数据库系统概论笔记(9)
第9章关系查询处理和查询优化
查询处理:增删改查
查询优化:包括代数优化(逻辑优化)、物理优化(非代数优化)
9.1关系数据库系统的查询处理
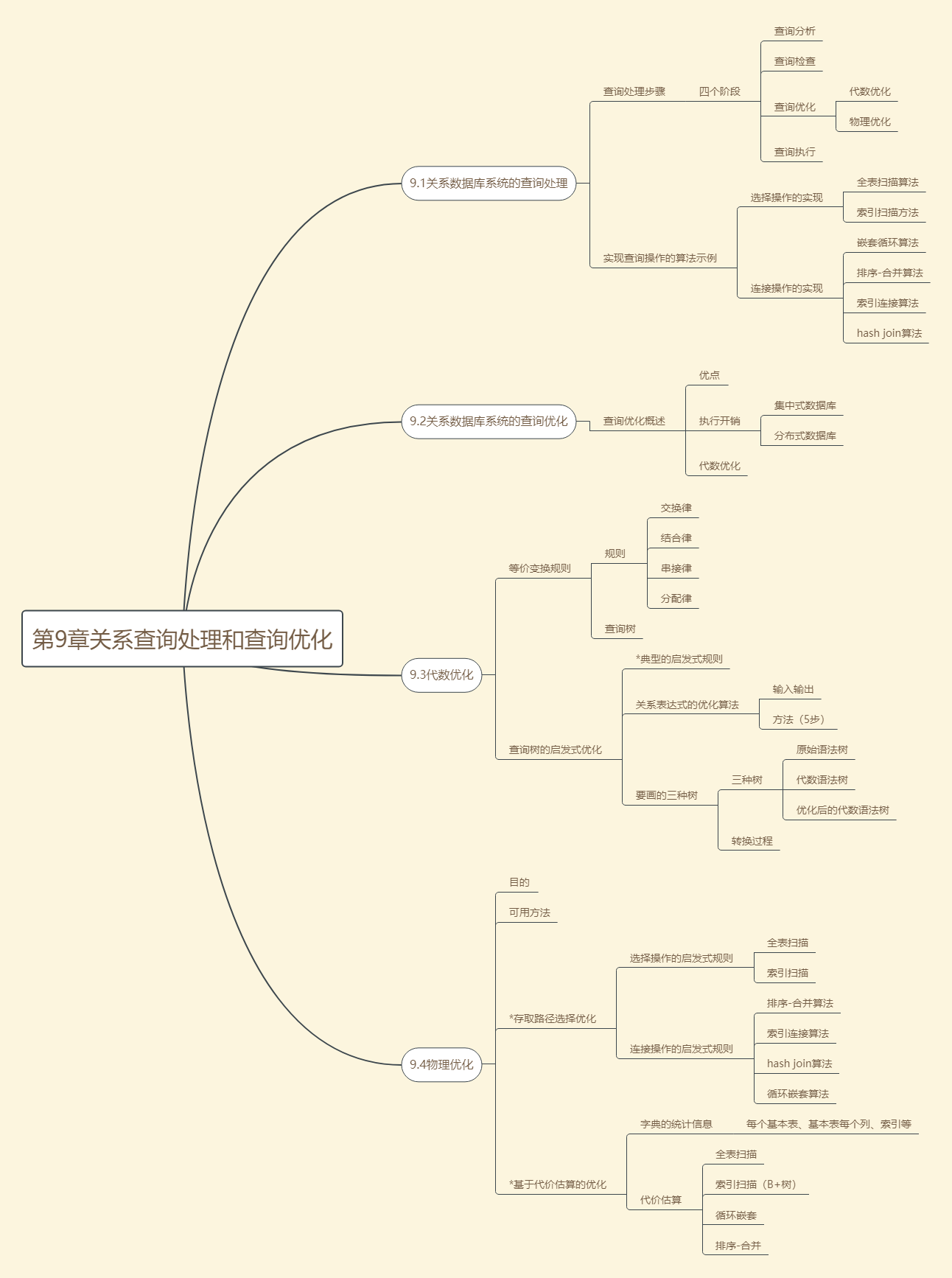
查询处理步骤
查询处理的四个阶段:查询分析、查询检查、查询优化、查询执行
- 查询分析:对查询语句进行扫描、词法分析和语法分析
- 查询检查:包括合法权检查、视图转换、完全性检查、完整性初步检查
- 查询优化:选择一个高效执行的查询处理策略
代数优化:关系代数表达式的优化
物理优化:存取路径和底层操作算法的选择(选择依据有基于规则、基于代价、基于语义) - 查询执行:代码生成器生成查询代码,执行代码,回送查询结果
实现查询操作的算法示例
选择操作的实现:
- 全表扫描算法:
对基本表顺序全部扫描
适合小表,不适合大表 - 索引扫描方法:
索引找到元组指针,根据指针在基本表中找到元组
适于选择条件中的属性上有索引(B+树索引、hash索引等)
(当选择率低时基于索引的选择算法比较好,当选择率比较高时全表扫描算法比较好)
连接操作的实现:
(最常用最耗时的操作之一)
- 嵌套循环算法:
最简单可行的算法
全表选择是嵌套循环算法
时间复杂度:
(n1是R表的元组数,n2是S表的元组数,n3是合并后表的元组数) - 排序-合并算法:
等值连接最常用的算法
*时间复杂度:
(扫R表+R表扫描无效+S表扫描有效+连接+S表排序+R表排序) - 索引连接算法:
步骤:
SC表上有Sno的索引
对Student中的每个元组,由Sno值通过Sc的索引查找相应的SC元组
把SC元组和Student元组连接起来
时间复杂度:(不管原理) - hash join算法:
把连接属性作为hash码,用同一个hash函数把Student表和SC表中的元组散列到hash表中,再根据hash表进行等值连接
*时间复杂度:(M是内存块大小,不管原理)
9.2关系数据库系统的查询优化
查询优化概述
优点:
- 用户不必考虑如何最好的表达查询以获得较好的效率
- 系统可以比用户程序的“优化”做得更好
执行开销:
- 集中式数据库:总代价 = I/O代价+CPU代价+内存代价
- 分布式数据库:总代价 = I/O代价+CPU代价+内存代价+通信代价
代数优化:有选择和连接操作时,先做选择操作(这样参加连接的元组可以大大减少)
9.3代数优化
关系代数表达式等价变换规则
目的:通过对关系代数表达式的等价变换来提高查询效率
等价变换规则(要会相应的查询树转换):
- 交换律:
连接与笛卡尔积、选择与投影、选择与笛卡尔积 - 结合律:
连接与笛卡尔积 - 串接律
选择、投影 - 分配律:
选择与并、选择与差、选择与自然连接、投影与笛卡尔积、投影与并
查询树:
- 叶子是关系表达式
- 自底向上阅读,最顶上的结果为查询结果
- 几目运算符就只能有几个分叉(向下的分叉)
查询树的启发式优化
典型的启发式规则:
- 选择尽早做
- 选择投影同时进行
- 投影结合前后的的双目运算
- 选择结合前面的笛卡尔积(形成连接)
- 找公共子表达式
关系表达式的优化算法:
- 输入输出:
输入:一个关系表达式的查询树
输出:优化的查询树 - 方法:
1)运用选择的串接律,把选择条件拆开分别进行
2)选择尽可能靠近叶子端
遇到选择和投影直接下沉,遇到双目运算则考虑下沉到相关分支或不下沉
3)投影尽可能靠近叶子端
遇到选择若在投影属性范围内则直接下沉,否则在选择下增加新投影下沉(原投影不下沉)
遇到投影,合并
遇到双目运算,下沉到相关分支或不下沉
4)合并选择与投影操作
合成单个选择或单个投影(即同时执行,内容上可能无变化)、或一选择后跟一投影
5)把语法树的内结点分组
双目运算符与直接祖先为一组(祖先只能是选择和投影),若后代直到叶子全是单目,也并为一组
若双目运算是笛卡尔积,且后面不是选择,则应该把这些单目运算单独分组
优化过程要画的三种树:
- 三种树:原始语法树(sql语法树)-> 代数语法树 -> 优化后的代数语法树
- 转换过程:翻译sql为原始语法树 -> 将sql语法树拆成代数语法树 -> 对代数语法树进行优化
9.4物理优化
目的:选择高效合理的操作算法或存取路径,求得优化的查询计划
可用的方法:
- 基于规则的启发式优化
- 基于代价估算的优化
- 两者结合的优化方法
*基于启发式规则的存取路径选择优化
选择操作的启发式规则
- 小关系:全表扫描
- 大关系:
若选择条件是“主码=值”,则可以选择主码索引
若选择条件是“非主属性=值”,则根据查询结果的数目比例选择索引扫描还是全表扫描
连接操作的启发式规则
- 若两个表都已按照属性排序,则选用排序-合并算法
- 若表在连接属性上有索引,可以选用索引连接算法
- 若其中一个表较小,可以选用hash join算法
- 选用循环嵌套算法,选择小表作为外循环的表
*基于代价估算的优化
统计信息内容:每个基本表、基本表的每个列、索引等信息
代价估算:
- 全表扫描算法:
基本表大小是B块,全表扫描低价:
选择条件是“码=值”,平均搜索代价: - 索引扫描算法:
L层的B+树,选择条件是“码=值”:
L层的B+树,选择条件涉及非码属性:(有S个元组满足条件,这S个元组可能都在不同的块上,即最坏情况)
L层的B+树,选择条件是比较操作,假设有一般的元组满足条件:(Y是B+树叶子占用块数,B是基本表占用的块数) - 循环嵌套连接算法:
连接结果不写回磁盘:(Br为外表R的占用块数,Bs为内表S的占用块数,小表为外表所以有Br<Bs)
连接结果写回磁盘:(Frs为连接选择率,Nr为R表元组数,Ns为S表元组数,Mrs为每块存储的连接元组数) - 排序-合并连接算法:
已按连接属性排好序:
未按连接属性排好序:)(后半部分为对包含B个块的文件排序的代价)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律