
python爬虫爬取爱奇艺电影数据并存入excel
代码中用了bs4和requests这两个包,这里主要提供下代码,视频教程我建议去https://www.bilibili.com/video/av14109284/?p=1观看,个人觉得课程很棒!
from bs4 import BeautifulSoup
import requests
import time
import xlwt
urls = ['http://list.iqiyi.com/www/1/4-------------11-{}-1-iqiyi--.html'.format(str(i)) for i in range(1,2)]
def get_webData(url):
data_info = []
time.sleep(3)
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
titles = soup.select('div.site-piclist_info > div.mod-listTitle_left > p > a')
imgs = soup.select('div.site-piclist_pic > a > img')
actors = soup.select('div.site-piclist_info > div.role_info')
spans = soup.select('div.site-piclist_info > div.mod-listTitle_left > span')
for title,img,actors,span in zip(titles,imgs,actors,spans):
data = {
'title':title.get_text(),
'img':img.get('src'),
'actors':list(actors.stripped_strings),
'span':span.get_text()
}
#print(data)
dataVal_list.append(data.values())
data_info.append(data)
#print(list(data.keys()))
for m,n in enumerate(list(data.keys())):
sheet.write(0,m,n)
for i,p in enumerate(dataVal_list):
for j,q in enumerate(p):
#print(q)
sheet.write(i+1,j,q)
return data_info
def main():
for url in urls:
data_info = get_webData(url)
#print(data_info)
print('---------------------------\n')
if __name__ == '__main__':
f = xlwt.Workbook(encoding='utf-8')
sheet = f.add_sheet('Movies')
dataVal_list=[]
main()
f.save('Movies.xls')
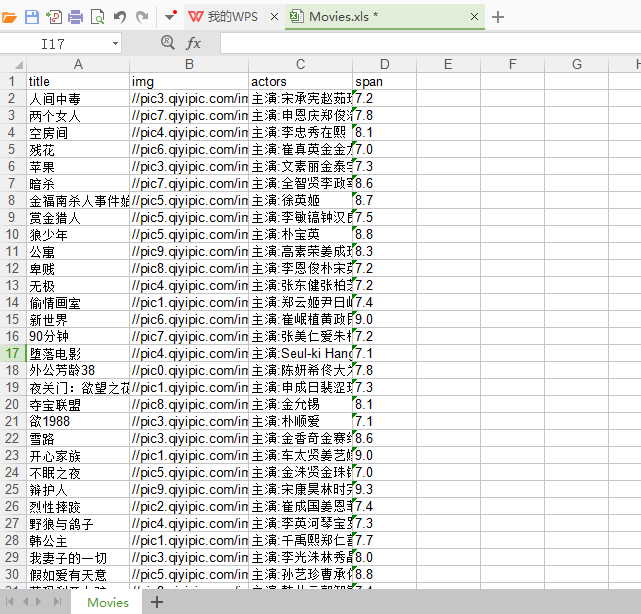
这里存在一个小问题就是写数据到excel中这里的代码只能写一页数据进去,后面会报错因为sheet.write()这个函数前两个参数代表excel中的行和列,这部分数据处理放在函数中会导致每次执行这个函数时sheet.write()中的行和列都是从0开始,所以会报错。爬取信息的代码是没有问题的,爬取不同页需要去观察网址的区别。下面贴上excel文件的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号