC通道(RLC channel)与PDCP层(或RRC层)进行通信,并通过逻辑信道与MAC层进行通信。RLC配置是逻辑信道级的配置,一个RLC实体(RLC entity)只对应一个UE的一个逻辑信道。RLC实体从PDCP层接收到的数据,或发往PDCP层的数据被称作RLC SDU(或PDCP PDU)。RLC实体从MAC层接收到的数据,或发往MAC层的数据被称作RLC PDU(或MAC SDU)。
这个里面隐含着一层理解:一个RLC实体(RLC entity)只对应一个UE的一个逻辑信道。RLC配置是逻辑信道级的配置。 也就是说谈RLC,一定要先指定我们说的是哪个逻辑信道。 UE建立后可能有多个逻辑信道,每个逻辑信道都对应一个RLC实体。 上层来的数据可能在不同的逻辑信道上发送。 从核心网过来的QOS承载数据会映射到不同的逻辑信道上。所以谈论RLC,就要心里知道有逻辑承载的概念。
RLC层主要负责(见38.322):
- 分段/重组RLC SDU(segmentation / reassembly,只适用于UM和AM模式):在一次传输机会中,一个逻辑信道可发送的所有RLC PDU的总大小是由MAC层指定的,其大小通常并不能保证每一个需要发送的RLC SDU都能完整地发送出去,所以在发送端需要对某个RLC SDU进行分段以便匹配MAC层指定的总大小。相应地,在接收端需要对被分段的RLC SDU进行重组,以恢复出原来的RLC SDU并递送给上层。
注意这个里面说的非常清楚:分段和重组是配套的,发送端有分段,接收端就会需要重组。
- 通过ARQ进行纠错(只适用于AM模式):MAC层的HARQ机制的目标在于实现非常快速的重传,其反馈出错率大概在0.1~1%左右。对于某些业务,如TCP传输(要求丢包率小于10-5),HARQ反馈的出错率就显得过高了。对于这类业务,RLC层的重传处理能够进一步降低反馈出错率。
- 重复包检测(duplicate detection,只适用于AM模式,UM模式不支持重复包检测):出现重复包的最大可能性为发送端反馈了HARQ ACK,但接收端错误地将其解释为NACK,从而导致了不必要的MAC PDU重传。当然,RLC层的重传(AM模式下)也可能带来重复包。
- 对RLC SDU分段进行重分段(re-segmentation,只适用于AM模式):当一个RLC SDU分段需要重传,但MAC层指定的大小无法保证该RLC SDU分段完全发送出去时,就需要对该RLC SDU分段(注意:不是对AMD PDU进行重分段)进行重分段处理。
- RLC SDU丢弃处理(只适用于UM和AM模式):当PDCP层指示RLC层丢弃一个特定的RLC SDU时,RLC层会触发RLC SDU丢弃处理。如果此时没有将该RLC SDU,或该RLC SDU的部分分段递交给MAC层,则AM RLC实体发送端或UM发送端实体会丢弃指示的RLC SDU。也就是说,如果一个RLC SDU或其任意分段已经用于生成了RLC PDU,则RLC发送端不会丢弃它,而是会完成该RLC SDU的传输(这意味着AM RLC实体发送端会持续重传该RLC SDU,直到它被对端成功接收)。当丢弃一个RLC SDU时,AM RLC实体发送端并不会引入RLC SN间隙。
- 在LTE中,只有当MAC层通知RLC实体有一个传输机会,并同时告诉RLC实体在这次传输机会中可传输的RLC PDU的总大小时,RLC层才会分段/串联RLC SDU以生成一个匹配MAC层指定大小的RLC PDU。也就是说,针对一个逻辑信道,一次传输机会只会发送一个RLC PDU,该PDU可能由一个或多个RLC SDU或RLC SDU分段组成。
- 但在NR中,RLC层无需等待MAC层指示的传输机会,直接将每一个RLC SDU构造成一个RLC PDU,即每个RLC SDU对应一个RLC PDU(而在LTE中,通常由多个RLC SDU串联成一个RLC PDU),但RLC PDU要真正发往MAC层还是需要等待MAC层指示的传输机会。对于UM和AM模式而言,当MAC层指示的可发送的所有RLC PDU的总大小无法保证每一个需要发送的RLC SDU都能完整地发送出去时,某个RLC SDU可能被分段,并使用2个或更多个RLC PDU来传输(在不同的传输机会上)。也就是说,针对同一个逻辑信道,一次传输可能会发送多个RLC PDU,且每一个RLC PDU由一个RLC SDU或RLC SDU分段组成。
简单地说,在NR中,对于UM和AM模式而言,RLC层从PDCP层接收到一个RLC SDU后,可立即生成一个RLC PDU(包含了头部信息),并保存在传输buffer中(即在收到MAC层指定的传输机会之前,预先生成RLC PDU,其目的是为了降低时延)。等到MAC层指示对应逻辑信道有一个传输机会,并同时指定了这次传输机会中对应逻辑信道可传输的数据量时,MAC层会将该逻辑信道对应的传输buffer中的RLC PDU串联起来。但MAC层指定的大小未必能够保证参与串联的每一个RLC PDU都完整地发出去。如果参与串联的最后一个RLC PDU大于剩余的数据量时,该RLC PDU对应的RLC SDU就需要被分段,并重新生成RLC头部以及新的RLC PDU(包含了此RLC SDU的部分数据)。
也就是说,在NR中,RLC层移除了RLC SDU的串联(concatenation)功能(在LTE中,允许将多个RLC SDU或RLC SDU分段串联在一起生成一个RLC PDU,而这在NR中是不支持的),而是由MAC层负责对RLC PDU进行串联,其目的是为了使RLC和MAC层能够提前进行预处理(pre-processing),以减少处理时延。这与LTE的上行传输中,为了构造TB,RLC PDU和MAC PDU需要等接收到UL grant之后才能够生成是不同的。
在LTE中,MAC层的HARQ操作可能导致到达RLC层的报文是乱序的,所以需要RLC层对数据进行重排序(reordering),并按序将重组后的RLC SDU发送给PDCP层,也就是说,RLC SDU n必须在RLC SDU n+1之前发送给PDCP层。但是RLC层的按序递送可能会给PDCP层的解密操作带来较大的时延。假如RLC层在SDU n之前成功接收到了SDU n+1,那么PDCP层需要等到RLC层收到RLC SDU n并递送给PDCP之后才能收到RLC SDU n+1。
在NR中,移除了RLC层的重排序功能,即RLC层不支持按序递送RLC SDU给PDCP层。RLC层在收到一个完整的RLC SDU后,就立即递送给PDCP层处理(PDCP层可以提前做解密操作),而无需关心之前的RLC SDU是否已经成功接收到,从而降低了RLC层的处理时延。也就是说,RLC层送往PDCP层的数据可能是乱序的,数据的按序递送(包括重排序)由PDCP层来负责。
上面例子来自于:https://blog.csdn.net/weixin_37786938/article/details/86563715
整体上来说,NR RLC相对LTE而言取消了两个功能:
1:RLC 取消了级联功能,这个功能下放到了MAC。MAC会去组装所有的RLC SDU。
2:RLC 取消了重排序功能,这个功能上移到了PDCP。

参考:
https://blog.csdn.net/weixin_37786938/article/details/86563715

 浙公网安备 33010602011771号
浙公网安备 33010602011771号