数据库系统概论笔记(7)
第7章数据库设计
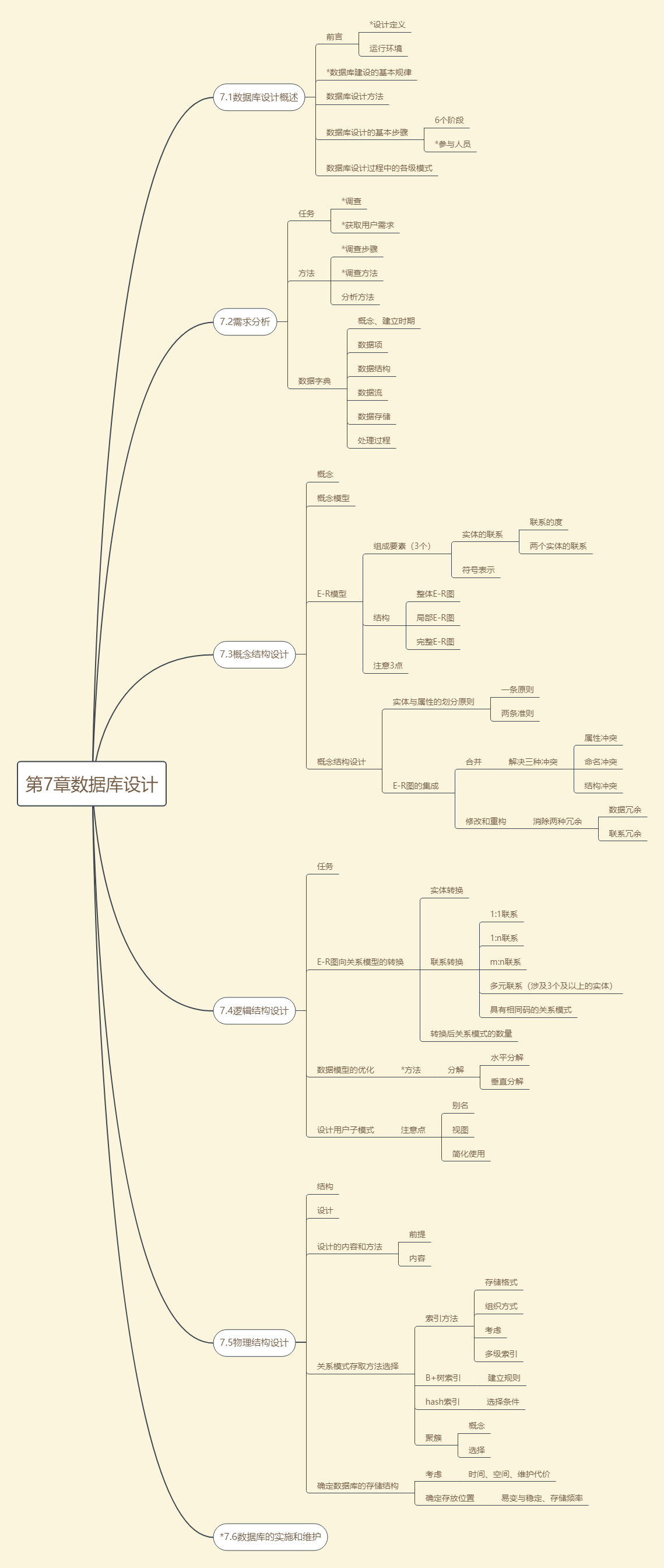
7.1数据库设计概述
数据库设计定义:对给定的应用环境,构造数据库逻辑模式和物理结构,要能满足信息管理和数据操作的要求
高效的运行环境:数据库数据的存取效率高、数据库存储空间的利用率高、数据库系统运行管理的效率高
数据库建设的基本规律
三分技术,七分管理,十二分基础数据
数据库设计方法
E-R模型设计方法
数据库设计的基本步骤
6个阶段:需求分析、概念结构设计、逻辑结构设计、物理结构设计、数据库实施、数据库运行和维护
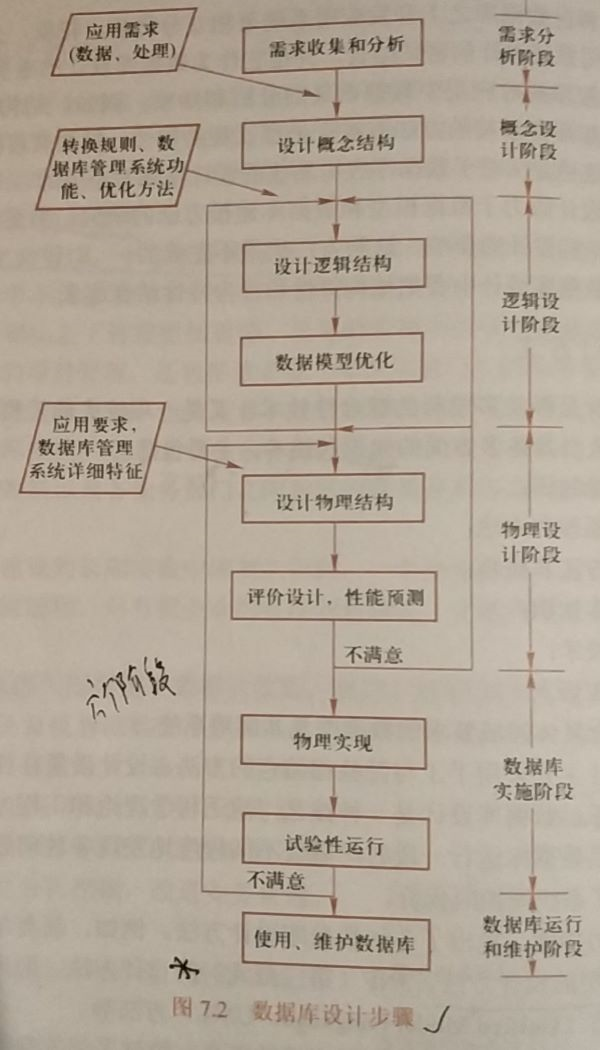
参与设计的人员:系统分析人员、数据库设计人员、应用开发人员、数据库管理人员、用户代表
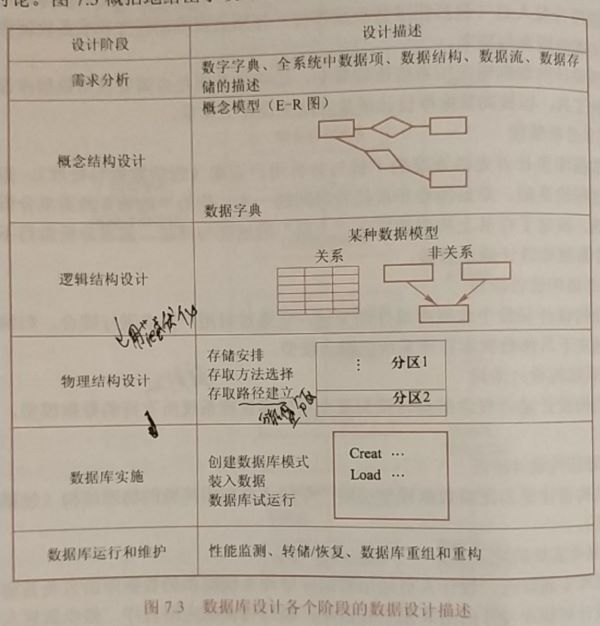
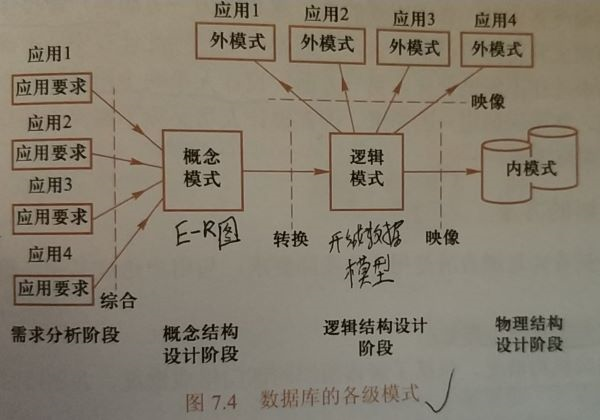
数据库设计过程中的各级模式
7.2需求分析
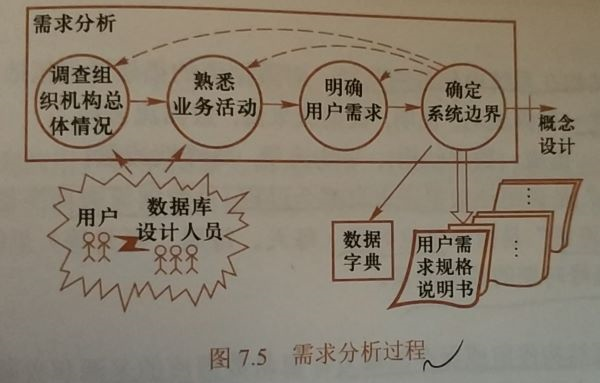
需求分析的任务
调查重点:数据和处理
获得用户对数据库的要求:
- 信息要求
- 处理要求
- 安全性与完整性要求
困难点:用户缺少计算机知识、设计人员缺少用户的专业知识
需求分析的方法
调查用户需求的具体步骤:
- 调查组织机构情况
- 调查各部门业务活动情况
- 协助用户明确对新系统的各种要求
- 确定新系统的边界
常用的调查方法:
- 跟班作业
- 开调查会
- 请专人介绍
- 询问
- 设计调查表请用户填写
- 查阅记录
分析方法:结构化分析方法(SA)是一种简单实用的方法
SA方法:从最上层的系统组织机构入手,采用自顶向下,逐层分解的方式分析系统
数据字典
数据字典概念:关于数据库中数据的描述,即元数据,不是数据本身
建立时期:在需求分析阶段建立,在数据库设计过程中不断修改、充实、完善
数据项:
- 概念:数据项是不可再分的数据单位
- 描述:数据项描述={数据项名,数据项含义说明,别名,数据类型,长度,取值范围,取值含义,与其他数据项的逻辑关系,数据项之间的联系}
“取值范围”、与其他数据项的逻辑关系“”定义了数据的完整性约束条件
数据结构:
- 概念:数据结构反映了数据之间的组合关系
- 描述:数据结构描述={数据结构名,含义说明,组成:{数据项或数据结构}}
数据流:
- 概念:数据流是数据结构在系统内传输的路径
- 描述:数据流描述={数据流名,说明,数据流来源,数据流去向,组成:{数据结构},平均流量,高峰期流量}
数据流来源:数据流来自哪个过程
数据流去向:数据流要去哪个过程
平均流量:单位时间里的传输次数
高峰期流量:高峰时期的数据流量
数据存储:
- 概念:数据结构停留或保存的地方
- 描述:数据存储描述={数据存储名,说明,编号,输入的数据流,输出的数据流,组成:{数据结构},数据量,存取频度,存取方式}
存储频度:每小时、每天或每周存取次数及每次存取的数据量等信息
存取方式:批处理/联机处理、检索/更新、顺序检索/随机检索
处理过程:
- 概念:描述处理过程的说明性信息(具体处理逻辑一般用判定树或判定表来描述)
- 描述:处理过程描述={处理过程名,说明,输入:{数据流},输出:{数据流},处理:{简要说明}}
注意点:
- 困难是收集将来应用所涉及的数据
- 必须强调用户的参与
7.3概念结构设计
概念:将需求分析得到的用户需求抽象为信息结构(概念模型)的过程
概念模型
主要特点:
- 能真实、充分地反映现实世界
- 易于理解
- 易于更改
- 易于向关系、网状、层次等各种数据模型转换
有力工具:E-R模型
E-R模型
E-R模型包括:实体、属性、实体之间的联系、关键字/码等
实体之间的联系
- 联系的度:参与联系的实体型数目(N个实体型之间的联系度为N,称为N元联系)
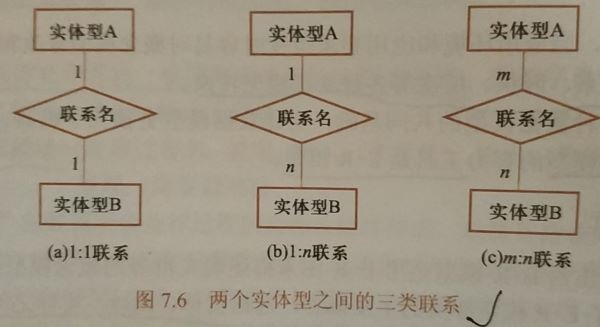
- 两个实体型之间的联系
三种:一对一联系(1:1)、一对多联系(1:n)、多对多联系(m:n)
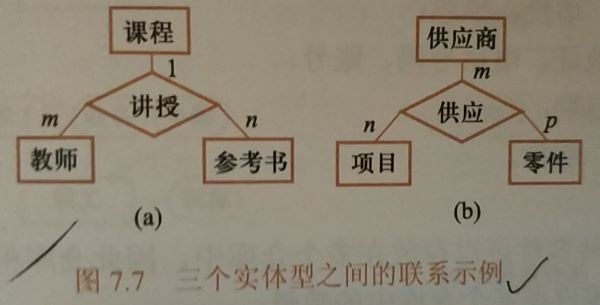
- 两个以上的实体型之间的联系
- 单个实体型内的联系

E-R图的表示符号
- 实体型用矩形表示
- 属性用椭圆形表示
- 联系用菱形表示
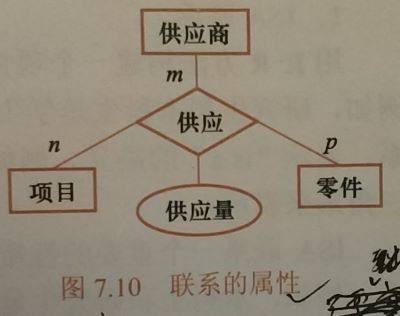
整体E-R图:只列出实体及其联系(包括联系的属性)
局部E-R图:只列出实体及其属性
完整E-R图:整体E-R图与局部E-R图合并
注意:
- 不能存在孤立的实体
- 两个实体不能通过属性来连接(也不能直接相连)
- 联系上的属性不能冗余(与其相连实体所拥有的属性重复)
概念结构设计
实体与属性的划分原则:
- 一条原则:现实的事物若能作为属性则尽量作为属性(简化E-R图)
- 可作为属性的两条准则:
1)作为属性,不能再具有需要描述的性质
2)属性不能与其他实体具有联系
E-R图的集成(两步):
- 合并:解决各分E-R图之间的冲突,将分E-R图合并起来生成初步E-R图
三类冲突:
1)属性冲突:包括属性域冲突、属性取值单位冲突
2)命名冲突:包括同名异义、异名同义
3)结构冲突:
3a:同一对象在不同应用中具有不同的抽象。解决:把属性变为实体(一般操作)或把实体变为属性,使同一对象具有相同的抽象
3b:同一实体在不同子系统的E-R图中所包含的属性个数和属性排列次序不完全相同。解决:使该实体的属性取各子系统的E-R图中属性的并集,再适当调整属性的次序
3c:实体间的联系在不同的E-R图中为不同的类型。解决:根据应用的语义对实体联系的类型进行综合或调整 - 修改和重构:消除不必要的冗余,设计基本E-R图
消除的两种冗余:
1)冗余的数据:可由基本数据导出的数据
2)冗余的联系:可由其他联系导出的联系
(注:非所有冗余都必须消除,有时候会以冗余为代价提高效率)
规范化理论消除冗余:
1)确定分E-R图实体之间的数据依赖
2)求的最小覆盖,和差集
(注:A:冗余的联系一定在D中,而D中的联系不一定是冗余的;B:当实体之间存在多种联系时,要将实体之间的联系在形式上加以区分;C:尽可能少用无属性的联系)

7.4逻辑结构设计
任务:把概念结构设计阶段的E-R图转换为逻辑结构(与选用DBMS产品所支持的数据模型相符合的逻辑结构)
E-R图向关系模型的转换
对于实体型:一个实体型转换为一个关系模式,关系的属性就是实体的属性,关系的码就是实体的码
对于实体型之间的联系(分情况):
- 1:1联系:转换为一个独立的关系模式,或与任意一端对应的关系模式合并
1)转为独立的关系模式:
属性:与该联系相连的各实体的码以及联系本身的属性
候选码:每个实体的码
2)与任一端对应的关系模式合并:
属性:加入另一关系模式的码和联系本身的属性
候选码:不变 - 1:n联系:转换为一个独立的关系模式,或与n端对应的关系模式合并
1)转为独立的关系模式:
属性:与该联系相连的各实体的码以及联系本身的属性
候选码:n端实体的码
2)与n端对应的关系模式合并:
属性:加入另一关系模式的码和联系本身的属性
候选码:不变 - m:n联系:转换为一个关系模式
属性:与该联系相连的各实体的码以及联系本身的属性
候选码:各实体码的组合 - 三个或三个以上的实体间的一个多元联系:转换为一个关系模式
属性:与该联系相连的各实体的码以及联系本身的属性
候选码:各实体码的组合 - 具有相同码的关系模式:合并关系模式
方法:将其中一个关系模式的全部属性加入到另一个关系模式中,去掉同义属性(可能同名或不同名),适当调整属性的次序
转换后关系模式的数量:
- 最小值:实体型数量+m:n联系数量
- 最大值:实体型数量+联系数量
数据模型的优化
数据库逻辑设计的结果不是唯一的
关系数据模型的优化方法:
- 确定数据依赖
- 对于每个关系模式之间的数据依赖进行极小化处理,消除冗余的联系
- 确定各关系模式分属第几范式
- 分析模式是否适合应用环境(确定是否要对某些模式进行合成或分解)
- 对关系模式进行必要分解,提高数据操作效率和存储空间利用率
两种分解方法:
水平分解:把基本关系的元组分为若干子集合,定义每个子集合为一个子关系,提高系统效率
垂直分解:把关系模式R的属性分解为若干子集合,形成若干子关系模式
设计用户子模式
定义用户外模式时注重的方面:
- 使用更符合用户习惯的别名
- 可以对不同级别的用户定义不同的视图,以保证系统的安全性
- 简化用户对系统的使用
7.5物理结构设计
物理结构:物理设备上的存储结构与存储方法称为数据库的物理结构
物理设计:为给定的逻辑数据模型选物理结构的过程
物理设计的两步:
- 确定数据库的物理结构
- 对物理结构进行评价
数据库物理设计的内容和方法
前提:了解产品提供的环境、知道DBMS的内部特征
关系数据库物理设计内容:主要包括关系模式选择存取方法、设计关系、索引等数据库文件的物理存储结构
关系模式存取方法选择
索引方法
索引的存储格式:索引字段+行指针
索引的存储:索引文件中的索引指向主文件中相应的数据
索引文件的两种组织方式:排序索引文件、散列索引文件
建立索引的考虑:访问时间、插入时间、删除时的时空负载等
多级索引:索引项上再建立索引
B+树索引存取方法的选择
一般建立规则:
- 经常在查询条件中出现的一个(组)属性
- 经常作为最大值和最小值等聚集函数的参数的属性
- 经常在连接操作的连接条件中出现的一个(组)属性
- 索引不是越多越好,系统维护索引要付出代价
hash索引存取方法的选择
选择条件:
- 一个关系的大小可预知,而且不变
- 关系的大小动态改变,但DBMS提供动态hash存取方法
聚簇存取方法的选择
聚簇:把在某些属性(聚簇码)上具有相同值的元组集中存放在连续的物理块中
关系:一个数据库可以有多个聚簇,一个关系只能有一个聚簇
建立聚簇的选择:
- 经常在一起进行连接操作的关系
- 经常出现在相等比较条件中的一组属性
- 值重复率很高的属性组
- 经常增删的少用聚簇
- 经常变长修改的少用聚簇
确定数据库的存储结构
考虑:存取时间、存储空间利用率、维护代价
- 确定数据的存放位置:
根据应用情况将数据的易变部分与稳定部分、经常存取部分和存取频率较低部分分开存放 - 确定系统配置
*7.6数据库的实施和维护
- 数据的载入和应用程序的调试
- 数据库的试运行
- 数据库的运行和维护


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律