


【慕课网实战】Spark Streaming实时流处理项目实战笔记十五之铭文升级版
铭文一级:[木有笔记]
铭文二级:
第12章 Spark Streaming项目实战
行为日志分析:
1.访问量的统计
2.网站黏性
3.推荐
Python实时产生数据
访问URL->IP信息->referer和状态码->日志访问时间->写入到文件中
本地与虚拟机都要装了python才能运行
重要代码:
#coding=UTF-8
#数组最后一个没有“,”
url_paths = [ "class/128.html", "class/112.html", "class/143.html", "class/141.html", "learn/821", "course/list" ]#增强for循环
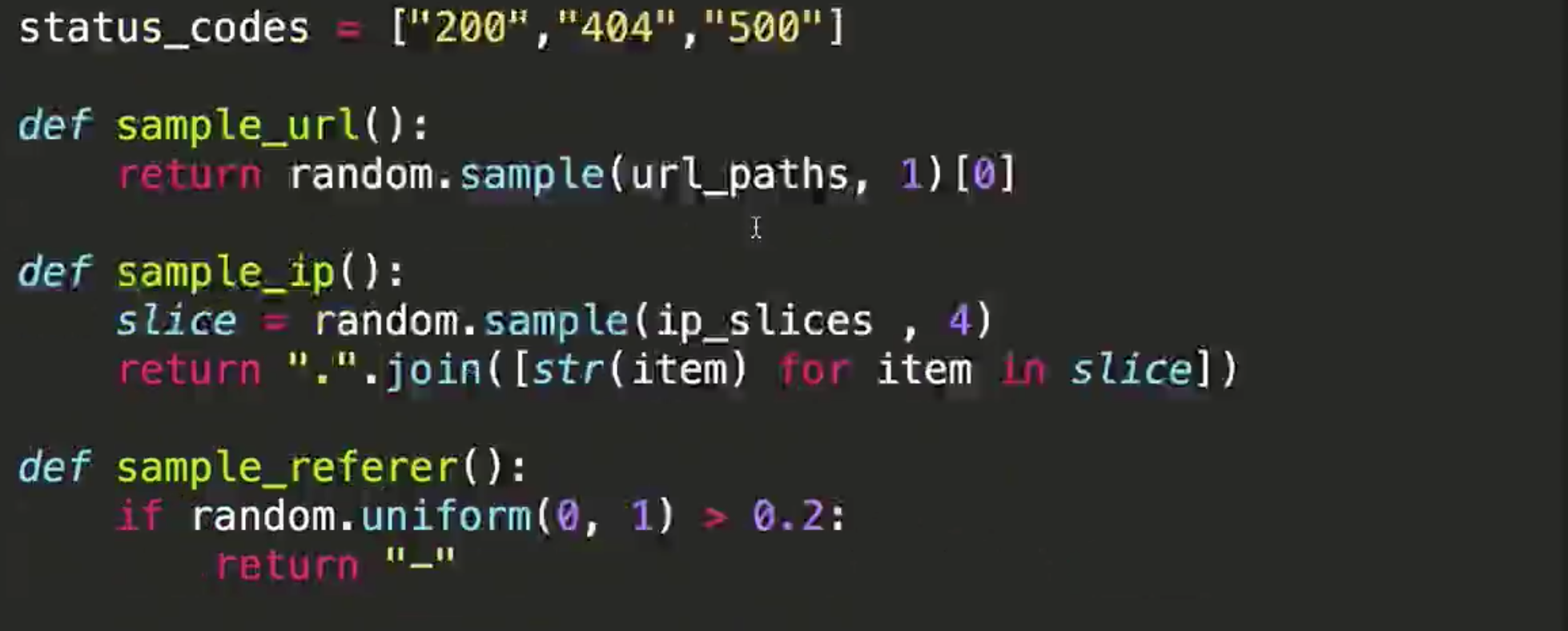
#sample(seq, n) 从序列seq中选择n个随机且独立的元素;
return ".".join([str(item) for item in slice])
def sample_url()
return random.sample(url_paths,1)[0]
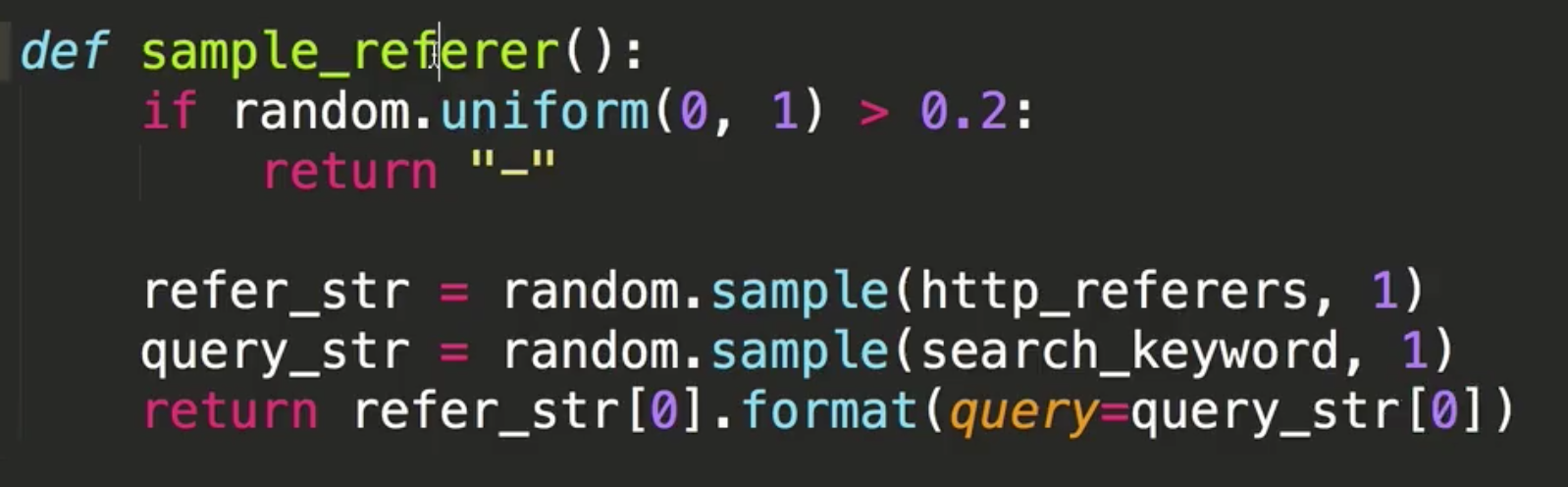
query_log = "{url}".format(url=sample_url())
if __name__ == '__main__':
main()
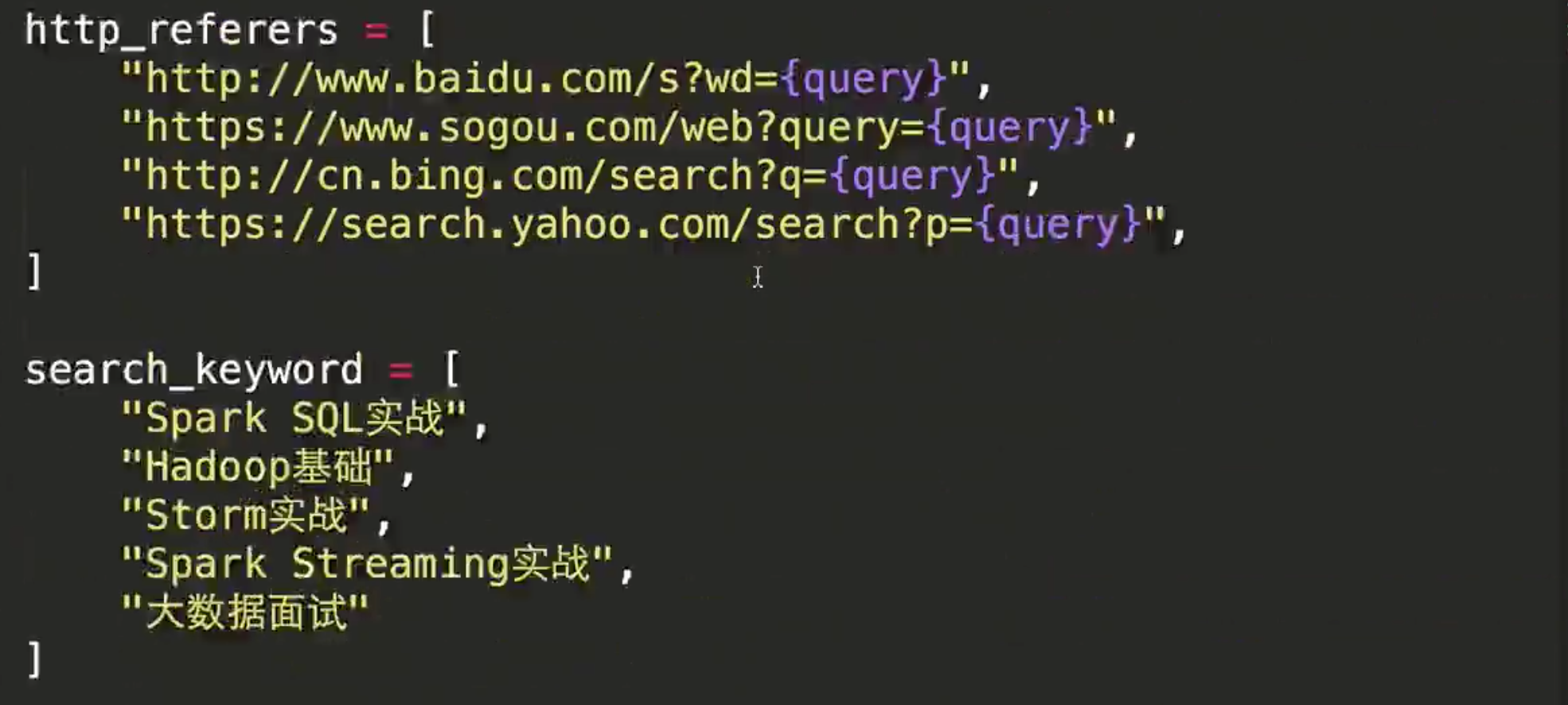
http_referers =[
"http://www.baidu.com/s?wd={query}",
"http://www.sogou.com/web?query={query}",
"http://cn.bing.com/search?q={query}",
"http://search.yahoo.com/search?p={query}"
]
time_str = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
前面要:
import time
import random
将文件输出到一个文件:
f = open("/home/hadoop/data/project/logs/access.log","w+")
f.write(query_log + "\n")
上部分参考代码:
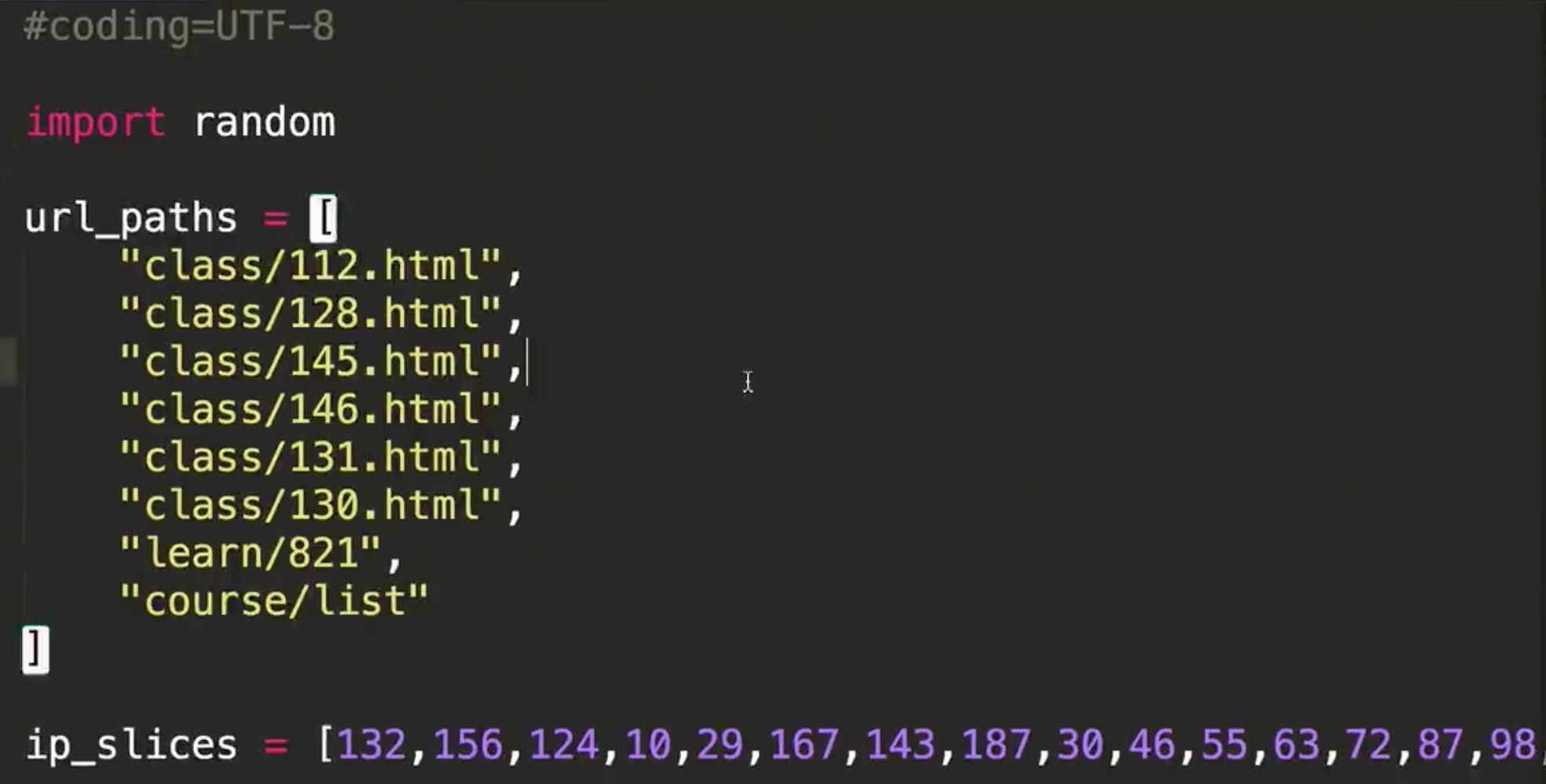
 貌似多了个逗号!!!
貌似多了个逗号!!!
下部分参考代码:
refer_str = random.sample(http_referers, 1)
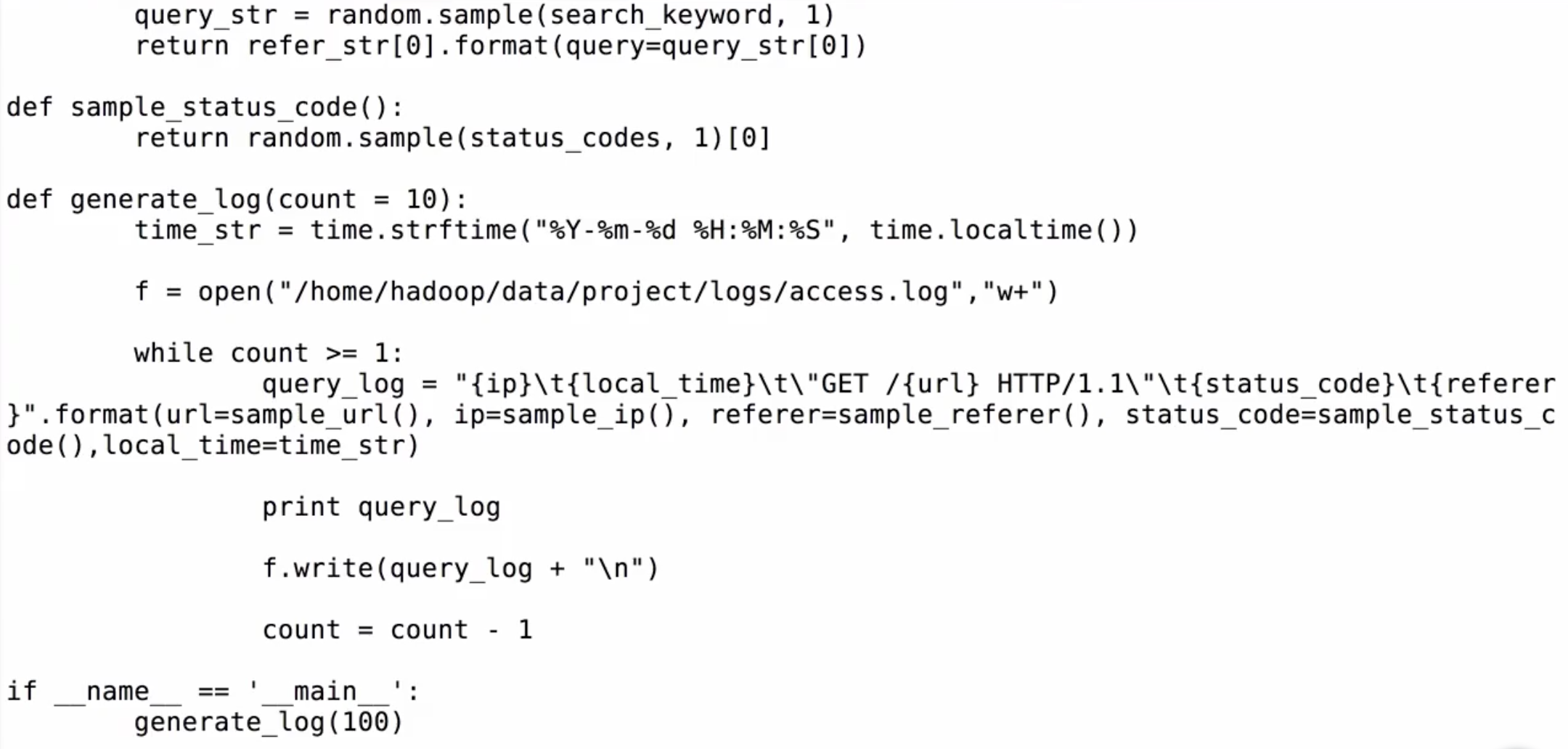
代码编辑完后,需要先创建一个logs文件夹
然后执行py文件,到logs文件夹可查看到产生的数据
查看多少条信息指令:wc -l access.log
动态添加:tail -200f access.log //然后再执行一次
铭文三级:
一张图让你学会Python基础语法(看不清可另存为):
http://blog.csdn.net/qq_30845505/article/details/51588423
python编程中的if __name__ == 'main': 的作用和原理
http://www.dengfeilong.com/post/60.html
str() 函数将对象转化为适于人阅读的形式
>>>s = 'RUNOOB'
>>> str(s)
'RUNOOB'
>>> dict = {'runoob': 'runoob.com', 'google': 'google.com'};
>>> str(dict)
"{'google': 'google.com', 'runoob': 'runoob.com'}"
>>>
但此处 ([str(item) for item in slice])意思是将数字数组转为字符数组
uniform() 方法将随机生成下一个实数,它在 [x, y) 范围内。
format函数的使用
age = 25
name = 'Caroline'
print('{0} is {1} years old. '.format(name, age)) #输出参数
print('{0} is a girl. '.format(name))
print('{0:.3} is a decimal. '.format(1/3)) #小数点后三位
print('{0:_^11} is a 11 length. '.format(name)) #使用_补齐空位
print('{first} is as {second}. '.format(first=name, second='Wendy')) #别名替换
print('My name is {0.name}'.format(open('out.txt', 'w'))) #调用方法
print('My name is {0:8}.'.format('Fred')) #指定宽度
输出:
