
机器学习python实战----k近邻算法
前一周学习了一些理论的知识,虽然懂了原理,但感觉真要写起代码来还是摸不着头脑,所以接下来的几天都打算在代码方面下一番功夫。由于接触python不久,且能力有限,难免有些错误的或者理解不到位的地方,希望读者不吝指正!
K-近邻算法(k-NN)的基本原理:存在一个样本数据集合,也叫训练样本集,并且样本集中的每个数据都存在标签,就是我们知道每个数据与所属分类的对应关系。输入没有标签的新数据后,我们将新数据的特征跟样本集中每个数据对应的特征进行比较,选择特征最相似的(最近邻)的分类标签认为是新数据的标签。一般来说我们只选择样本数据集中前k个最相似的数据,这就是k-近邻的出处。
接下来我们进入代码实战,首先用一个简单的kNN的例子来上手:
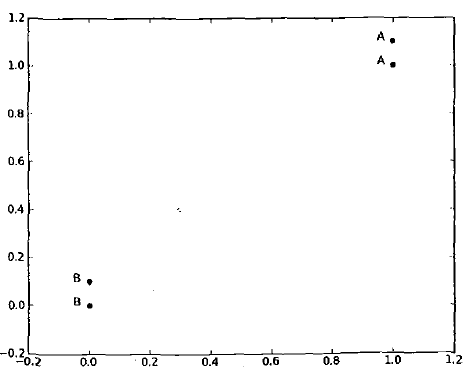
第一步,我们创建一个小的数据集,python代码如下。这是带有标签的四个数据点
from numpy import * import operator def createDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels = ['A','A','B','B'] return group,labels
有了数据集之后,我们接着来对新数据进行分类,看代码
def classify0(Inx,dataSet,labels,k): dataSetSize = dataSet.shape[0] #.shape[0]表示dataSet的行数 diffMat = tile(Inx,(dataSetSize,1))-dataSet #某个点与数据集中点的x和y的坐标差 sqdiffmat = diffMat**2 sumdiffmat = sqdiffmat.sum(axis=1) #对sqdiffmat的行求和即(x-x1)^2+(y-y1)^2 dis = sumdiffmat**0.5 #求平方根即距离 sortdis = dis.argsort() classDict = {} #定义一个存储字典 for i in range(k): keylabels = labels[sortdis[i]] classDict[keylabels] = classDict.get(keylabels,0)+1 sortclassDict = sorted(classDict.items(),key = operator.itemgetter(1),reverse = True) #.items()方法是将classDict这个存储字典转化为list,operator.itemgetter(1)是按classDict的第一项排序 #reverse = True表示降序排列即从大到小 return sortclassDict[0][0]
这个函数classify0有四个输入参数,Inx表示分类的输入向量,dataSet表示训练数据集,labels表示标签向量,k表示取前k个最相似(最相近)的向量。这个函数是计算输入向量与训练数据集的欧式距离,然后对距离进行排序并选择前k个最小的距离,对这些类别进行统计,返回类别多的标签作为新数据的标签。classDict是定义的一个空的存储字典,.argsort()函数是对距离进行排序并返回从小到大排列的序号,注意,这里返回的序号就是已经排列好的(从小到大),所以在后面取sortdis[i]的时候就是前k个最小距离了。这个问题要注意一下,我这里想了很久才想明白,所以有必要提醒一下。之后的sorted()函数是按统计的标签数的多少降序排列,所以sortclassDict[0][0]就是统计标签数最多的类别了。
有了这两个程序我们就可以进行测试啦,结果如图,测试(1,1)这点属于'A'类
做完这个小例子,接下来我们就要对文件数据进行操作,首先需要从文本中解析数据,这样的一个文本dataSet_kNN.txt中存在1000行、4列数据,前三列为特征向量,最后一列为标签。我们需要将特征向量和标签分开放入两个矩阵中,代码如下:
def file2mat(filename): fr = open(filename) listoffile = fr.readlines() #一次性读取文本的所有内容并以list形式返回 numoflines = len(listoffile) #得到文件的行数 newfacMat = zeros((numoflines,3))#创建一个行数*3的零矩阵 newclassVec = [] #创建一个类的向量 index=0 for line in listoffile: line = line.strip() #strip函数用来截断所有的回车符 listfromline = line.split('\t')#以'\t'进行分割 newfacMat[index,:] = listfromline[0:3] newclassVec.append(int(listfromline[-1])) index+=1 return newfacMat,newclassVec
一些函数的功能我注释出来了,可以自己先new一个短的txt文件去测试这些函数,确保功能正常。运行结果如下:
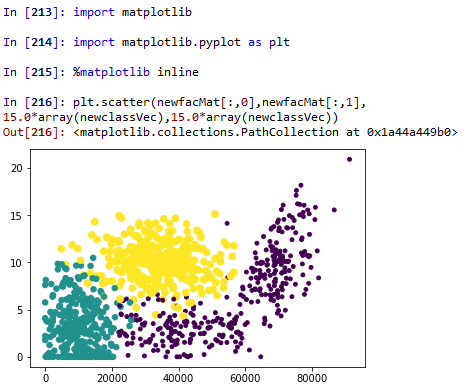
我们可以根据特征向量画出散点图,这里是特征向量第0列和第1列。
下面进行数据的归一化。这里就是我们之前在理论部分说的归一化是一个道理,不能让特征向量之间的差值太大而影响我们的结果,所以要进行归一化,公式也跟之前一样:newValue=(value-min)/(max-min)。代码如下:
def autoNorm(dataSet): valueMax = dataSet.max(0) valueMin = dataSet.min(0) Value_range = valueMax-valueMin normdataSet = zeros(shape(dataSet)) m = dataSet.shape[0] normdataSet = dataSet-tile(valueMin,(m,1)) normdataSet = normdataSet/tile(Value_range,(m,1)) return normdataSet,Value_range,valueMin
到这里我们的kNN算法需要的函数就完了,下面介绍一个评价该算法的方法。这里将样本数据分为训练数据集和测试数据集(8:2),错误率定义为 预测错误的总数/测试样本总数
def datingSetTest(): h = 0.2 newfacMat,newclassVec = file2mat(r'dataSet_kNN.txt') normMat,value_range,value_min = autoNorm(newfacMat) m = normMat.shape[0] numTestData = int(m*h) #测试向量的总数 error_cnt=0 for i in range(numTestData): result = classify0(normMat[i,:],normMat[numTestData:m,:],newclassVec[numTestData:m],5) print('the result is %d,the real answer is %d\n'%(result,newclassVec[i])) if result!=newclassVec[i]: error_cnt+=1 print('the error rate is %f\n'%(error_cnt/float(numTestData)))
前百分之二十的数据作为测试样本,当然这里的测试样本是需要随机选取的,由于文本文件中就是随机的,我们这里取前20%,剩下的作为训练样本。k取5。如果预测的标签跟实际的标签不符合,就令预测错误的总数+1。
结果为
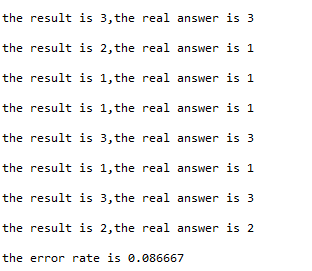 这里的错误率为8.6%。
这里的错误率为8.6%。
k-NN算法到这里就介绍的差不多了,说简单也不简单,说复杂好像也没多少步骤,最关键的是自己要去想,要去做,才能更好的掌握!
这里贴上代码及文本文件的下载链接 http://pan.baidu.com/s/1o7Pi9JG

 浙公网安备 33010602011771号
浙公网安备 33010602011771号