
MySQL(一)
常用命令
登录mysql
mysql [-h 主机名 -P 端口号] -u root -p
MySQL中,每条命令以;作为结束符。
列出数据库
SHOW DATABASES;
选中要使用的数据库
use 数据库名;
显示当前选择的数据库内可用表的列表。
show tables from 表名;
返回指定表的个字段信息
show columns from 表名;
或
describe 表名;
来显示服务器错误或警告消息
show errors;
show warnings;
建表
create table 表名(
属性1 类型,
属性2 类型,
);
增删改查
insert into 表名 values(value1, value2); -- 增加数据
delete from 表名 where 删除条件; -- 删除表中项目
update 表名 set 属性=value where 更新条件; -- 修改项目
select *(其他查询条件) from 表名; -- 查询项目
Data Define Language
查询
基础查询
如果没有明确排序查询结果,则结果是无序的。
空格是无意义的。
SELECT 字段1, 字段2··· FROM 表名; -- 检索指定列
SELECT * FROM 表名; --检索表中全部列
DISTINCT关键字
在查询时,如果只想得到某个字段不同的取值,那么可以加上该关键字。
如下所示得到的查询结果就都是不重复的。
SELECT DISTINCT 字段1,字段2 FROM 表名;
LIMIT关键字
用于限制查询结果得到的行数
SELECT * FROM 表名 LIMIT m,n; --从第m个数据开始显示,显示n条,m,n>=0,整
排序查询
ORDER BY以及DESC
SELECT 字段1, 字段2··· FROM 表名 ORDER BY 字段1,字段2 DESC;
-- ORDER BY表名按说明顺序进行排列;
-- DESC表明按照字段2降序, 默认升序, DESC只作用于前一个字段;
-- 如果想在多个列上进行降序排序,必须对每个列指定DESC关键字。
ORDER BY必须在FROM后, 使用LINIT也必须在ORDER BY之后.
过滤数据
WHERE
SELECT * FROM 表名 WHERE 过滤条件; -- 若使用ORDER BY, 应处在WHERE的后面
WHERE后面衔接的过滤条件子句可以是:
- 字段 = (> , < , !=, >=, <=)value
- 字段 BETWEEN m AND n
- 字段 IS NULL
组合WHERE
AND和OR 连接WHERE后得到多个条件,需注意优先级,AND高于OR。
IN,用于控制WHERE后面字段选取范围。
SELECT * FROM 表名 WHERE 属性 [NOT] IN 条件; -- 这里的条件可以是一个范围,不过更常是另一个SELECT clause
MySQL支持使用NOT对IN、BETWEEN和EXISTS子句取反,这与多数其他DBMS允许使用NOT对各种条件取反有很大的差别。
通配符
搭配LIKE使用
-
%通配符
SELECT * FROM 表名 WHERE 属性 LIKE S%; -- 模糊查找,对应属性以S开头的所有行 -- %代表任意字符(串) -
_下划线通配符
SELECT * FROM 表名 WHERE 属性 LIKE S_B; -- 模糊查找,对应属性以S开头B结尾中间只有一个字符的所有行 -- _只代表单个任意字符
正则表达式
使用 REGEXP说明自己要使用正则表达式。
SELECT * FROM 表名 WHERE 属性 REGEXP 'regular expression';
-- 表示OR ”|“
[abc]edg,表示匹配abc中的某一个字符+edg
[^abc]用于排除abc,匹配他们以外的东西。
1,匹配到的都以a或b或c开头。
[0-9a-z]也是可接受表达式。
匹配特殊字符时,使用 **\\**进行转义。
计算字段
CONCAT—拼接字段
使用CONCAT将查询结果按一定顺序组合起来。
SELECT (sname, sno) FROM 表名 WHERE 条件; -- 将sname字段和sno字段组合在一起
AS—使用别名
SELECT (sname, sno) AS StuInfo FROM 表名 WHERE 条件; -- StuInfo作为sname和sno组合信息的名称
函数
处理查询数据,一般函数使用在SELECT后的查询字段前,如
SELECT UPPER(sname), sno FROM 表名 WHERE 条件; -- 将sname转为大写字母
-
数值处理函数
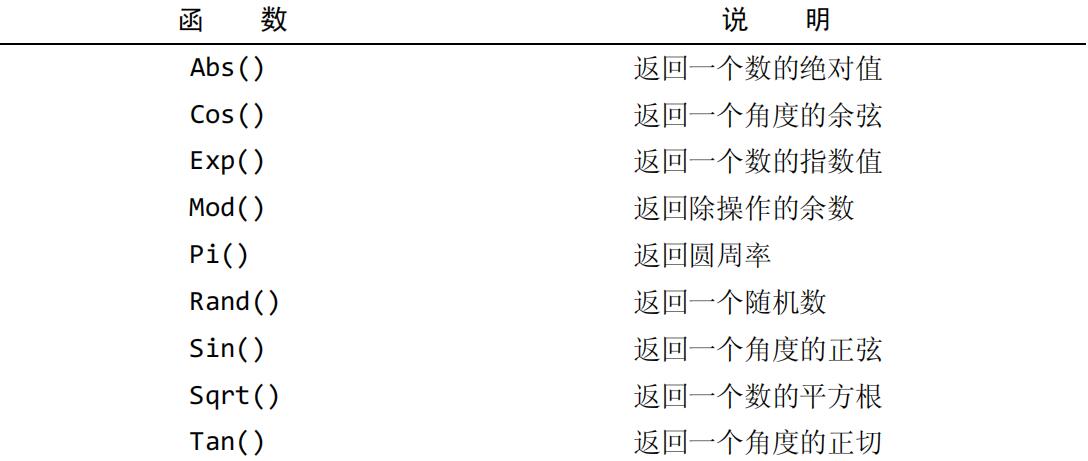
-
文本处理函数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tCaEqnC1-1625659773547)(https://gitee.com/man-ljw/PicBed/raw/master/QQ截图20210705152714.jpg" style=“zoom:70%;”)]
-
日期时间函数
时间比较可以直接使用大于号小于号。
-- 找出入职时间早于2000-01-12的员工的id SELECT employee_id FROM employees WHERE hiredate<DATE_FORMAT('2002-02-12','%y-%m-%d');
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xhDZ3bRc-1625659773549)(https://gitee.com/man-ljw/PicBed/raw/master/QQ截图20210705152826.jpg "style=“zoom:70%”)]
汇总数据
聚集函数
| 函数 | 功能 |
|---|---|
| AVG() | 取某个字段的平均值 |
| COUNT() | 返回某个字段的行数 |
| MAX() / MIN() | 返回某字段的最大 / 最小取值 |
| SUM() | 返回某字段之和 |
例如
SELECT AVG(salary) AS avg_salary FROM employees; -- 查看员工平均薪资
SELECT COUNT(salary) AS count_employee FROM employees; -- 查看总员工数
SELECT MAX / MIN(salary) AS salary_employee FROM employees; -- 查看员工薪资最大最小值
SELECT MAX / MIN(salary) AS sum_employee FROM employees; -- 对薪资数求和
SUM和COUNT区别:
前者用于求和,后者用于计数。
分组数据
GROUP BY
在我创建的数据库中,如果要查询每个工种的平均薪资,就需要将不同的工种进行分组,如
SELECT job_id,MAX(`salary`) FROM `employees` GROUP BY job_id; -- 查看各个工种的平均薪资
HAVING
SELECT job_id,COUNT(*) AS orders
FROM `employees`
GROUP BY job_id
HAVING COUNT(*)>5;
-- 查询人数大于5的工种
HAVING和WHERE的差别 :WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。
WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
语序
| SELECT | 进行搜索 |
|---|---|
| FROM | 要检索的表 |
| WHERE | 行级过滤 |
| GROUP BY | 分组 |
| HAVING | 分级过滤 |
| ORDER BY | 排序 |
| LIMIT | 检索的范围 |
子查询
就是嵌套在其他查询里的查寻。。
如
SELECT employee_id
FROM employees
WHERE job_id IN(
SELECT job_id
FROM jobs
WHERE max_salary > 10000);
-- 查询了最大薪资大于10000的部门中的所有员工编号
-- 执行时,由内向外
相关子查询
涉及到外表的查询,应使用表名.字段名指明每次查询的对象。
用到的数据库表项

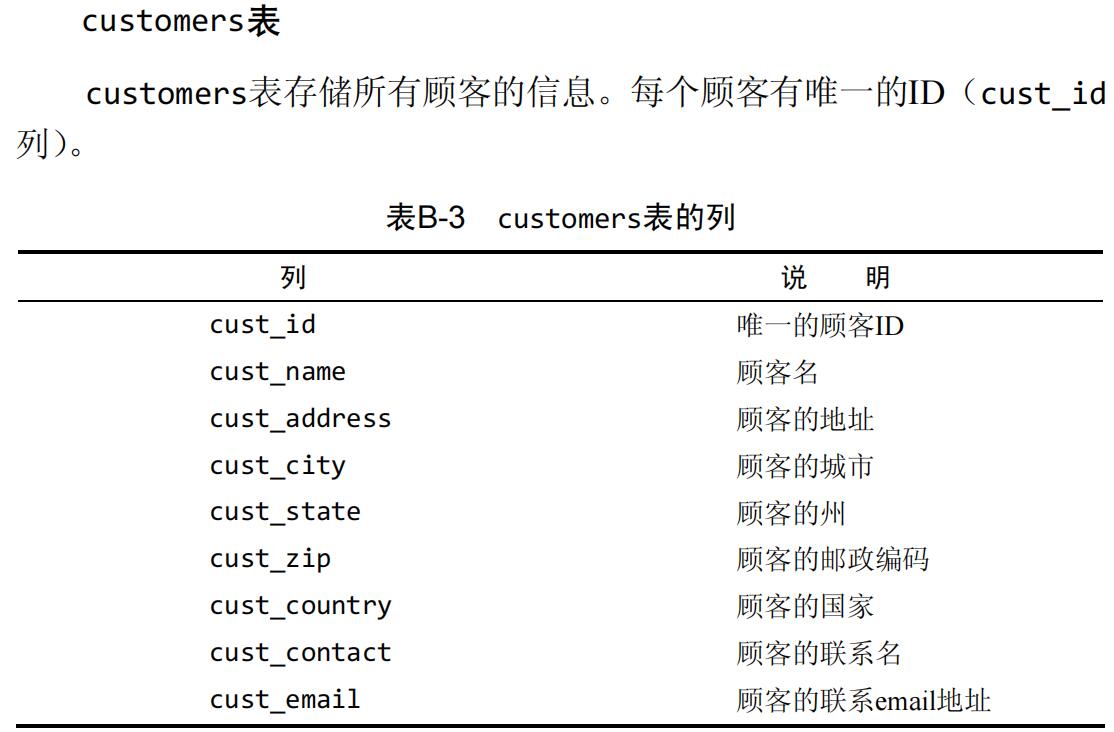




abc ↩︎
本文来自博客园,作者:klaus08,转载请注明原文链接:https://www.cnblogs.com/klaus08/p/15105016.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号